使用 Pandas 批量处理 22GB 交易数据
如何利用有限的计算资源来处理大型数据集
处理大型数据集很有挑战性。如果你没有必要的资源,处理起来就更具挑战性。我们大多数人无法使用分布式集群、GPU 机架或超过 8GB 的 RAM。这并不意味着我们不能处理一些大数据。我们只需要一次解决一个问题。也就是说,一次迭代整个数据集并处理子集。
数据集
我们将向你展示如何使用大型(随机生成的)交易数据集来实现这一点。该数据集包含 75,000 名客户的超过 2.6 亿笔交易。交易时间从 2010 年到 2020 年。每笔交易都分为 12 种支出类型之一(例如杂货)。你可以在图 1 中看到更多详细信息,还可以在GitHub1上找到本教程的代码。
我们将了解如何使用批处理来创建此数据的不同聚合。具体来说,我们将计算:
- 交易总数
- 每年总支出
- 2020 年平均每月娱乐支出
最后,我们将讨论加快创建这些聚合过程的方法。
批量处理
我们将使用一些标准的 Python 包。我们有 NumPy 和 Pandas 用于数据处理,还有 matplotlib 用于一些简单的可视化。请确保你已安装这些包。
1 | |
首先,让我们尝试使用 Pandas 加载整个数据集。过了一会儿,我们得到了图 2 中的错误消息。由于只有 8GB 的 RAM,因此无法将整个数据集加载到内存中。
1 | |
为了解决这个问题,我们可以加载数据集的子集。为此,我们可以使用read_csv函数中的skiprows和
nrows 参数。下面我们分别将参数的值设置为 1000 和
2000。这意味着我们将跳过 CSV 的前 1000 行并加载接下来的 2000
行。我们还需要将列名作为参数传递(第 7 行)。这是因为我们跳过了 CSV
中的第一行名称。
1 | |
我们可以使用这些参数来迭代我们的数据集。为此,我们创建了下面的get_rows函数。这可以使用它来返回我们数据集的子集。每个子集将包含由
step 参数确定的行数。count
参数会有所不同,以在每个步骤返回不同的子集。为了了解如何使用此功能,我们将计算数据集中的交易总数。
1 | |
计算交易次数
我们在 while 循环中使用get_rows函数。在循环的每次迭代结束时,我们将更新计数(第 19 行)。这意味着我们将加载数据集的新子集(第 12 行)。我们设置步数,以便每次返回 500 万行(第 1 行)。但是,数据集中的行数不是 500 万的倍数。这意味着最后一次迭代返回的行数少于 500 万行。我们可以使用它来结束 while 循环(第 21-22 行)。
1 | |
对于每次迭代,我们计算子集的长度并将其添加到交易总数中(第 15 行)。最后,我们输出有 261,969,720 笔交易。在很好地理解了如何批量处理数据集后,我们可以继续进行更复杂的聚合。
每年总支出
对于此聚合,我们希望将每年的所有交易金额相加。我们可以遵循与之前类似的过程。现在,对于每次迭代,我们都希望更新数据集中每年的总数。我们首先创建一个 pandas 系列,其中索引是年份,值是总支出金额(第 2 行)。我们从每年的总支出 0 开始。
对于每次迭代,我们按年份对支出金额求和(第 10 行)。结果是另一个系列
exp ,其索引与total_exp
相同。这使我们能够循环遍历每一年并更新总数(第 13-15 行)。
1 | |
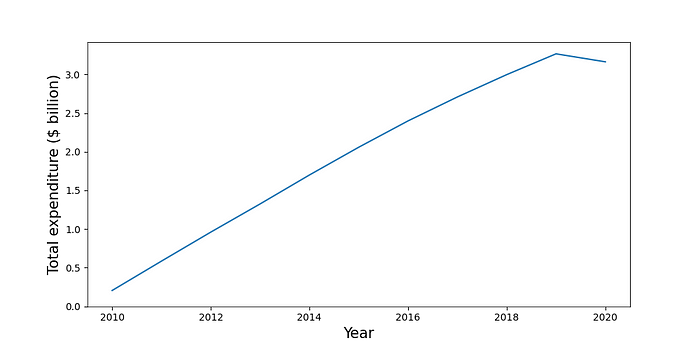
我们使用下面的代码可视化此聚合。你可以在图 3 中看到输出。除 2020 年外,总支出逐年稳步增长。对于此聚合,所有计算均在 while 循环中完成。正如我们将在下一个聚合中看到的那样,情况并非总是如此。
1 | |
2020 年平均每月娱乐支出
对于许多聚合,我们不会只是将总金额相加。对于此聚合,我们首先需要计算每个客户每月在娱乐上花费的总金额。然后,对于每个月,我们可以计算所有客户的平均值。首先,我们创建一个空的 pandas 数据框(第 2 行)。
然后,对于每次迭代,我们都会过滤掉交易,以便只保留 2020
年的娱乐交易(第 10 行)。然后,我们按客户和月份对金额求和(第 11
行),并将此表附加到 total_exp(第 14
行)。完成此操作后,可以重复客户和月份。这是因为不一定会在一次迭代中捕获所有客户的交易。这就是我们再次聚合表格的原因(第
17 行)。
1 | |
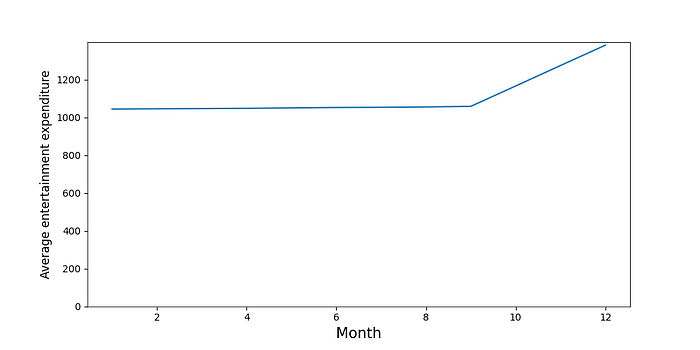
最后,我们将得到一个包含所有客户每月总额的表格。最后一步是计算每个月的平均金额(第 26 行)。你可以在图 4 中看到这些平均值。这里的平均值稳定,然后在 10 月、11 月和 12 月增加。
除了时间什么也没有
因此,即使资源有限,我们也要分析这个庞大的数据集。最大的问题是运行每个聚合所需的时间。在我的计算机上,每次聚合大约需要 5 个半小时!尽可能加快速度很重要。
耗时最多的部分是使用 get_rows
函数加载行。在这里,我们将硬盘上的 CSV 中的数据加载到内存/RAM
中。因此,你不应使用多个 while
循环,而应尝试在同一个循环内进行多次聚合。这样,我们只需要从磁盘读取一次数据。
希望这篇文章对你有所帮助!你还可以阅读我的其他文章,或者查看有关企业 AI 实战项目的教程,相信会让你拥有更多收获。
AI 进阶:企业项目实战[^3]
参考
C O’Sullivan, Simulated Transactions, CC0: Public Domain https://www.kaggle.com/datasets/conorsully1/simulated-transactions
「AI秘籍」系列课程:

Github, https://github.com/conorosully/medium-articles/blob/master/src/batch_processing.ipynb↩︎
使用 Pandas 批量处理 22GB 交易数据

