使用 Seaborn 热图的 5 种方法(Python 教程)
如何计算 SHAP 特征贡献的概述

热图可以让你的数据变得生动。用途广泛且引人注目。在很多情况下,它们可以突出显示数据中的重要关系。具体来说,我们将讨论如何使用它们来可视化: - 模型准确度的混淆矩阵 - 时间序列数据显示组间的变化 - 时间序列数据显示温度变化 - 相关矩阵 - 平均SHAP 相互作用值
在此过程中,你将学习自定义热图的不同方法。我们将讨论创建它们的代码,你可以在Github1找到完整的项目。
什么是热图?
我们先来讨论一下热图是什么以及为什么热图如此有用。你可以在图 1 中看到一个示例。y 轴上有变量 1。在这种情况下,变量 1 可以采用不同的 4 个值。也就是说,“V1-1”是变量 1 的第一个值。同样,y 轴上有变量 2。还有第三个变量。这是每个单元格内的值。每个单元格的颜色由这个变量的值决定。
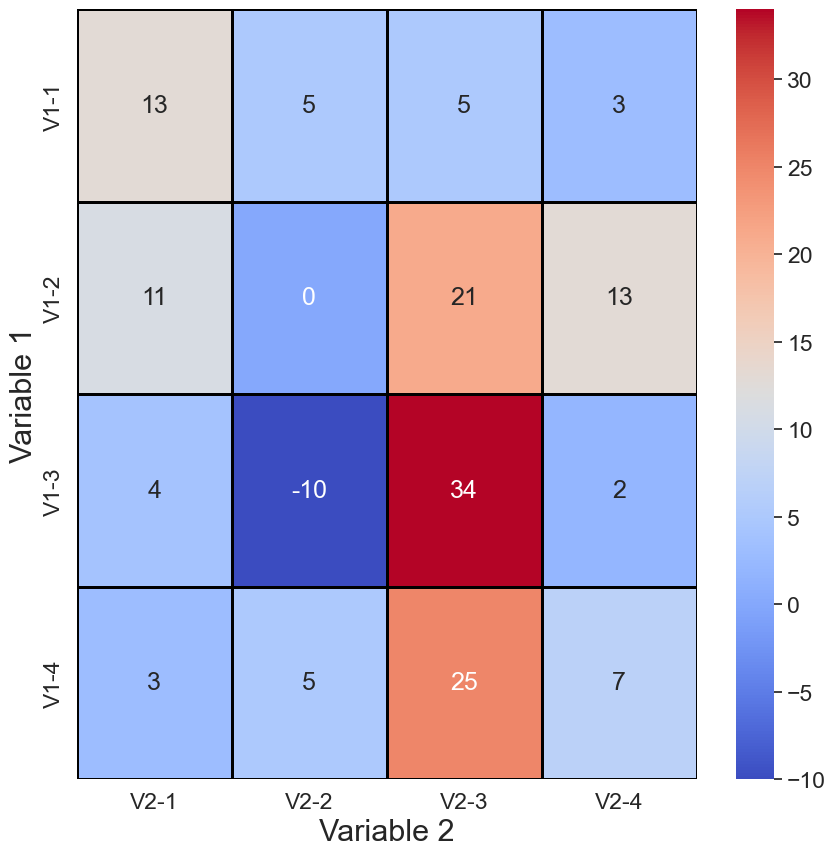
因此,使用热图,我们可以在 2D 平面上直观地显示 3 个变量之间的关系。这些关系可能很复杂。这就是使用颜色的原因。它可以突出显示关系的重要方面,并使它们更容易理解。
我们应该记住,热图仍然有局限性。变量 1 和变量 2 需要是离散的或分类的。或者,如果它们是连续的,我们需要能够将它们分组。另一方面,变量 3 需要是连续变量。希望当我们在下面讨论我们的 5 个热图时,这一点会很清楚。
1 混淆矩阵
