良好功能的特征
为什么选择模型特征时预测能力并不是最重要的
可直接在橱窗里购买,或者到文末领取优惠后购买:
在保险业中,过去的索赔行为对未来的索赔行为具有很强的预测性。它可能是用于确定客户是否会提出索赔的唯一最具预测性的信息来源。但是,如果我们仅使用索赔历史来构建模型,它就不会很好。一般来说,模型特征应该来自各种不同的信息源。你的特征选择方法应该旨在从每个不同的信息源中创建最具预测性的特征的候选名单。
在本文中,我们将解释如何使用变量聚类和特征重要性的组合来创建这样的候选列表。我们还讨论了可能导致添加或删除特征的其他考虑因素。这些因素包括数据质量和可用性、特征稳定性、可解释性和法律/道德。最后,我们将讨论如何在特征选择框架中整合所有这些考虑因素。让我们首先准确定义特征选择的含义。
什么是特征选择?
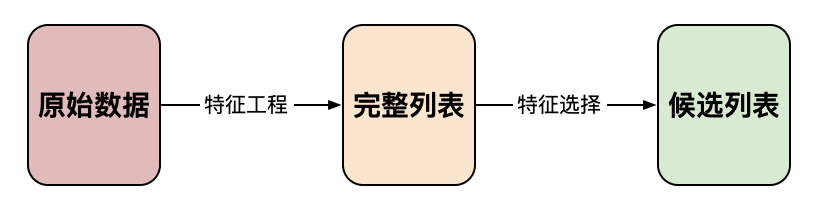
在模型开发过程中,特征选择发生在特征工程之后、开始拟合模型之前。在特征工程期间,我们将原始数据转换为模型特征列表。根据你的问题,此列表可能很大(即超过 1000 个特征)。特征选择涉及将其缩小到一个候选列表(即 20-40 个特征)。根据你的模型,可能还有另一个特征选择阶段,你将在此选择模型特征的最终列表(即 8-10 个特征)。在本文中,我们重点介绍第一阶段 — 创建候选列表。
我们出于一些原因创建了一个候选名单。在模型训练阶段,使用完整的特征列表在计算上是昂贵的。甚至在开始训练模型之前,我们就会想要探索这些特征以了解它们与目标变量的关系。测试这些特征也需要大量工作。没有必要对所有特征都进行这项工作。这是因为完整列表将包含冗余/不相关的特征。
冗余功能
为了更好地理解这一点,假设你想要创建一个模型来预测某人是否会拖欠汽车贷款。假设对于每个客户,我们都可以访问有关月收入、违约和欠款历史、现有债务义务和一些个人信息的数据。在特征工程期间,你将使用不同时间段的不同聚合从每个来源创建许多特征。在图 2 中,你可以看到一些示例。
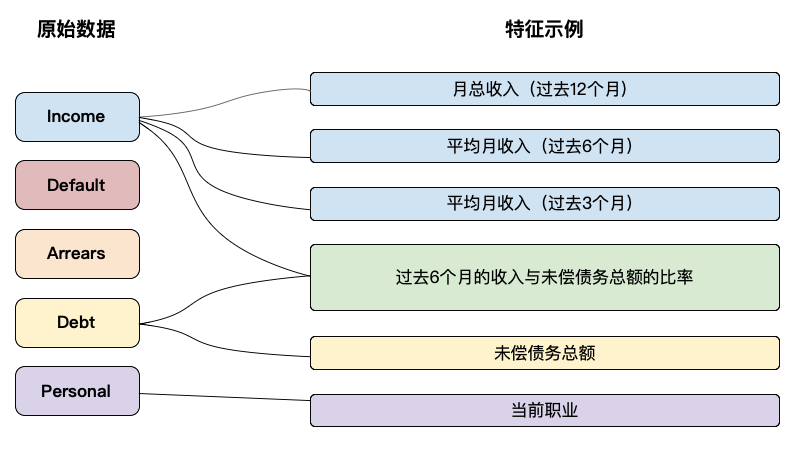
对于收入,我们预计上述 3 个特征非常相似。我们也可以预期它们可以预测违约。但是,它们都会捕捉到收入和违约之间相同的潜在关系。这意味着,一旦我们的模型中有了一个收入特征,再增加一个特征并不会提高模型的准确性。我们说其余的收入特征是多余的。我们希望将多余的特征从我们的候选名单中排除,即使它们具有预测性。
不相关的特征
我们还希望删除任何不具有预测性或由于其他原因不应考虑的特征(例如,在模型中使用该特征是非法的)。这些被称为不相关特征。例如,假设我们使用客户 20 年前的收入创建了一个特征。这些信息已经过时,不会告诉我们有关他们当前财务状况的任何信息。换句话说,这个特征不会帮助我们预测客户是否会拖欠汽车贷款。
特征选择的目标是通过删除尽可能多的冗余和不相关的特征来缩小列表。为此,我们需要考虑各个特征的预测能力以及特征之间的差异(即预测变量多样性)。这些是主要考虑因素,我们将在下面深入讨论它们。
