PDP 和 ICE 图的终极指南
部分依赖图和单独条件期望图背后的直觉、数学和代码(R 和 Python)
PDP 和 ICE 图都可以帮助我们了解我们的模型如何做出预测。
使用个人显示面板我们可以将模型特征和目标变量之间的关系可视化。它们可以告诉我们某种关系是线性的、非线性的还是没有关系。
同样,当特征之间存在交互时,可以使用 ICE 图。我们将深入介绍这两种方法。
我们从 PDP 开始。我们将逐步向你介绍如何创建 PDP。你会发现这是一种直观的方法。即便如此,我们也将解释 PDP 背后的数学原理。然后我们继续讨论 ICE 图。你会发现,只要对 PDP 有充分的了解,这些图就很容易理解。在此过程中,我们讨论了这些方法的不同应用和变体,包括:
- 连续特征和分类特征的 PDP 和 ICE 图
- 二元目标变量的 PDP
- 2 个模型特征的 PDP
- 衍生 PDP
- 基于 PDP 和 ICE 图的特征重要性
我们确保讨论这两种方法的优点和局限性。这些是重要的部分。它们帮助我们了解什么时候这些方法最合适。它们还告诉我们它们在某些情况下如何导致错误的结论。
最后,我们将向你介绍这些方法的 R 和 Python 代码。对于 R,我们应用 ICEbox1 和 iml2 包来创建可视化。我们还使用 vip3 来计算特征重要性。对于 Python,我们将使用 scikit-learn 的实现 PartialDepenceDisplays4。你可以在这些部分中找到带有代码的 GitHub 存储库链接。
部分依赖图 (PDP)
我们从 PDP 的逐步演练开始。为了解释这种方法,我们随机生成了一个包含 1000 行的数据集。它包含二手车销售的详细信息。你可以在 表 1 中看到这些特征。我们想使用前 5 个特征来预测汽车的 价格。

要预测价格,我们首先需要使用此数据集训练模型。在我们的例子中,我们训练了一个有 100 棵树的随机森林。确切的模型并不重要,因为 PDP 是一种与 模型无关的它们是使用模型预测构建的。我们不考虑模型的内部工作原理。这意味着我们探索的可视化对于随机森林、XGBoost、神经网络等将类似……
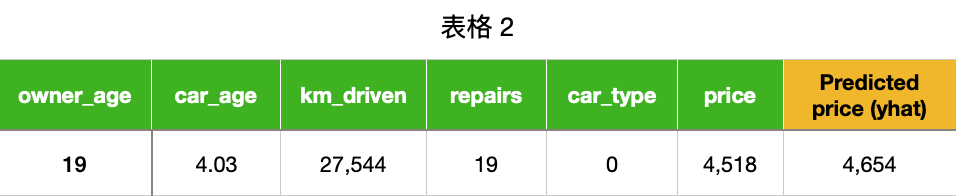
在表 2
中,我们在用于训练模型的数据集中有一个观察值。在最后一列中,我们可以看到这辆车的预测价格。要创建
PDP,我们改变其中一个特征的值并记录由此产生的预测。例如,如果我们更改