图 2中的第一个热图是混淆矩阵的可视化。它来自用于预测一段文本语言的模型。y 轴表示文本的实际语言。x 轴表示模型预测的语言。对角线上的数字表示正确预测的数量。非对角线上的数字表示错误预测的数量。例如,英语 (eng) 被错误预测为德语 (deu) 11 次。
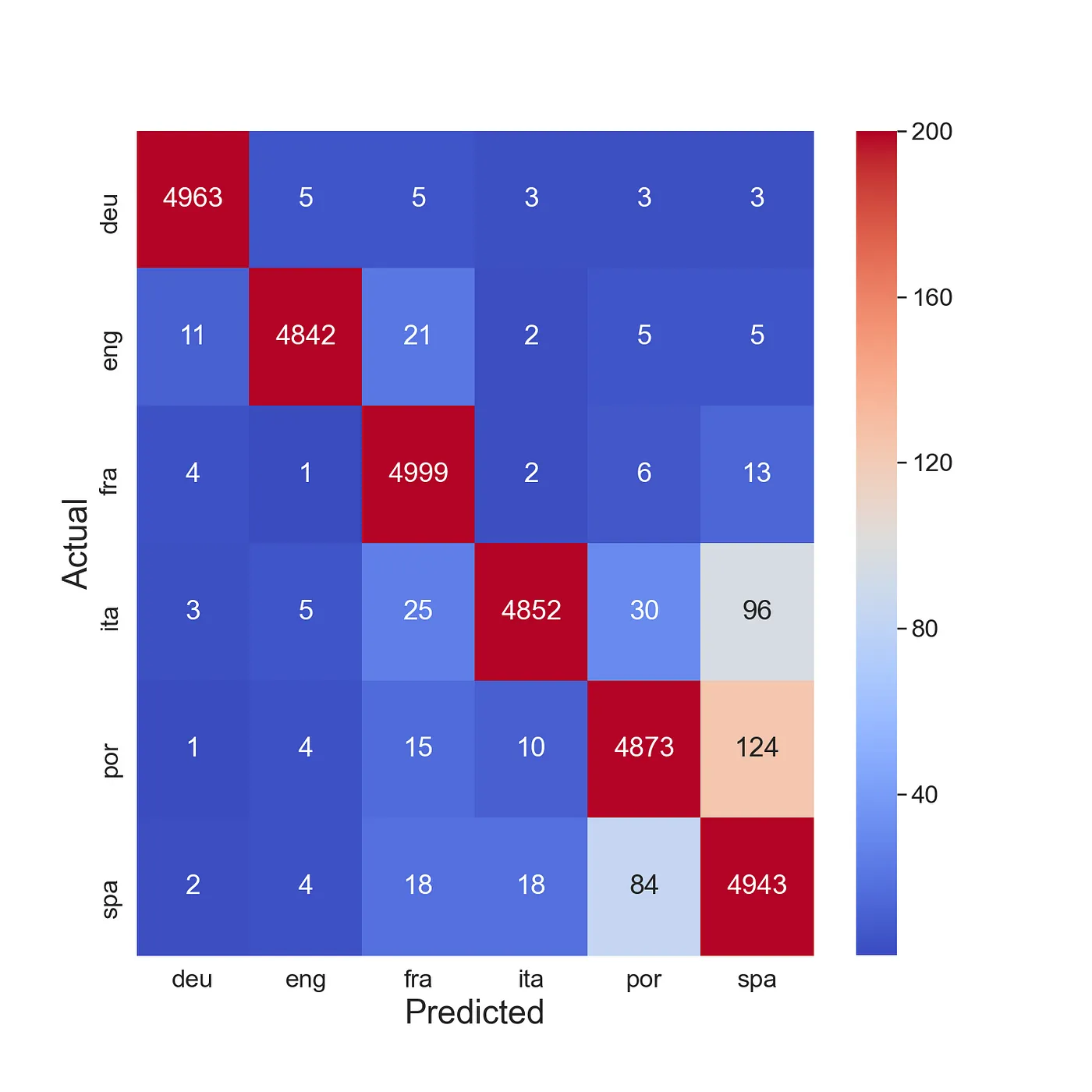
当你的目标变量有很多类别时,可视化这样的混淆矩阵很有用。它可以突出显示模型出错的地方。例如,我们发现模型最常将葡萄牙语(por)混淆为西班牙语(spa)(124 次)或将西班牙语混淆为葡萄牙语(84 次)。这是有道理的,因为在所有语言中,这两种语言在词汇上最相似。
热图代码
要创建此热图,我们首先导入以下包。热图函数来自 seaborn 包(第 6 行)。我们将对所有 5 个热图使用相同的包。确保已安装它们。
1 | |
我们有一个用于填充下面热图的二维数组。这些数组给出了正确和错误预测的数量。你可以看到第一个子数组(第 2 行)对应于图 2中热图第一行的值。所有热图都使用与此类似的二维数组填充。如果你需要将此代码用于另一个热图,则可以用你的二维数组替换此混淆矩阵。
1 | |
目前,我们已经对 2D 数组进行了硬编码。文章《[深度神经网络语言识别]》将带你了解我们实际获取这些数字的过程。总而言之,我们使用 NLP 技术构建了一个神经网络。然后,我们使用此模型来预测测试数据集中文本的语言。你在上面看到的数字来自这些预测。