预测能力

我们可以大致将预测能力定义为特征预测目标变量的能力。实际上,我们需要使用一些度量/统计数据来估计这一点。一个常见的度量是特征与目标变量之间的相关性。较大的正相关或负相关表示存在很强的关系,换句话说,该特征具有预测性。其他度量包括信息值、互信息和特征重要性分数。
不同的衡量标准各有优缺点。重要的是,它们允许我们比较特征并优先考虑那些最具预测性的特征。但是,如果这是我们唯一考虑的事情,我们可能不会得到一个很好的候选名单。继续我们的汽车贷款示例,假设我们已经创建了表 1 中的特征列表。这是我们的完整特征列表,我们已根据特征重要性对它们进行了排序。
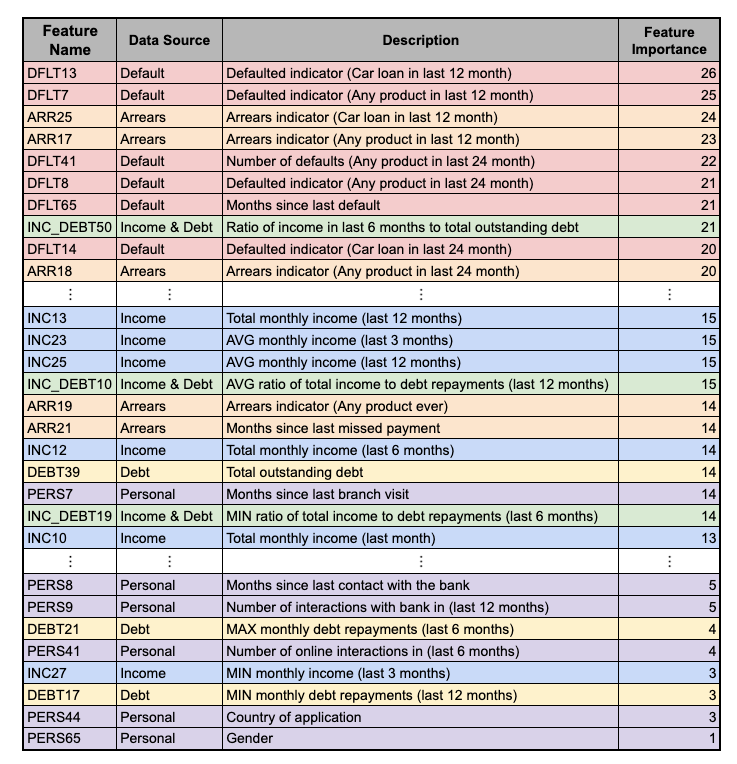
总体而言,我们可以看到基于违约历史的特征最具预测性。这是因为客户过去的违约历史将告诉我们很多有关他们将来是否会违约的信息。因此,假设我们只将 20 个最具预测性的特征作为最终候选名单。我们最终会得到许多违约特征。换句话说,候选名单中会有许多冗余特征。
预测变量
这个问题引出了我们应该考虑的第二个因素——预测变量的多样性。为了避免出现过多的冗余特征,我们需要考虑这些特征之间的差异。为此,我们应该首先从完整列表中创建特征组。这些组的构建方式应使组内的特征彼此相似,而与其他组中的特征不同。现在,如果我们从每个组/子列表中提取最具预测性的特征,我们最终会得到更少的冗余特征。
变量聚类
问题是我们如何创建这些特征组。我们可以使用领域知识手动完成,或者可能已经存在固有的分组。对于我们的汽车贷款示例,我们可以创建 6 个组(5 个主要数据源和 1 个收入和债务组合)。例如,你可以在图 4 中看到违约和收入组。在这两个组中,特征都按特征重要性排序。然后,我们可以从每个组中选取 3/4 个最具预测性的特征,从而为我们提供 18 到 24 个特征的候选名单。
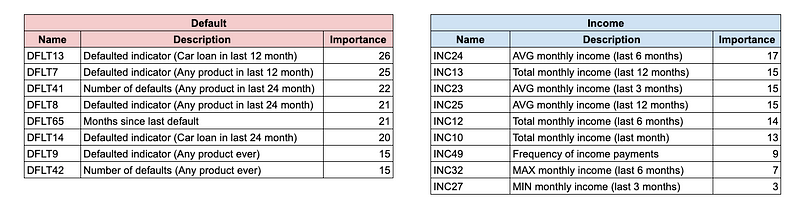
对于许多问题,手动对特征进行分组可能很困难。你可能有太多特征无法手动分组。底层数据源也可能更复杂。即使对于我们的汽车贷款示例,也不清楚 6 个组是否是最佳分组。例如,个人组中的特征之一是“当前职业”。最好将其与收入特征一起包含在内。
为了解决这些问题,我们需要一种统计方法来创建相似的组。这些方法称为变量聚类方法。例如,你可以使用Python 中的 VarClusHi1 包。此方法旨在对高度相关的变量进行分组。组内的变量应该高度相关,同时不与其他组中的变量相关。你还可以重新设计 K-means 等聚类方法,使它们对变量而不是观测值进行聚类。
其他特征和注意事项
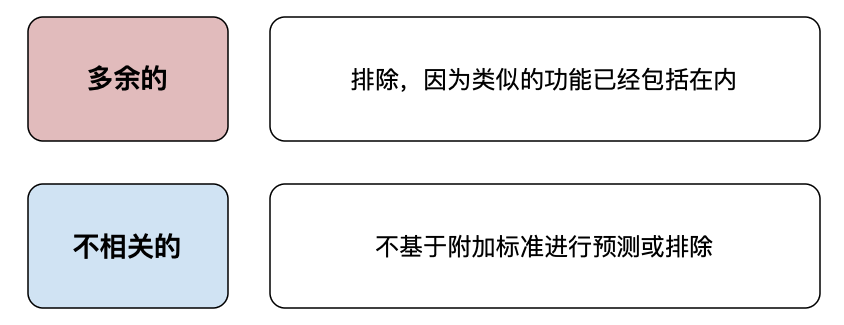
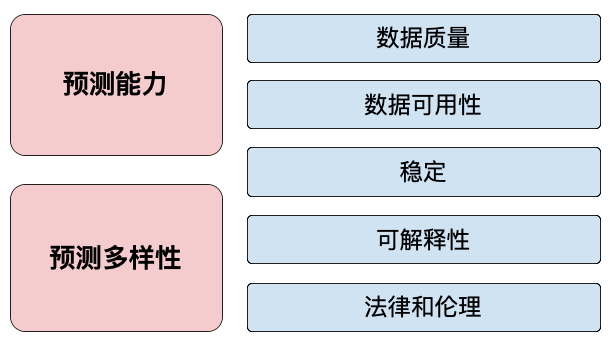