car_age,我们将得到不同的预测。我们这样做的同时将其他特征保持为其实际值不变。例如,owner_age
将保持在 19, km_drive 将保持在 27,544。
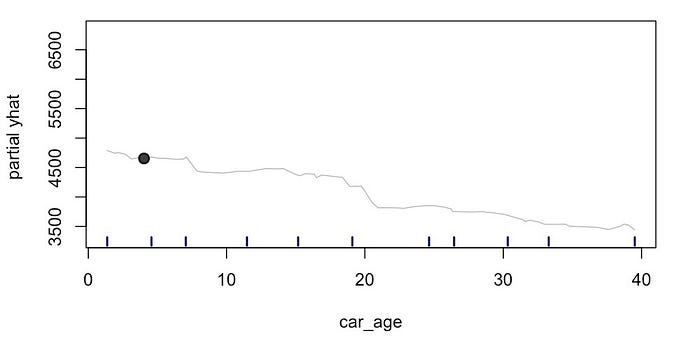
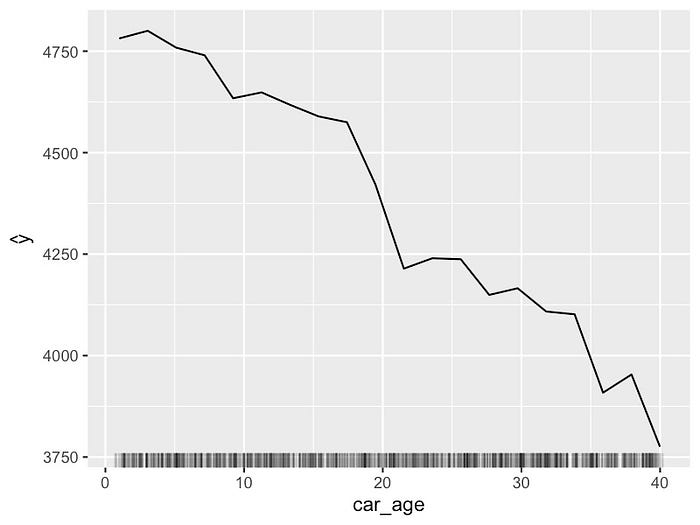
查看图
1,我们可以看到此过程的结果。这显示了此特定观察的预测价格(部分 yhat)和
car_age 之间的关系。你可以看到,随着 car_age
的增加,预测价格会下降。黑点给出了原始预测价格(4,654)和
car_age(4.03)。
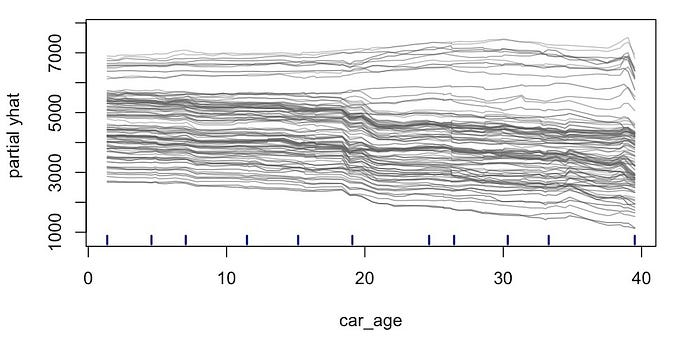
然后,我们对数据集中的每个观测值或观测值子集重复此过程。在图 2
中,你可以看到 100
个观测值的预测线。需要明确的是,对于每个观测值,我们只改变了
car_age。我们将其余特征保持为其原始值不变。这些值不会与我们在表
2 中看到的观测值相同。这解释了为什么每条线从不同的级别开始。
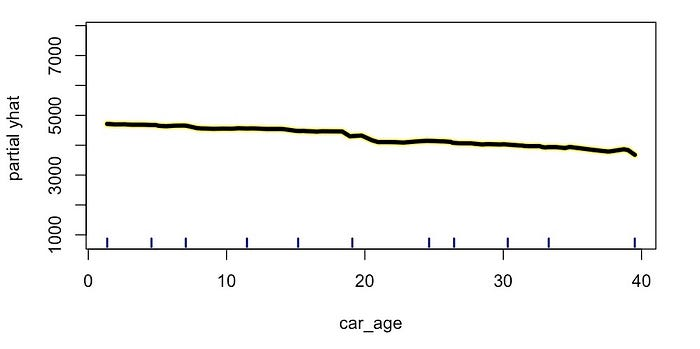
要创建 PDP,最后一步是计算 car_age
在每个值上的平均预测值。这给出了图 3 中的粗黄线。这条线就是
PDP。通过保持其他特征不变并对观测值取平均值,我们能够分离出与
car_age 的关系。我们可以看到,预测价格随着
car_age 的增加而下降。
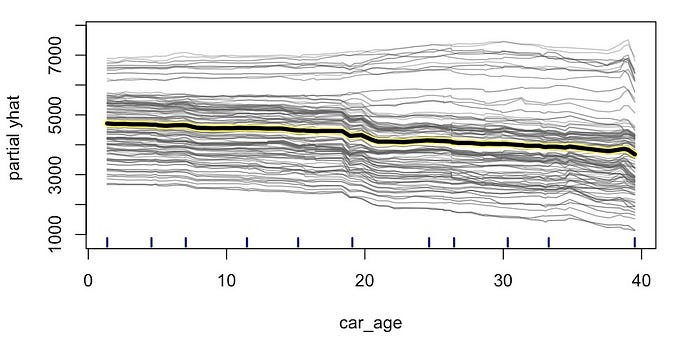
你可能已经注意到 x 轴上的短线。这些是 car_age
的四分位数。也就是说,10% 的 car_age 值小于第一行,90% 的
car_age
值小于最后一行。这被称为地毯图。它向我们展示了特征的分布。在本例中,car_age
的值在其范围内分布相当均匀。当我们讨论 PDP
的局限性时,我们将理解为什么这很有用。
你可能还注意到,并非所有单个预测线都遵循 PDP
趋势。一些较高的线似乎在增加。这表明,对于这些观察结果,价格与
car_age 具有相反的关系。也就是说,预测价格会随着
car_age 的增加而增加。记住这一点。我们稍后在讨论 ICE
图时会回顾这一点。
PDP 背后的数学原理
对于数学思维更强的人来说,PDP 还有一个正式的定义。让我们从刚刚创建的
PDP 函数开始。它由公式 1 给出。集合 C 将包含除 car_age