深度神经网络语言识别
使用这个二维数组,我们创建一个 pandas DataFrame (
conf_matrix_df)。我们使用不同的语言作为列名和行名。
1 | |
最后,我们使用 seaborn heatmap 函数(第 5-9 行)可视化此
DataFrame。除了
conf_matrix_df,我们还传递了一些参数。cmap
提供配色方案。将其设置为 coolwarm
可获得红色和蓝色单元格。将annot 设置为 true
可获得每个单元格中的数字。如果没有它,我们将只有颜色。fmt
定义颜色的格式。在创建其他热图时,我们将看到这些参数的一些变化。
1 | |
最后一个参数是
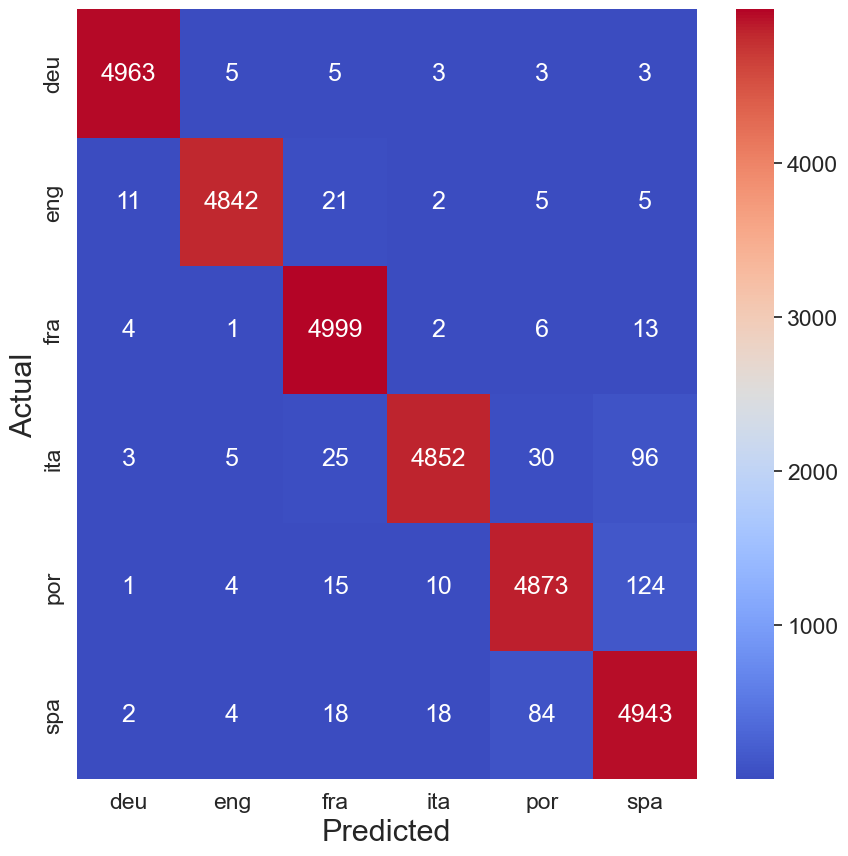
vmax。它定义了颜色标度的最大值。如果你不为该参数传递值,它将默认为热图中的最大值。在本例中,它是正确的法语
(fra) 预测的数量(即 4999)。我们将该值设置为
200,因为这样可以更容易区分错误的预测。你可以在图 3
中看到我们的意思。此热图是使用 vmax 的默认值创建的。
2 群体间流动
我们的第二张热图展示了如何可视化分类变量随时间的变化。具体来说,我们展示了美国城市的空气质量指数 (AQI)。y 轴表示 2010 年的 AQI 水平,x 轴表示 2016 年的水平。单元格值表示从一个级别升至另一个级别的城市数量。例如,我们可以看到 20 个城市从不健康(敏感人群)级别改善到了中等级别。