使用变量聚类将帮助我们删除冗余特征。使用特征重要性将帮助我们删除不相关的特征,因为它们不具有预测性。在使用这些方法之前,我们可能首先要删除由于其他原因而不相关的特征。同样,我们可能希望包含某些特征,即使它们不具有预测性。这些额外的原因总结在图 5 中,我们将在下面详细介绍。
数据质量
如果某个特征的数据质量较差,则可能被视为不相关。每当我们预期数据集中的记录值与真实值不同时,我们就应该担心。例如,数据可能丢失或输入错误。数据质量差通常意味着某个特征无法预测,无论如何都会被排除。情况并非总是如此,尤其是当错误是系统性的或数据不是随机丢失时。
在某些情况下,数据可能会被用户或第三方操纵。以我们的汽车贷款模型为例,用户可能会被要求提供自己的个人信息(例如原籍国、职业)。用户可能会倾向于提供能让他们更有可能获得贷款的信息。例如,他们可能会谎称自己有一份高薪工作,比如医生或软件开发人员。我们需要独立验证这些类型的特征是否正确。
数据可用性
模型通常是在开发环境中创建的。要实际使用模型,它们需要转移到生产环境中。由于各种技术问题和成本,某些功能可能无法在生产环境中使用。换句话说,数据可用于训练模型,但不能供模型进行实时预测。要获得有效的模型,我们需要排除这些功能中的任何一个。
即使这些特征被排除在最终模型之外,我们可能仍希望将它们纳入我们的候选名单。这将使我们能够继续探索这些特征。如果我们能够证明它们具有预测性,这将有助于证明生产这些特征所涉及的工作和成本是合理的。然后它们可以用于未来的模型。
稳定性(过去和未来的表现)
你的特征现在具有预测性并不意味着它们将来也具有预测性。随着时间的推移,特征与目标变量之间的关系可能会发生变化,并且模型中捕获的关系可能会过时。这些变化是由各种内部和外部力量驱动的。例如,COVID 疫情导致客户行为突然发生变化,从而影响试图预测该行为的模型。
为了更好地理解这一点,让我们回到汽车贷款的例子。假设在疫情爆发之前,我们用 PERS7(过去 12 个月实体分行访问次数)建立一个模型。当时,更频繁去银行的客户拖欠汽车贷款的可能性较小。换句话说,PERS7 值越高,拖欠的可能性就越低。疫情爆发后,封锁意味着许多互动转移到了线上。这意味着更少的分行访问,我们会看到所有客户的 PERS7 值下降。

从我们的模型来看, PERS7 的下降表明违约风险更高。尽管许多客户的违约风险不会改变,但该模型现在会预测更高的违约概率。贵组织内部和外部还有许多其他潜在变化可能会以这种方式影响你的模型。你需要尽力考虑所有这些变化,并选择能够抵御这些变化的特征。
可解释性
可解释性 到目前为止,我们已经讨论过使用平均值和最小值等简单的聚合方法来创建特征。 还有更复杂的特征工程技术,如主成分分析 (PCA)。 例如,从图 4 中,我们可以提取收入组中的所有特征并计算 PCs。 简单来说,可以将 PCs 视为收入特征的汇总。 我们可以考虑将第 1 款 PC 列入候选名单。
第一个主成分可能比任何单个收入特征都更具预测性。然而,我们可能仍然只将简单的收入汇总纳入我们的候选名单。这是因为违约和总收入之间的关系比主成分的关系更容易理解和解释。最终,我们可以优先考虑某些特征,以提高我们模型的可解释性。如果你想了解为什么可解释性很重要,你可以阅读这篇文章:机器学习中的可解释性。