之外的所有特征。对于给定的 car_age 值和观测值 i,我们使用 C
中特征的原始值来找到预测价格。我们对所有 100
个观测值执行此操作并找到平均值。这个等式将给出我们在图 3
中看到的粗黄线。
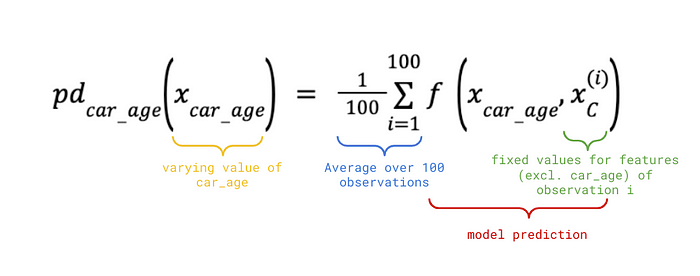
在公式 2 中,我们概括了上述公式。这是特征集 S 的 PD 函数。C 将包含除 S 中的特征之外的所有特征。我们现在还对 n 个观测值取平均值。这最多可达数据集中的观测值总数(即 1000)。
\[ \textbf{方程 2:特征集 S 的近似 PD 函数} \\ pd_S(x_s) = \frac{1}{n}\sum_{i=1}^n f(x_s,x_c^{(i)}) \]
到目前为止,我们仅讨论了 S 由一个特征组成的情况。在上一节中,我们有
S = {car_age}。稍后,我们将向你展示 2 个特征的
PDP。我们通常不会在 S 中包含超过 2 个特征。否则,很难可视化 PD
函数。
上述方程实际上只是 PD 函数的近似值。真正的数学定义在公式 3中给出。对于集合 S 中的给定值,我们会找到相对于集合 C 的预期预测。为此,我们需要将模型函数与观察集合 C 中的值的概率进行积分。要完全理解这个方程,你需要具备一些随机微积分经验。
\[ \textbf{公式 3:特征集 S 的 PD 函数} \\ pd_s(x_s) = E_{X_c}[f(x_s, X_c)] = \int f(x_s, X_c)dP(X_c) \]
使用 PDP 时,对近似值的理解就足够了。真正的 PD 函数并不实用。首先,与近似值相比,真正的 PD 函数的计算成本更高。其次,由于我们的观测数量有限,我们只能近似概率。也就是说,我们无法找到每个观测值的真实概率。最后,许多模型不是连续函数,因此很难集成。
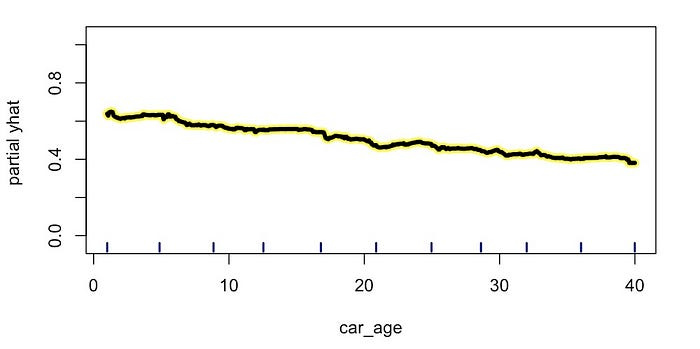
连续特征的 PDP
在了解如何创建 PDP 之后,我们将继续使用它们。使用这些图,我们可以了解
模型特征与目标变量之间关系的性质。例如,我们已经在图 4 中看到了
car_age PDP 。预测价格以相当恒定的速度下降。这表明
car_age 与价格呈 线性关系。
在图 5 中,我们可以看到另一个特征 repairs 的 PDP
。这是汽车接受的维修/服务次数。最初,预测价格趋于随着维修次数的增加而增加。我们预计一辆可靠的汽车会定期接受一些维护。然后,在
6/7