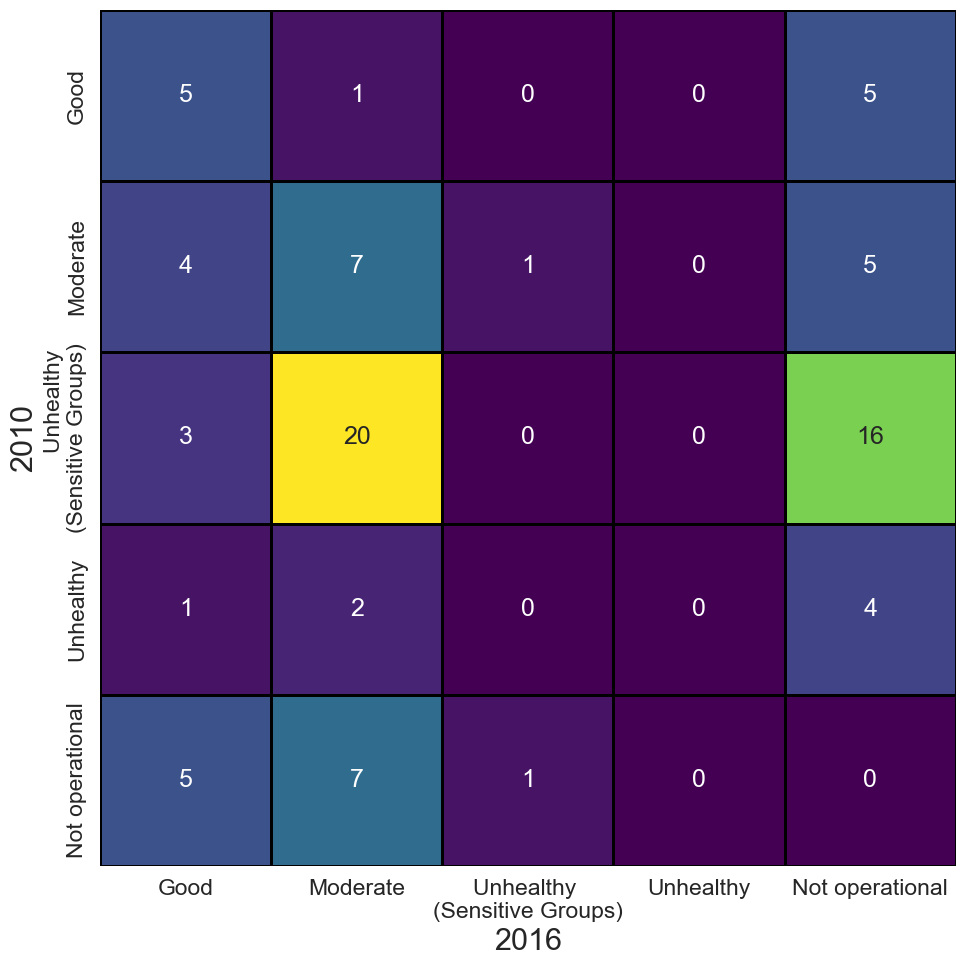
AQI 是介于 0 到 500 之间的值。值越高,空气污染程度越高。AQI 是使用 4 种不同的污染物计算得出的——二氧化氮 (NO2)、二氧化硫 (SO2)、一氧化碳 (CO) 和臭氧 (O3)。具体来说,为了得到最终的 AQI,我们取这 4 种污染物中的最大 AQI。在图 5中,你可以看到不同关注级别的 AQI 范围。我们在热图中使用了这些级别。
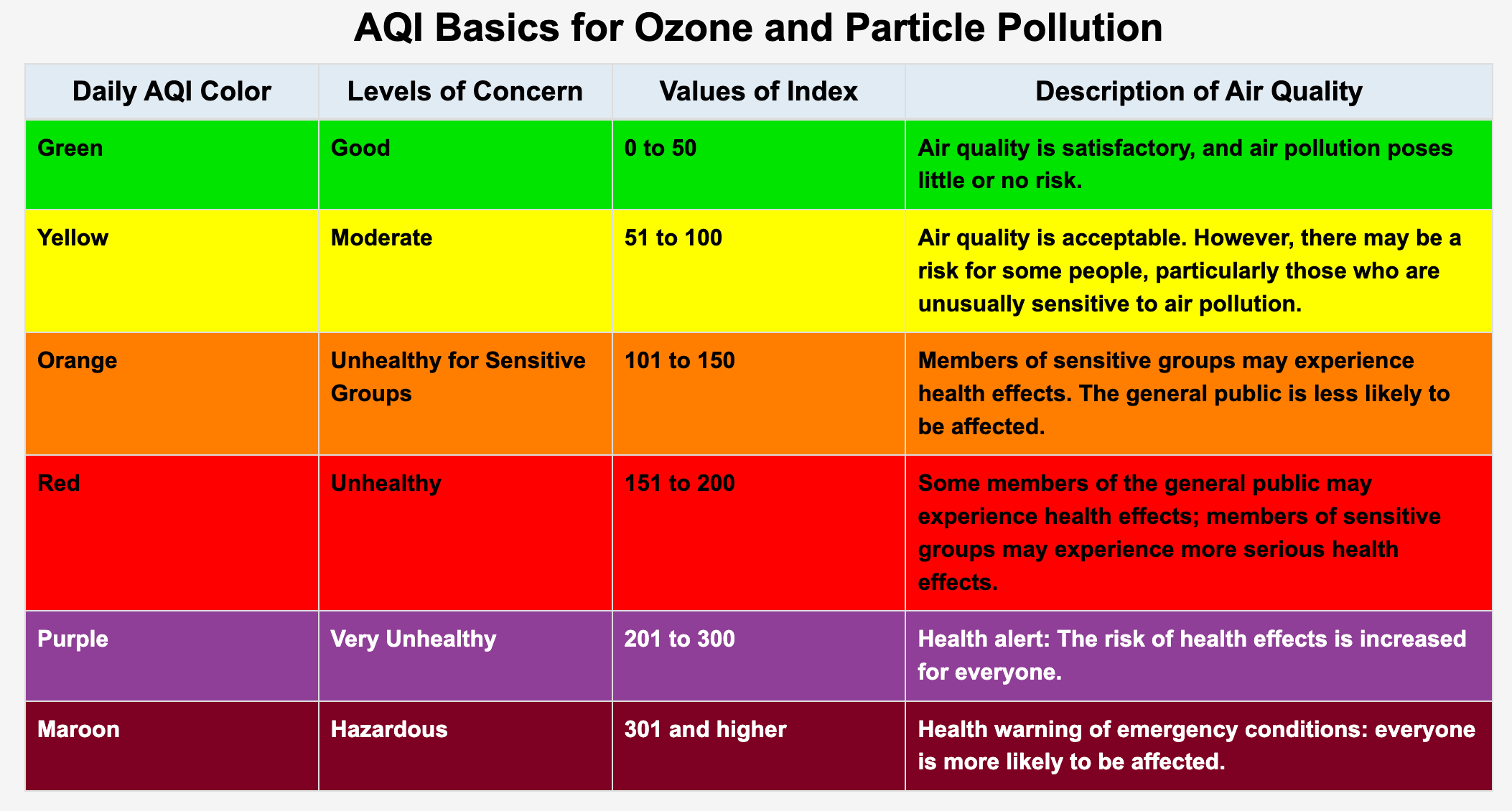
来源:[AirNow: https://www.airnow.gov/aqi/aqi-basics/]
要创建热图,我们首先加载数据集(第 2 行)。你可以在 Kaggle2 上找到此数据集。阅读是按天进行的。我们只对阅读的年份感兴趣。因此,我们创建了一个包含阅读年份的列(第 5-6 行)。
1 | |
这是 x 轴和 y
轴上的变量原本是连续变量的示例。如前所述,我们需要对该变量进行分组。下面的
aqiGroup 函数用于执行此操作。它将根据 AQI
值返回一个级别。它使用的范围与图 5 中相同。
1 | |
为了得到最终的 2D 矩阵,我们需要进行一些数据处理。我们首先使用 4
种污染物的值计算 AQI 值(第 2
行)。然后,对于每个城市,我们计算每年的最大 AQI(第 5
行)。因此,你在热图中看到的值实际上是基于 2010 年和 2016 年的最大 AQI
