什么是可解释人工智能:XAI
XAI 简介 — 旨在使机器学习模型为人类所理解的领域、

我们应该始终信任表现良好的模型吗?
模型可能会拒绝你的抵押贷款申请或诊断你患有癌症。这些决定会产生后果,严重的后果。即使它们是正确的,我们也希望得到解释。
人类可以给出一个答案。人类可以告诉你你的收入太低,或者一组细胞是恶性的。为了从模型中获得类似的解释,我们研究了可解释人工智能领域。
我们将探索这一领域并了解其目标。我们将在下面讨论 XAI 中的方法,重点讨论前两种方法。最后,我们将讨论从技术解释到人性化解释需要做些什么。
什么是XAI?
XAI,也称为可解释机器学习 (IML),旨在构建人类可以理解的机器学习模型。它是一个研究领域,也是该领域开发的一套现有工具和方法。这包括:
- 解释黑盒模型的方法
- 用于构建易于解释的模型的建模方法
我们可以将 XAI 视为解释模型和使模型更易于解释。向技术水平较低的受众解释预测也属于这一领域。这就是我们如何从数据科学家可以理解的解释转变为人性化的解释。因此,实际上,XAI 涉及用于理解或解释模型如何进行预测的任何方法。
XAI 旨在建立人类可以理解的模型
理解模型意味着理解单个预测是如何做出的。我们称之为局部解释。通过局部解释,我们想知道每个模型特征对预测的贡献。它还意味着理解整个模型是如何运作的。我们称之为全局解释。
为什么我们需要XAI?