次维修左右,价格趋于下降。过度维修可能表明汽车出了问题。由此,我们可以看到价格与维修之间存在
非线性关系 。
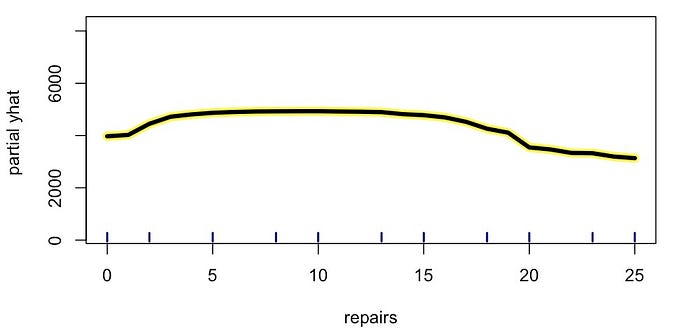
从上面可以看出,PDP 在 可视化 非线性关系方面很有用。我们将在文章《查找并可视化非线性关系》中更深入地探讨这个主题。处理许多特征时,查看所有 PDP 可能不切实际。因此,我们还讨论了使用互信息和特征重要性来帮助 找到 非线性关系。
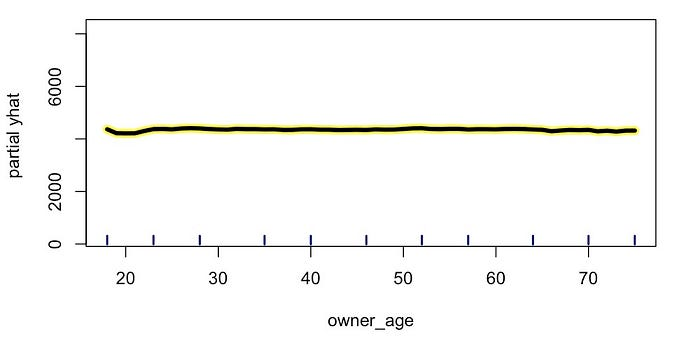
在 图 6 中,我们可以看到特征与目标变量没有关系时的 PDP 示例。对于
owner_age ,PDP 是恒定的。这告诉我们,当我们改变
owner_age
时,预测价格不会改变。稍后,我们将看到如何使用这种 PDP
变化的思想来创建特征重要性分数。
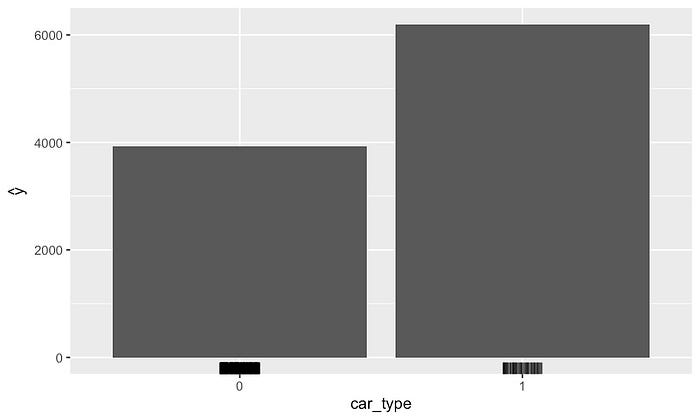
分类特征的 PDP
我们上面讨论的特征都是连续的。我们也可以创建分类特征的
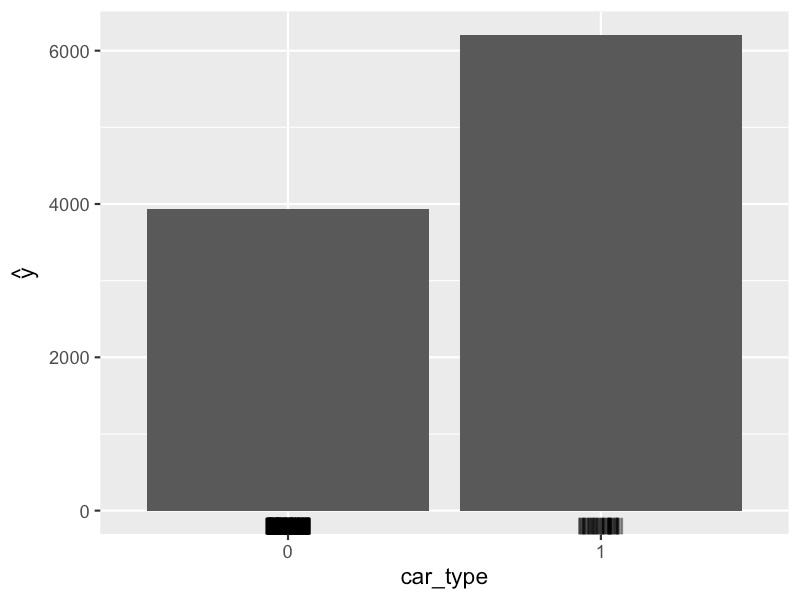
PDP。例如,参见图 7 中 car_type
的图。在这里,我们计算每种车型的平均预测值——普通 (0) 或经典
(1)。我们用直方图来可视化这些,而不是用直线。我们可以看到,经典汽车往往以更高的价格出售。
二元目标变量的 PDP
二元目标变量的 PDP 与连续目标的 PDP 类似。假设我们想要预测汽车价格是高于 (1) 还是低于 (0) 平均值。我们构建一个随机森林,使用相同的特征来预测这个二元变量。我们可以使用与之前相同的过程为该模型创建 PDP。只不过现在我们的预测是一个概率。
例如,在图 8 中,你可以看到 car_age 的 PDP。我们现在在 y
轴上有一个预测概率。这是汽车价格高于二手车平均价格的概率。我们可以看到,概率随着汽车年龄的增长而下降。
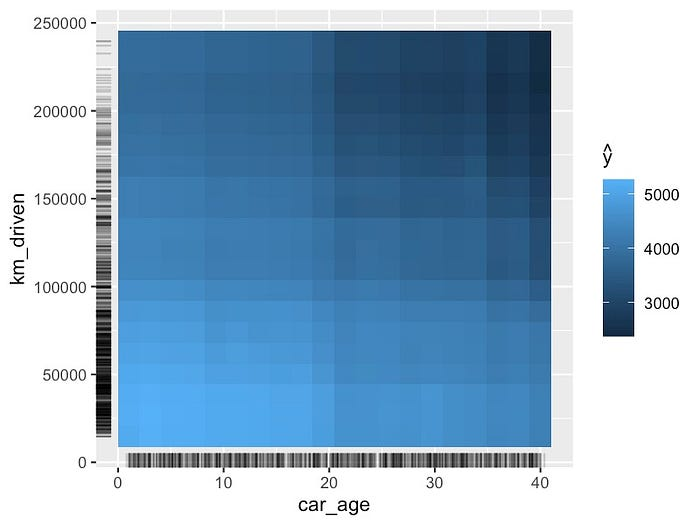
2 个特征的 PDP
回到我们的连续目标变量。我们还可以可视化两个特征的 PDP。在图 9
中,我们可以看到 km_driven 和 car_age
的不同组合的平均预测值。此图表的创建方式与一个特征的 PDP
相同。即保持其余特征的原始值。
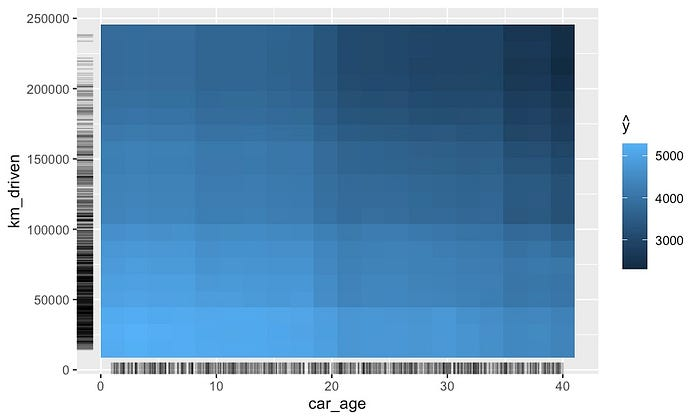
这些 PDP 可用于可视化特征之间的相互作用。上图表明