值。最后,我们使用 aqiGroup 函数对 AQI 值进行分组(第 8
行)。
1 | |
我们获取了 2016 年(第 2-3 行)和 2010 年(第 6-7 行)的所有 AQI
值。然后,我们将这些表格合并起来(第 10
行)。在某些情况下,一个城市可能在某一年有读数,而在另一年没有。在这种情况下,我们将缺失值替换为
Not operational(第 11 行)。最终数据集AQI将包含每个城市在
2016 年和 2010 年的水平。
1 | |
好的,现在我们有了这个数据集,我们可以使用它来创建 2D 数组
hm_array。这用于填充热图。它将具有与我们在第一个热图中看到的硬编码数组相同的结构。该数组是在第
6 行到第 12 行中创建的。其中,对于每个级别组合,我们计算 AQI
数据集中的记录数(第 10-11 行)。和以前一样,我们使用这个 2D
数组创建一个 dataFrame。我们使用 AQI 级别作为列名和行名。
1 | |
最后,我们像以前一样创建热图。这次我们有不同的参数值。我们使用了不同的配色方案
cmap 。我们将 cbar 设置为
false。这会隐藏颜色条。我们还使用了 linewidths 和
linecolor 参数为热图提供黑色网格线。
1 | |
3 温度随时间变化
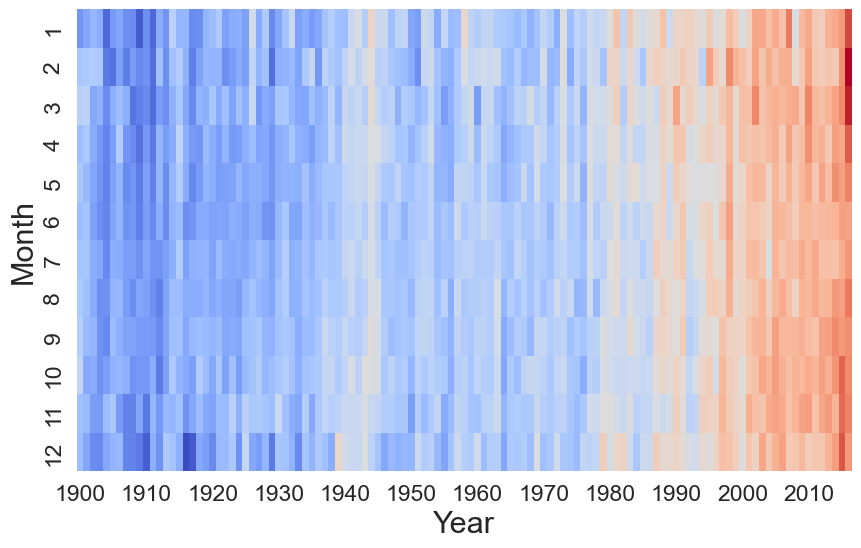