显而易见的好处是 XAI 的目标——对模型的理解。通过局部解释,我们可以理解使用机器学习做出的个别决策,并向客户解释这些决策。通过全局解释,我们可以了解模型使用哪些趋势进行预测。由此,许多其他好处也随之而来。
它可以帮助提高人们对机器学习的信任度,并促进机器学习在其他领域的广泛应用。你还可以了解数据集并更好地讲述结果。你甚至可以提高生产中的准确性和性能。
机器学习模型非常复杂。那么,我们该如何理解它们呢?我们有几种方法。
内在可解释的模型
第一种方法是构建本质上可解释的模型。这些是简单的模型,人类无需其他方法就可以理解1。我们只需要查看模型的参数或模型摘要。这些将告诉我们如何进行单个预测,甚至模型捕捉到了哪些趋势。
可解释模型可以被人类理解,无需任何其他辅助/技术。
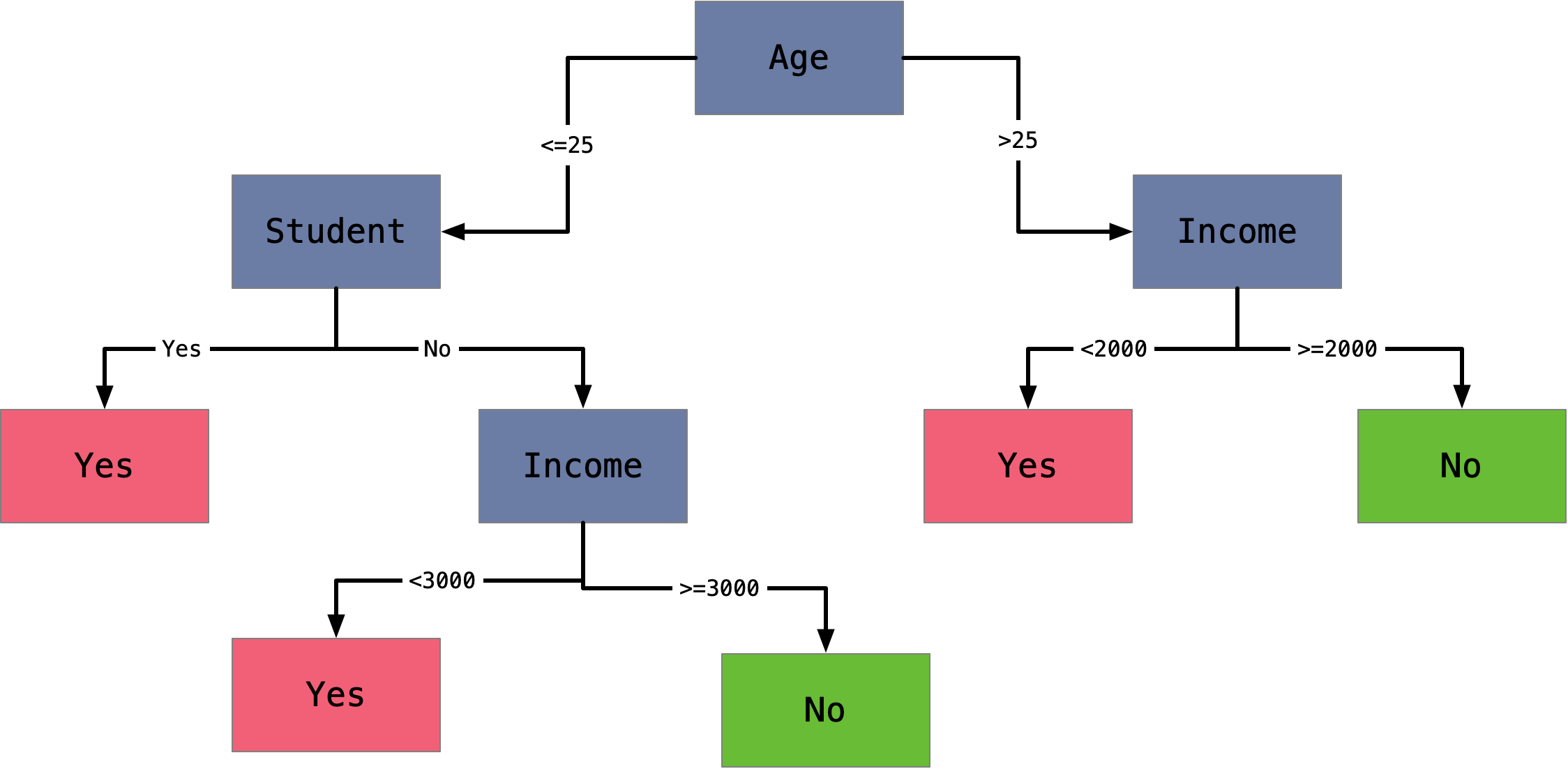
决策树是此类模型的一个很好的例子。参见图 1,假设我们想了解为什么我们向一名29岁、月收入3000 元的学生提供贷款。该人超过25 岁,所以我们从第一个节点直接进入。然后,她的收入≥2000 元,所以我们直接进入“No” 叶节点。因此,该模型预测该学生不会违约,自动承保系统会批准该贷款。
其他示例包括线性和逻辑回归。要了解这些模型的工作原理,我们可以查看赋予每个模型特征的参数值。参数特征值给出了该特征对预测的贡献。参数的符号和大小告诉我们特征与目标变量之间的关系。