km_driven 和 car_age
之间可能存在相互作用。也就是说,当两个特征的值较大时,预测价格往往会较低。在得出此类结论时,你应该谨慎行事。
这是因为如果两个特征相关,我们可以得到相似的结果。稍后,当我们讨论
PDP 的局限性时,我们会看到情况确实如此。即 km_driven 与
car_age
相关。汽车越旧,行驶里程就越高。这就是为什么当两个特征都较高时,我们看到的预测价格会更低。
衍生 PDP
导数 PDP 是 PDP 的变体。它显示 PDP 的斜率/导数。它可用于更好地理解原始 PDP。然而,在大多数情况下,我们从这些图中获得的洞察力是有限的。它们通常对非线性关系更有用。
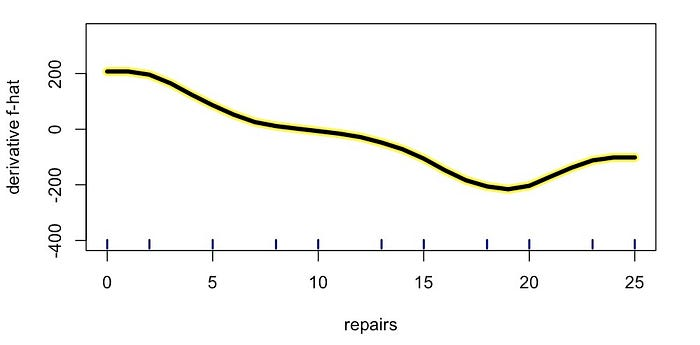
例如,以图 10 中的维修导数 PDP 为例。这是我们之前在图 5 中看到的线的导数。我们可以看到,在 6 次维修左右,导数为 0。此时,导数从正变为负。换句话说,原始 PDP 从相对于维修增加变为减少。这告诉我们,经过 6 次维修后,汽车的价格将趋于下降。
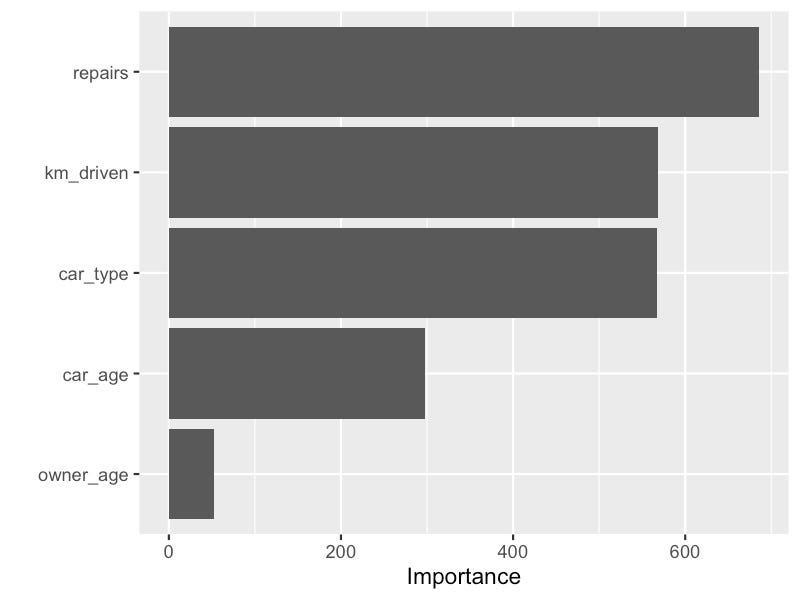
PDP 特征重要性
本节结束时,我们根据 PDP 得出一个特征重要性分数。这是通过确定每个特征的 PDP 的“平坦度”来实现的。具体来说,对于连续变量,我们计算图值的标准差。对于分类变量,我们首先取范围来估计 SD。即最大值减去最小 PDP 值。然后我们将范围除以 4。此计算来自称为范围规则的概念。
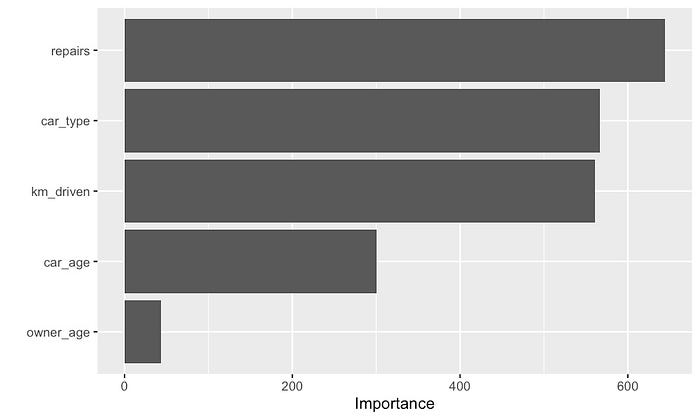
你可以在图 11 中看到基于 PDP 的特征重要性。请注意,
owner_age 的得分相对较低。如果我们回想一下图 6 中的
PDP,这是有道理的。我们看到 PDP 相对恒定。换句话说,y
轴值始终接近其平均值。它们具有较低的标准差。
还有更广为人知的特征重要性分数,例如排列特征重要性。你可能更喜欢使用这种基于 PDP 的分数,因为它可以提供一定的一致性。如果你正在分析特征趋势,你现在可以使用使用类似逻辑计算的特征重要性分数。你还可以避免解释两种不同方法的逻辑。
个体条件期望 (ICE) 图
说完了 PDP,让我们继续讨论 ICE
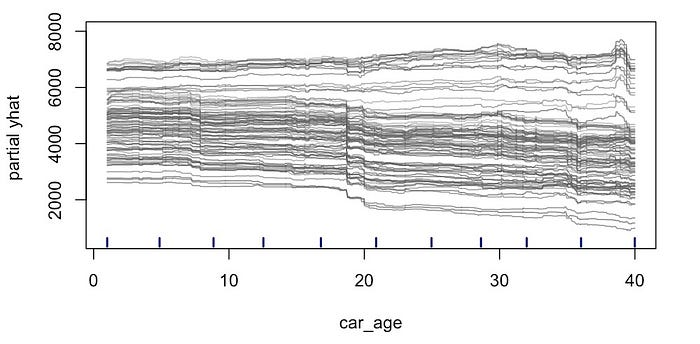
图。你会很高兴知道我们已经讨论过创建它们的过程。以下面的图 12
为例。这是我们在图 3 中的 car_age PDP 之前创建的图。这是