与上一张热图类似,我们用这张热图来可视化时间序列数据。只不过,现在我们展示的是连续变量随时间的变化。在图 4 中,你可以看到全球平均气温随时间的变化。从 1900 年到 2016 年,每个月都有读数。你可以清楚地看到气候变化对后续月份的影响。也许我们对热图一词的理解有点过于字面化了。
我们首先加载数据集(第 1 行)。你可以在 datahub3 上找到它。数据集包含两个不同的温度读数来源。我们仅选择 GISTEMP 读数(第 4 行)。然后,我们为每个读数创建年份和月份的列(第 7-9 行)。
1 | |
和之前一样,我们创建一个用于填充热图的 2D 数组。在之前的热图中,所有 2D 数组都是对称的。但情况并不总是如此。对于此热图,每个月都有一个子数组(即 1 到 12)。每个子数组都将包含 1900 年至 2016 年每年的温度值。因此,我们现在有一个 12x117 数组。我们使用年份作为列名、月份作为行名来创建一个 DataFrame。
1 | |
我们像之前一样可视化这个 DataFrame。最大的区别是我们将 x ticklabels 参数设置为 10。这意味着只显示 x 轴上的每 10 个标签。你可以在图 6中看到这一点,其中只显示了 1900、1910、1920 等标签。
1 | |
4 相关矩阵
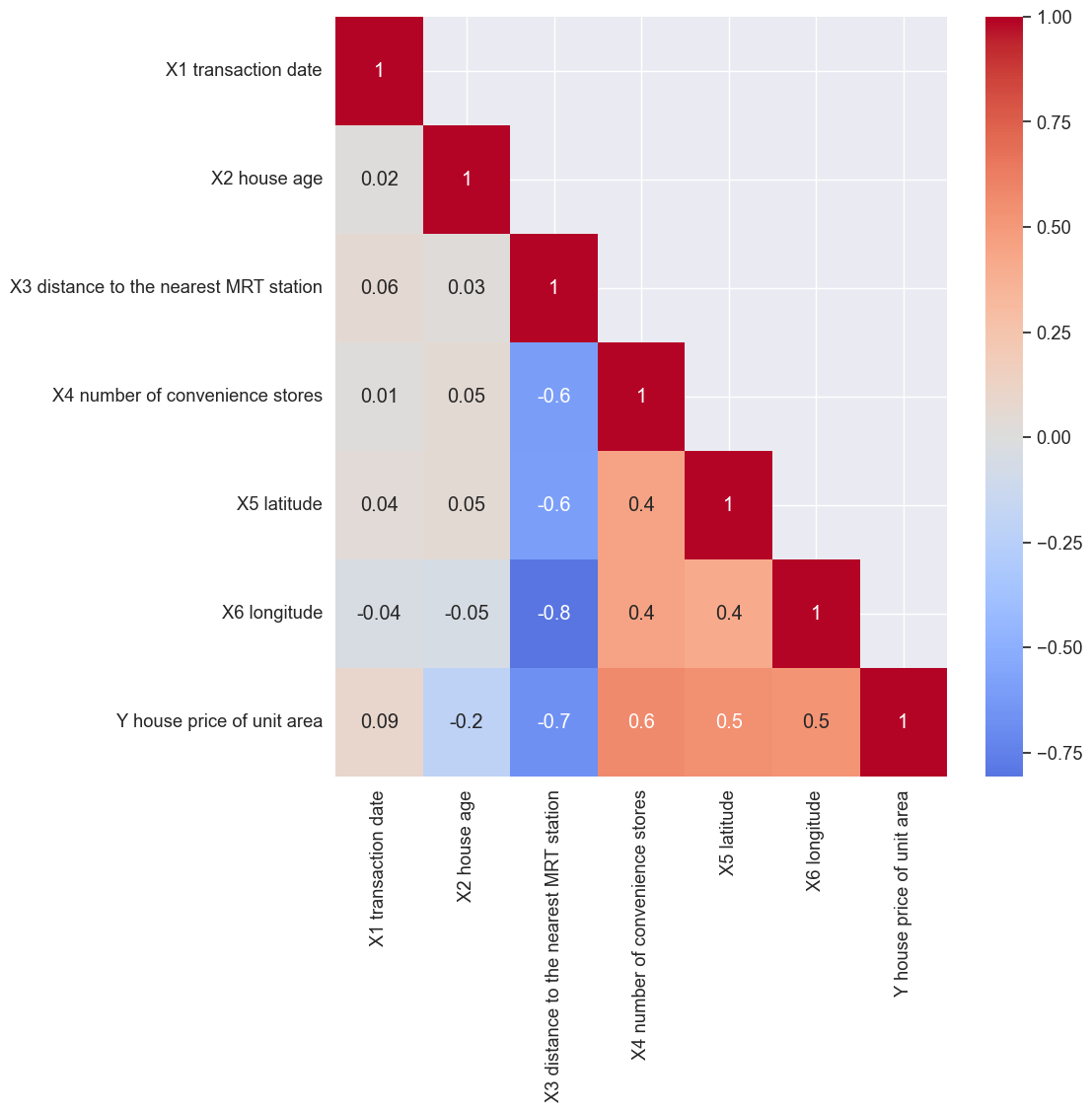