使用这些模型会让我们远离机器学习。我们转向以更具统计性的思维方式构建模型。构建一个本质上可解释的模型需要更多的思考。我们需要花更多时间进行特征工程和选择——小组不相关的特征。这样做的好处是可以得到一个易于解释的简单模型。
黑盒模型
有些问题无法用简单的模型解决。对于图像识别等任务,我们转向不太可解释的模型或黑盒模型。我们可以在图 2 中看到一些例子。
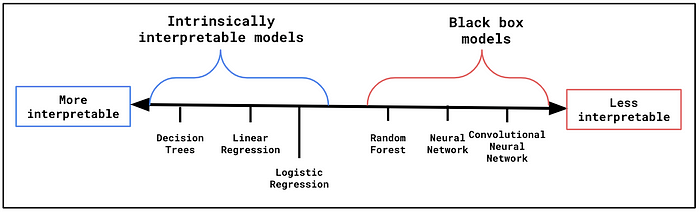
黑盒模型过于复杂,人类无法直接理解。要理解随机森林,我们需要同时理解所有决策树。同样,神经网络的参数太多,无法一次性理解。我们需要额外的方法来窥视黑盒。
模型无关方法
这给我们带来了模型无关方法。它们包括PDP、ICE 图、ALE 图、SHAP、LIME 和 Friedman 的 h 统计量等方法。这些方法可以解释任何模型。该算法实际上被视为一个黑匣子,可以替换为任何其他模型。这些可以根据它们旨在解释的内容和计算方式进行分类。
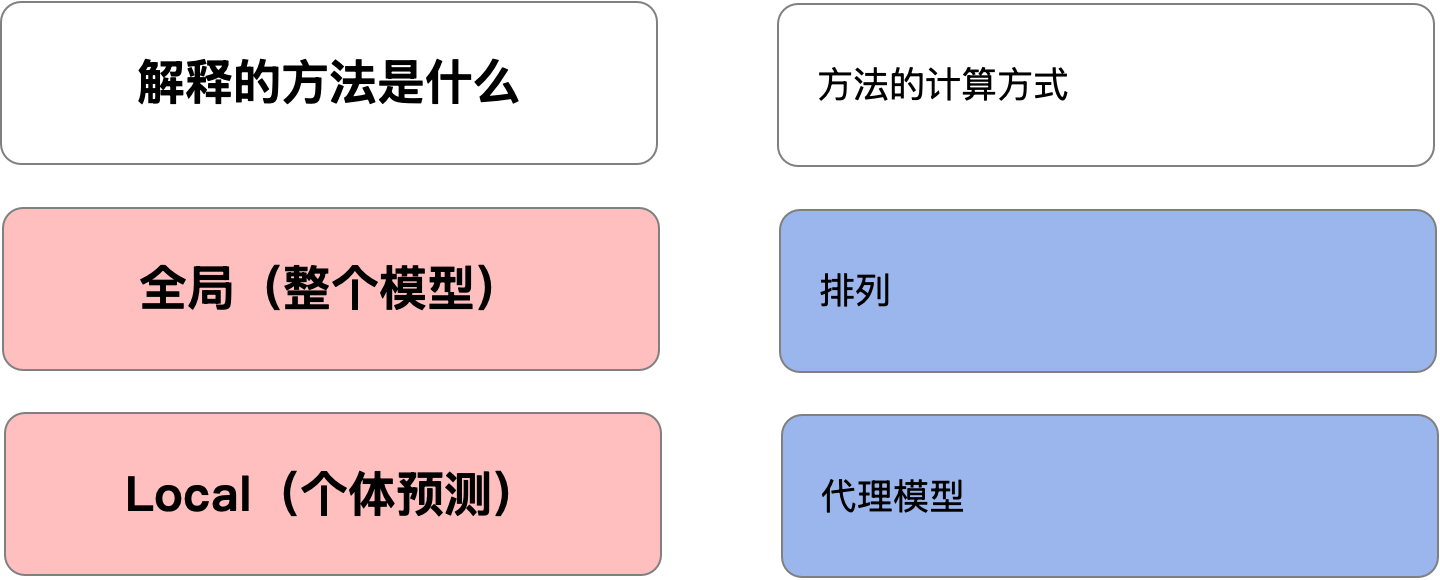
一种方法是使用替代模型。这些方法首先使用原始模型进行预测。然后我们在这些预测上训练另一个模型(即替代模型)。也就是说,我们使用原始模型的预测而不是目标变量。通过这种方式,替代模型可以学习原始模型使用哪些特征进行预测。替代模型必须是内在可解释的。这使我们能够通过直接查看替代模型来解释原始模型。