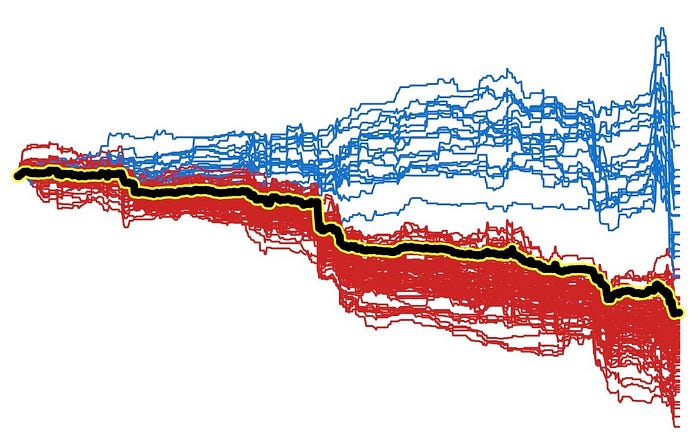
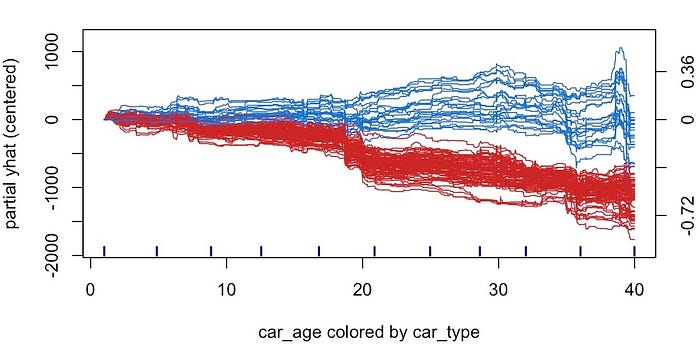
car_age 的 ICE 图。ICE 图由每个单独观察的预测线组成。
当模型中存在交互时,ICE
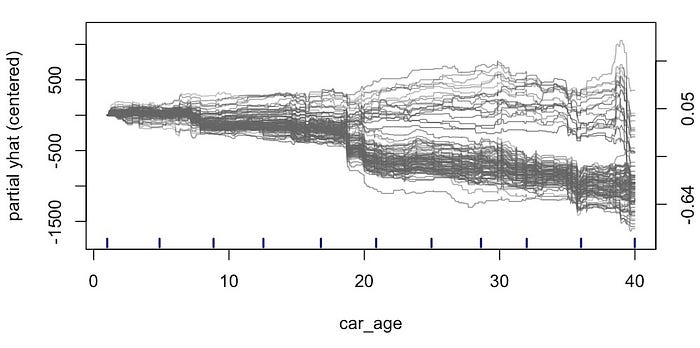
图很有用。也就是说,如果一个特征与目标变量的关系取决于另一个特征的值。在上面的图表中可能很难看到这一点。为了使事情更清楚,我们可以将
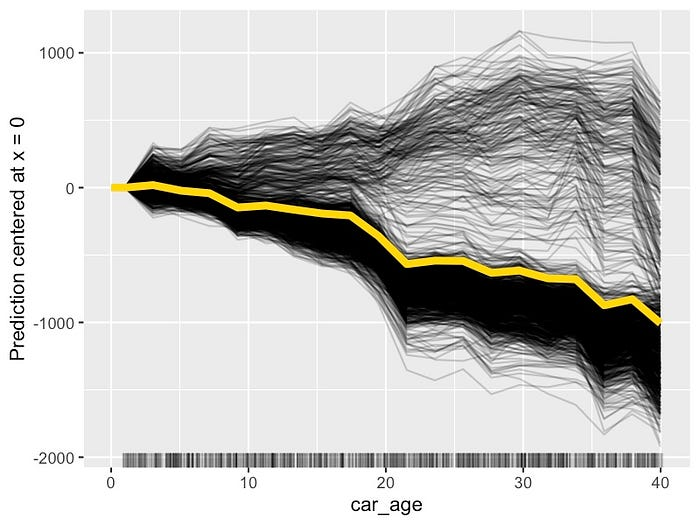
ICE 图置于中心。在图 13 中,我们通过使所有预测线从 0
开始来实现这一点。现在很明显,对于某些观察结果,预测价格趋于随着
car_age 的增加而增加。
为了了解导致这种现象的原因,我们可以更改 ICE 图的颜色。在图 14
中,我们根据 ·
更改了颜色。我们将经典汽车的线条设为蓝色,将普通汽车设为红色。我们现在可以看到,这种关系来自
car_age 和 car_type
之间的相互作用。直观地讲,经典汽车的价值会随着年龄的增长而增加,这是有道理的。
最后,将 PDP 线添加到图中。这样,我们可以将 ICE 图和 PDP 结合起来。这可以强调一些观察结果如何偏离平均趋势。我们可以看到,如果我们只依赖 PDP,我们就会错过这种相互作用。也就是说,当使用图 3 中的 PDP 时,我们得出结论,所有汽车的价格都趋于随着年龄的增长而下降。
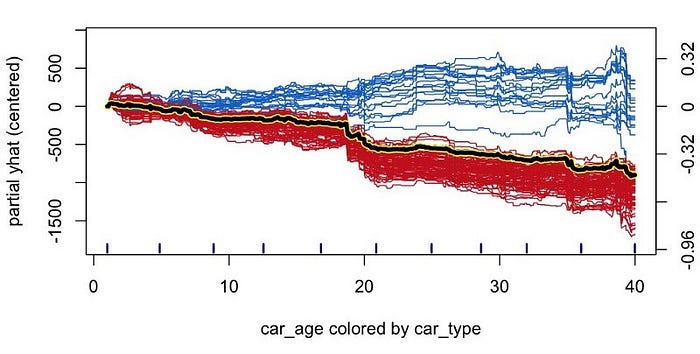
与 PDP 一样,ICE 图可以帮助我们直观地了解数据中的重要关系。为了找到这些关系,我们可能需要使用特征重要性等指标。另一种专门用于突出显示模型中交互作用的指标是 Friedman 的 H 统计量。我们曾在文章《寻找并可视化交互》中讨论如何使用所有这些方法。
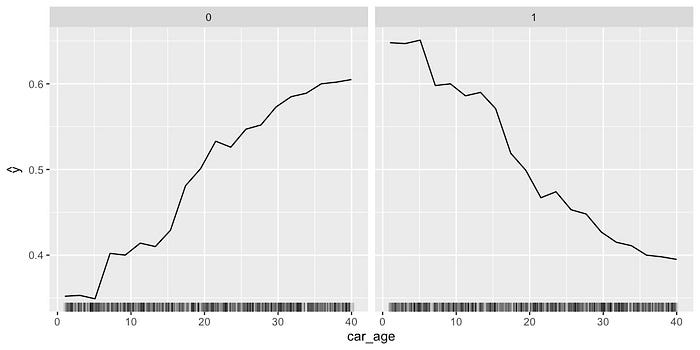
分类特征的 ICE 图
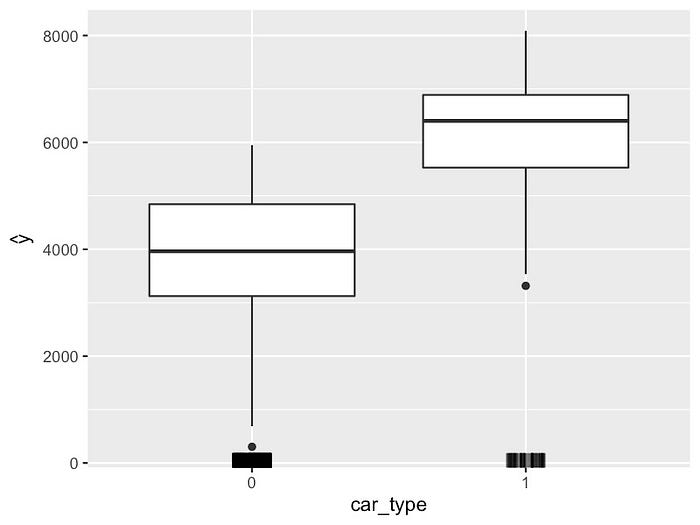
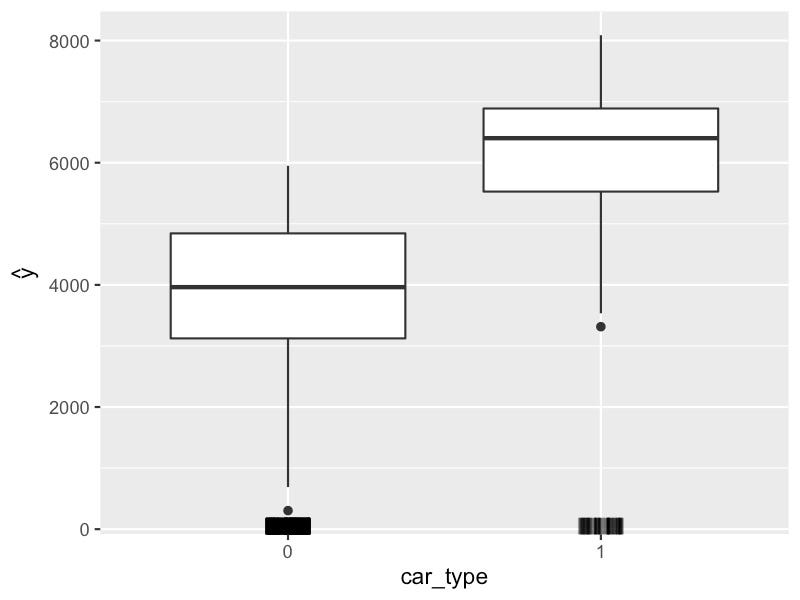
我们可以使用箱线图来可视化分类特征的 ICE 图。例如,我们在图 16
中绘制了 car_type 的 ICE
图。箱线中间的粗线给出了平均预测。换句话说,它们是