我们的第四张热图可能是你以前见过的。它的一个常见用途是可视化数据集中的相关性。例如,我们在图 7中有一个房价数据集的相关矩阵。我们可以使用它来识别可能导致模型出现问题的任何多重共线性。例如,X3 和 X4 呈负相关。最后一行还给出了与目标变量 Y 的相关性。我们可以使用它来了解任何特征是否与 Y 有显著关系。
要创建此热图,我们首先加载数据集(第 2 行)。你可以在 UCI 的 机器学习存储库4 中找到它。然后,我们使用此数据集创建一个相关矩阵(第 5 行)。结果将是一个 pandas DataFrame。列和行名称将与数据集中特征的名称相同。
1 | |
你可能已经注意到,在图 7中,对角线上方的单元格是空白的。为此,我们首先需要创建一个掩码。这是一个 2D 数组,类似于我们用来填充以前的热图的数组。对于要显示的单元格,数组的值应该是“True”。否则,对于空白单元格,它们应该是“False”。我们使用下面的代码来创建掩码。
1 | |
最后,我们可以显示热图。唯一的区别是我们需要将掩码作为参数传递(第 8 行)。
1 | |
5 SHAP相互作用值
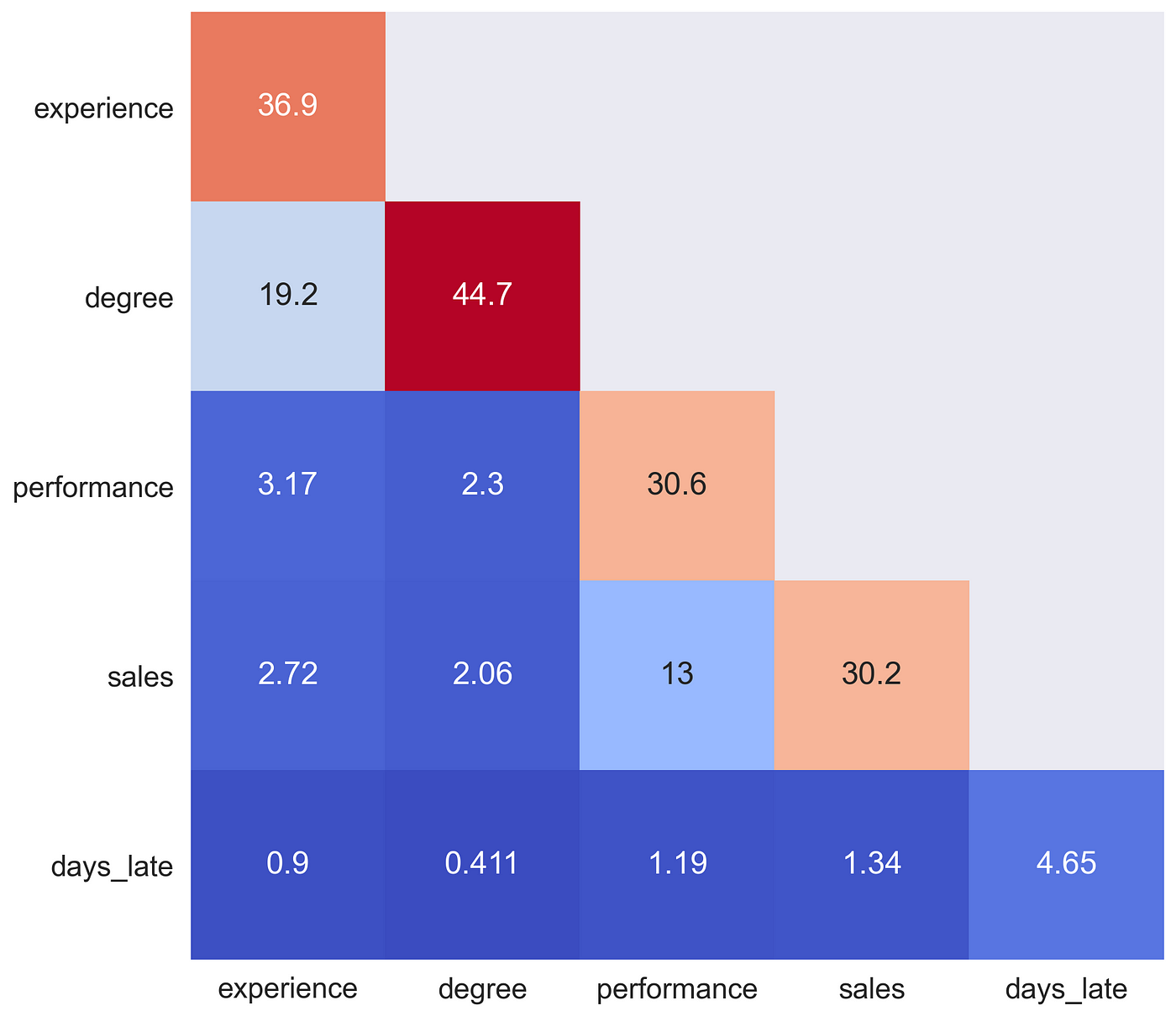
我们最后的热图可用于突出显示对模型预测很重要的特征。它是通过取平均 SHAP 交互值创建的。它显示了对角线上的平均主效应。例如,我们可以看到,经验、学位、绩效和销售额的主效应很大。同样,平均交互效应在非对角线上。我们可以看到,经验.学位和绩效.销售额的交互效应很显著。
我们不会介绍用于创建此热图的代码。如果你有兴趣,可以在文章《[[分析与 SHAP 的相互作用]]》中找到它。我们深入探讨了 SHAP 交互值。我们还使用这些值创建和解释其他图。这些用于解释你的机器学习模型。
希望这篇文章对你有所帮助!你还可以阅读我的其他文章,或者查看有关企业 AI 实战项目的教程,相信会让你拥有更多收获。
「AI秘籍」系列课程: 人工智能应用数学基础

参考
Github, https://github.com/hivandu/public_articles/tree/main/src/seaborn_heatmap.ipynb↩︎
Kaggle, U.S. Pollution Data, https://www.kaggle.com/datasets/sogun3/uspollution, Licence: Open Database License (ODbL) 1.0↩︎
Datahub, Global Temperature Time Series, https://datahub.io/core/global-temp, Licence: ODC-PDDL-1.0↩︎
机器学习存储库, Real estate valuation data set Data Set, http://archive.ics.uci.edu/ml/datasets/Real+estate+valuation+data+set, Licence: CC0: Public Domain↩︎
使用 Seaborn 热图的 5 种方法(Python 教程)