另一种方法是使用排列。这涉及改变/排列模型特征。我们使用模型对这些排列的特征进行预测。然后我们可以了解特征值的变化如何导致预测的变化。
置换法的一个很好的例子是PDP 和 ICE 图。你可以在图 3 中看到其中之一。具体来说,ICE 图由所有单独的线条给出。我们的数据集中的每个观察值都有一条线。为了创建每条线,我们置换一个特征的值并记录结果预测。我们在保持其他特征的值不变的情况下执行此操作。粗黄线是 PDP 。这是所有单独线条的平均值。
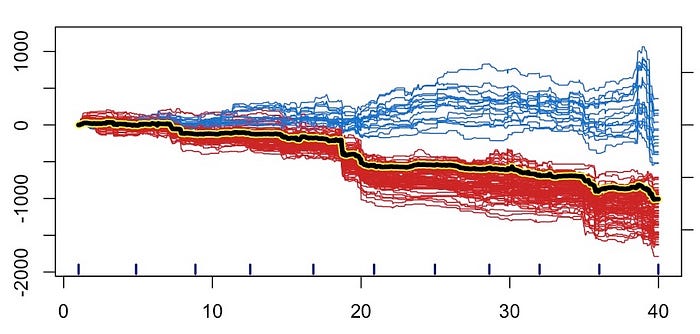
我们可以看到,平均而言,预测值随特征的增加而下降。查看 ICE 图,一些观察结果不符合这一趋势。这表明我们的数据中存在潜在的相互作用。PDP 和 ICE 图是全局解释方法的一个例子。我们可以用它们来了解模型捕获的趋势。它们不能用于了解单个预测是如何做出的。
Shapley 值可以。如图 4 所示,每个模型特征都有一个值。它们告诉我们与平均预测 E[f(x)] 相比,每个特征对预测f(x)的贡献如何。
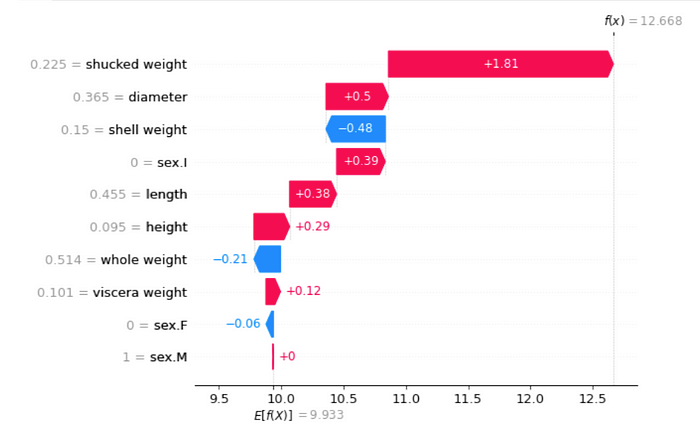