PDP。我们可以看到,普通汽车的预测价格趋于较低(0)。
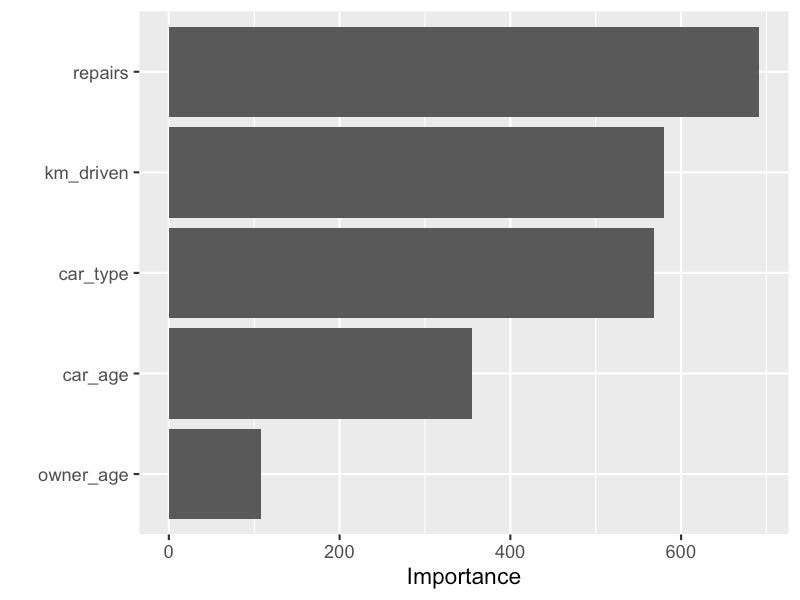
基于 ICE 图的特征重要性
我们还可以计算基于 ICE 图的特征重要性得分。这与基于 PDP 的得分类似,只是我们不再考虑平均预测线。我们现在使用各个预测线来计算得分。这意味着得分将考虑特征之间的相互作用。
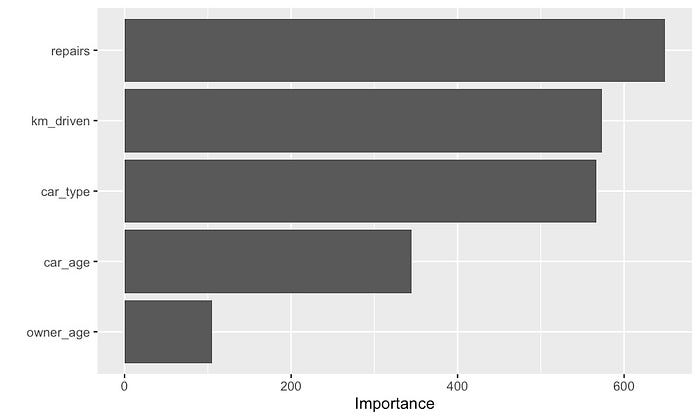
图 17 中给出了我们模型的基于 ICE 图的分数。我们可以将这些分数与图 11
中的基于 PDP 的分数进行比较。最大的区别是 car_age
的分数现在更高了。它从 300 增加到了
345。根据我们上面的分析,这是有道理的。我们看到存在一个影响
car_age 和 price 之间关系的相互作用。基于 PDP
的特征重要性不考虑这种相互作用。
PDP 和 ICE 图的优势
到目前为止,希望我们已经很好地理解了 PDP 和 ICE 图以及我们可以从中获得的见解。我们将继续讨论这些方法的优势。然后在下一节中,我们将讨论其局限性。理解这些至关重要,这样你就不会从图中得出错误的结论。
隔离特征趋势
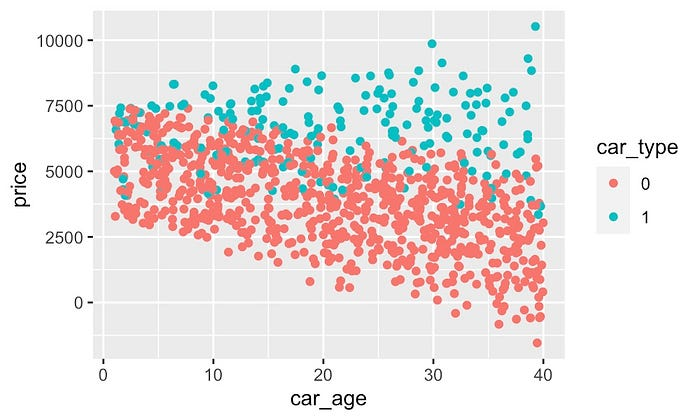
我们可以使用散点图来可视化数据中的关系,但数据很混乱。例如,我们可以在图
18 中看到 car_age 和 car_type
之间的相互作用。这些点围绕真实的潜在趋势而变化。这是因为统计噪声以及价格也与其他特征有关系这一事实。在真实的数据集中,这个问题可能会更严重。最终,很难看出数据中的趋势。
使用 PDP 和 ICE 图时,我们不再使用原始数据值。我们使用模型预测。如果构建正确,模型将捕捉数据中的潜在关系并忽略统计噪声。然后我们可以隔离特定特征的趋势。这是通过保持其他特征值不变并对观察值取平均值来实现的。
这就是 PDP 和 ICE 图如此有用的原因。它们允许我们去除噪音和其他特征的影响。这使得我们更容易看到数据中的潜在关系。从这个意义上说,这些方法可以用于数据探索,而不仅仅是理解我们的模型。
直接解释
希望通过向你介绍构建 PDP 的过程,你能够轻松理解。这样,你就可以直观地了解该方法,而无需数学定义。这也意味着这些方法很容易向非技术人员解释。这在行业环境中很有用。
易于实施
这些方法也很容易实现。我们只需要改变特征值并记录结果预测。我们甚至不需要考虑模型的内部工作原理。这意味着相同的实现可以用于任何模型。当我们讨论 R 和 Python 代码时,你会发现这些方法已经有很好的实现。