法律与道德
某些类型的信息可能不适合用来建立模型。例如,为了避免贷款中的性别歧视, PERS65 (客户性别)的使用可能是非法的。即使法律目前没有涵盖这些类型的信息,你可能仍希望避免使用它们。它们可能会导致不道德的后果和公众的强烈反对。

与直觉相反,你可能仍希望将这些特征纳入候选名单。这样才能进行算法公平性评估。如果不将性别作为特征,你就无法确定模型是否偏向某一性别。这些类型的特征称为受保护特征,不应用于构建模型。
具体问题
最后要考虑的是,模型通常包含大量分析。有时,这些分析与模型构建没有直接关系,相反,我们想要回答具体的问题。例如,某些地区的客户违约率是否不同?或者,倾向于在线互动的客户的违约率是否高于访问分支机构的客户的违约率?将回答这些类型问题所需的任何功能纳入你的候选名单会很方便。
特征选择框架
最后,所有上述考虑都需要以某种方式形式化。这就是特征选择框架的作用所在。它将概述选择特征的方法的技术细节,包括特征重要性的度量和变量聚类方法。它还可以定义处理其他考虑因素的方法(例如,需要进行哪些分析来确定特征是否稳定)。你可以在图 6 中看到此类框架的概述。
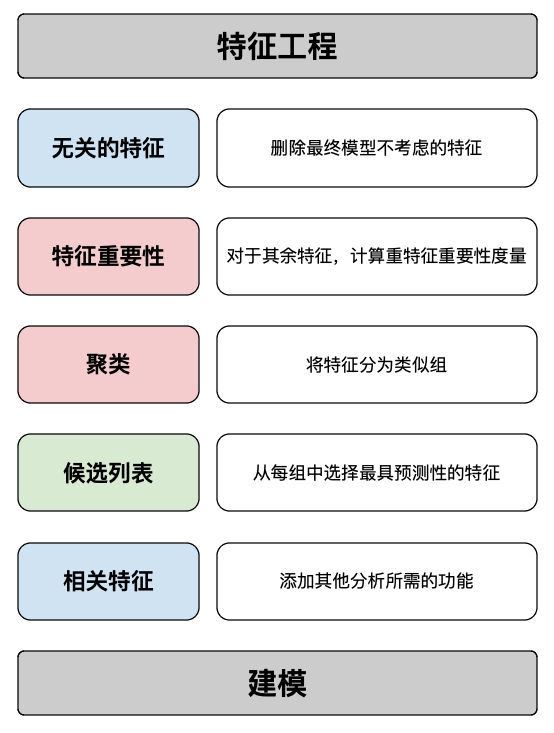
这个框架可能会成为更大的建模框架的一部分。除了特征选择之外,它还将定义特征工程的方法和使用的模型类型。建模框架可以再次成为更大的治理框架的一部分。这就是负责任的人工智能框架。我们曾在文章《[[什么是负责任的人工智能]]》中讨论负责任的人工智能及其目标。
AI 进阶:企业项目实战2
参考
N. Siddiqi, Credit Risk Scorecards: Developing and Implementing Intelligent Credit Scoring (2006)
J. Brownlee, How to Choose a Feature Selection Method For Machine Learning (2020) https://machinelearningmastery.com/feature-selection-with-real-and-categorical-data/
R Doucmentation, Variable Clustering (2021) http://math.furman.edu/~dcs/courses/math47/R/library/Hmisc/html/varclus.html
Open Risk Manual, Model Decay (2021) https://www.openriskmanual.org/wiki/Model_Decay
希望这篇文章对你有所帮助!你还可以阅读我的其他文章,或者查看有关企业 AI 实战项目的教程,相信会让你拥有更多收获。
「AI秘籍」系列课程:

良好功能的特征