过去,人们使用置换来近似 Shapley 值。一种较新的方法SHAP显著提高了这些近似值的速度。它结合使用了置换和替代模型。对单个观察的特征值进行置换。然后根据这些值训练线性回归模型。该模型的权重给出了近似的 Shapley 值。
一般来说,这种方法被称为局部替代模型。我们根据个别预测的排列而不是所有预测来训练替代模型。LIME是另一种使用这种方法的方法。
附加 XAI 方法
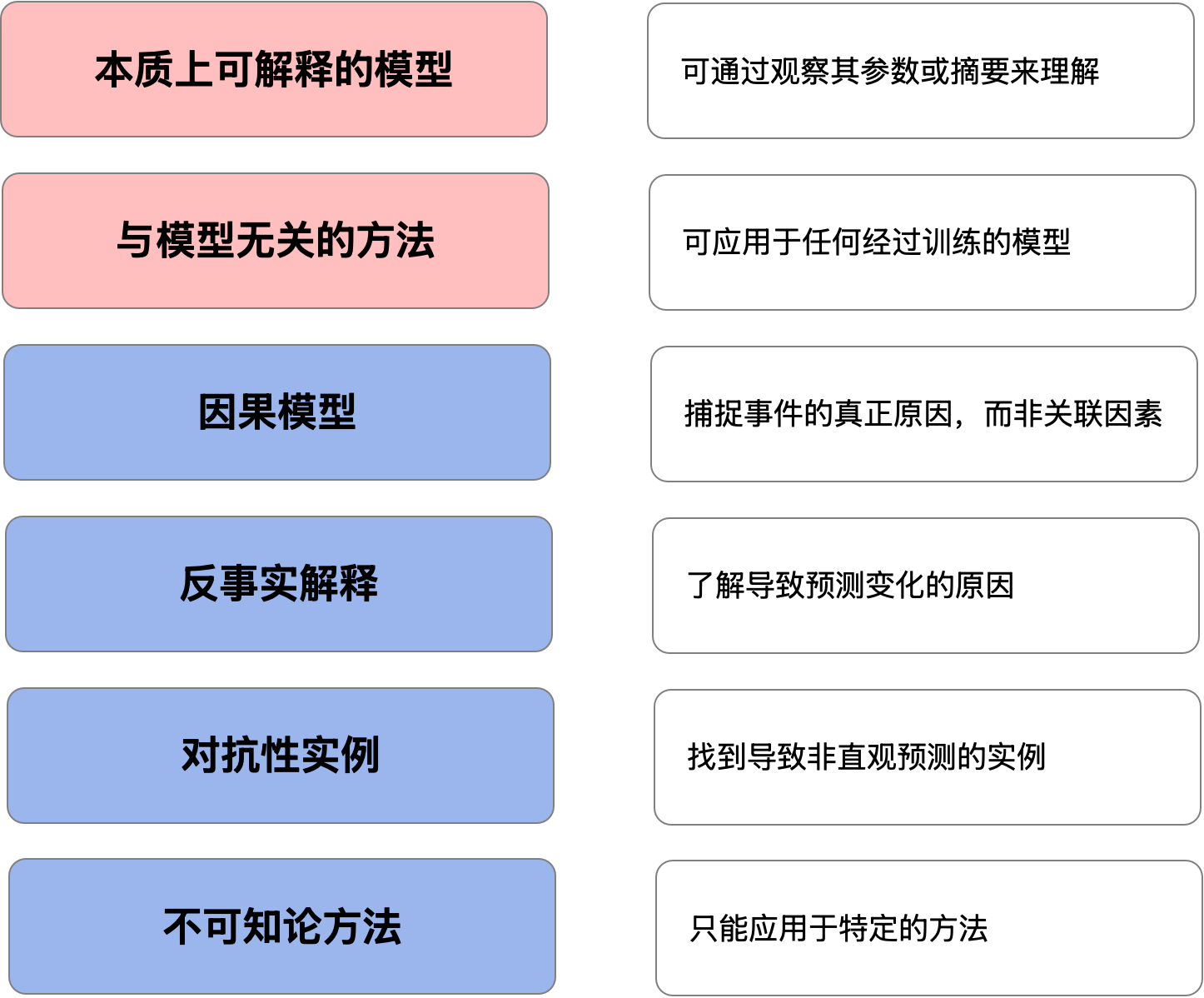
内在可解释模型和模型不可知论方法是 XAI 的主要方法。其他一些方法包括反事实 解释、 因果模型和对抗性示例。后两者实际上可以被视为自己的领域。但它们确实与 XAI 共享方法和目标。实际上,任何旨在了解模型如何进行预测的方法都属于 XAI。已经为特定模型开发了许多方法。我们称这些为非不可知论方法。
XAI 包括用于理解模型如何进行预测的任何方法
反事实解释
反事实解释可以被视为一种置换方法。它们依赖于特征值的置换。重要的是,它们专注于寻找改变预测的特征值。例如,我们想看看从负面诊断到正面诊断需要什么。
更具体地说,反事实解释是我们需要对特征值做出的最小更改,以改变预测。对于连续目标变量,更改将是预定义的百分比或数量。
反事实解释对于回答对比问题很有用。客户将他们目前的情况与潜在的未来情况进行比较的问题。例如,在贷款申请被拒绝后,他们可以问:
“我怎样才能被录取?”
通过反事实的解释,我们可以回答:
"你需要将每月收入增加 200 元" 或 "你需要将现有债务减少 1 万元"。
因果模型
机器学习只关心相关性。模型可以使用原籍国来预测患皮肤癌的几率。然而,真正的原因是每个国家的日照水平不同。我们将原籍国称为日照量的代表。
在构建因果模型时,我们的目标是仅使用因果关系。我们不想包含任何代表真正原因的模型特征。为此,我们需要依靠领域知识并在特征选择上投入更多精力。
建立因果模型并不意味着该模型更容易解释。它意味着任何解释都将符合现实。特征对预测的贡献将接近事件的真正原因。你给出的任何解释也将更有说服力。
为什么诊断我患有皮肤癌?
“因为你来自南非”,这并不是一个令人信服的理由。
对抗样本
对抗性样本是导致非直觉预测的观察结果。如果人类查看了这些数据,他们就会做出不同的预测。
寻找对抗性例子与反事实解释类似。不同之处在于我们想要改变特征值来故意欺骗模型。我们仍在尝试了解模型的工作原理,但不提供解释。我们希望找到模型中的弱点并避免对抗性攻击。
对抗样本在图像识别等应用中很常见。它可以创建在人类看来完全正常但会导致错误预测的图像。
例如,谷歌的研究人员展示了如何引入一层噪声来改变图像识别模型的预测。从图 5 可以看出,对于人类来说,噪声层甚至无法察觉。然而,该模型现在预测熊猫是长臂猿。

来源:I. Goodfellow 等人: https://arxiv.org/pdf/1412.6572.pdf
非不可知论方法
针对特定的黑盒模型,已经开发出了许多方法。对于基于树的方法,我们可以计算每个特征的分割次数。对于神经网络,我们有逐像素分解和 deepLIFT2等方法。
尽管 SHAP 被认为是模型不可知的,但它也有非不可知的近似方法。例如,TreeSHAP 只能用于基于树的方法,而 DeepSHAP 则可用于神经网络。
明显的缺点是非不可知论方法只能用于特定模型。这就是为什么研究一直针对不可知论方法。这让我们在算法选择方面拥有更大的灵活性。这也意味着我们的解释方法是面向未来的。它们可用于解释尚未开发的算法。
从解读到解释
我们讨论的方法都是技术性的。数据科学家使用它们向其他数据科学家解释模型。实际上,我们需要向非技术受众解释我们的模型。这包括同事、监管者或客户。为此,我们需要弥合技术解释和人性化解释之间的差距。
你需要:
- 根据观众的专业知识调整级别
- 思考要解释哪些特征
好的解释并不一定需要解释所有特征的贡献。
我曾在文章《解释预测的艺术》中更深入地讨论这个过程。作为示例,我们将介绍如何使用 SHAP 特征贡献来给出令人信服的解释。
XAI 是一个令人兴奋的领域。如果你想了解更多信息,请查看教程Python 中的 SHAP 简介、PDP 和 ICE 图的终极指南。
参考
Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead, 2019.↩︎
Deeplift, https://github.com/kundajelab/deeplift C. Molnar, Interpretable Machine Learning (2021), https://christophm.github.io/interpretable-ml-book/ S. Masís, Interpretable Machine Learning with Python (2021) Moraffah, R., Karami, M., Guo, R., Raglin, A. and Liu, H., 2020. Causal interpretability for machine learning-problems, methods and evaluation. https://arxiv.org/abs/2003.03934 Microsoft, Causality and Machine Learning, https://www.microsoft.com/en-us/research/group/causal-inference/↩︎
什么是可解释人工智能:XAI