PDP 和 ICE 图的局限性
假设特征独立
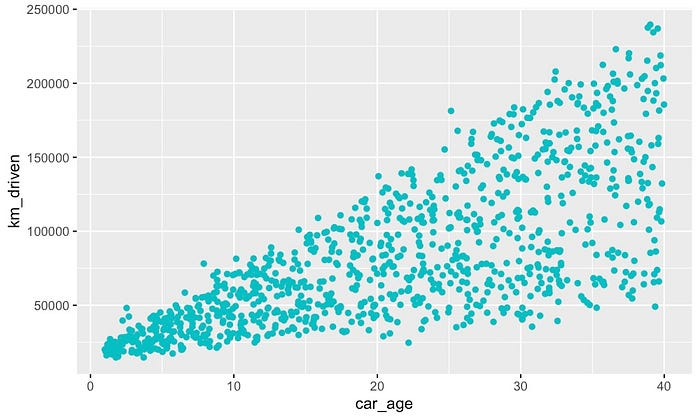
继续讨论局限性,我们将从这些方法的主要问题开始。即它们假设特征是独立的。情况并非总是如此,因为特征可以相互关联或相关联。例如,以图
19 中的 km_driven 和 car_age
散点图为例。它们之间存在明显的相关性。直观上看,这是有道理的。较旧的汽车往往行驶距离较长。
问题是,当我们为观察结果构建预测线时,我们将对特征的所有可能值进行采样。例如,假设我们想为
km_driven 构建 PDP。以图 20 中红色给出的观察结果为例。它的
car_age 为
10。为了构建预测线,我们将针对虚线椭圆中的所有值改变
km_driven。然而,实际上,具有此 car_age
的观察结果仅在实线椭圆内具有行驶距离。
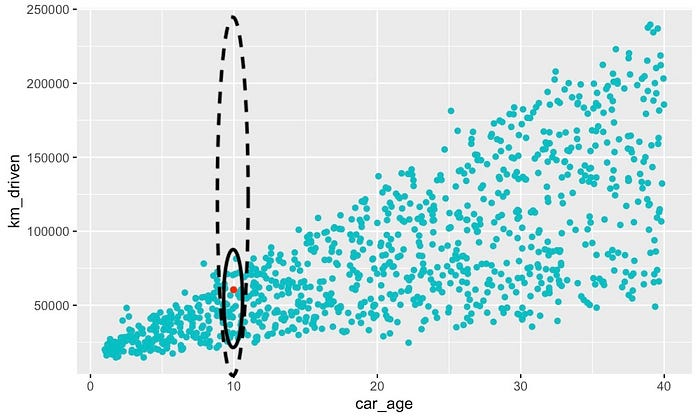
我们的模型并未针对实心椭圆之外的观测进行训练。尽管如此,我们仍会根据这些观测的预测来创建 PDP。结果是,预测线是建立在模型之前未“见过”的观测之上的。这可能会产生不直观的结果,并导致关于特征趋势的错误结论。
平等关注所有特征值
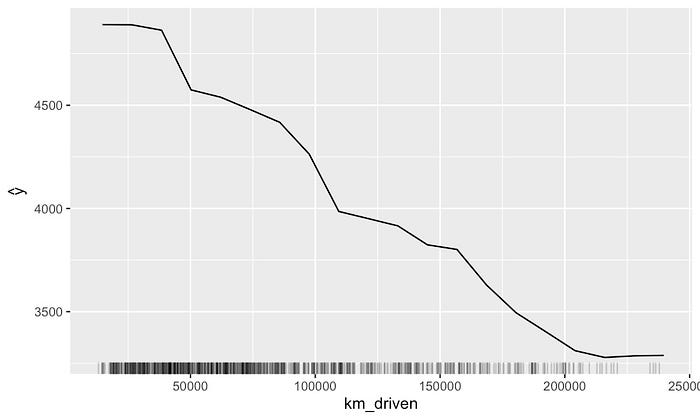
即使特征不相关,我们仍然可能得出错误的结论。对于每个观察值,我们都对所有可能的特征值进行采样。这为所有值赋予了相同的权重。实际上,特征的某些值不太常见。例如在特征分布的极端值。这些值的趋势将更加不确定。
考虑到这一点,通常会包含一个地毯图。这有助于我们了解特征的分布。之前我们看到了地毯图的分位数版本。图
21
给出了另一个版本。这里我们为每个观察值绘制了一条单独的线。我们可以看到,
km_driven
值越高,观察值就越少。因此,我们应该更加谨慎地解释这些值的趋势。
结论取决于你的模型
正如优点中提到的,使用模型预测可以帮助我们更清楚地看到关系。问题是模型可能会做出错误的预测。欠拟合的模型可能会错过重要的关系。通过建模噪声,过度拟合的模型可以呈现实际上不存在的关系。最终,我们得出的结论将取决于我们的模型。考虑模型的性能很重要。
即使模型准确,我们仍可能遇到问题。模型可能会忽略某些关系而偏向其他关系。我们可能会得出错误的结论,认为被忽略的特征与目标变量没有关系。这意味着,在进行数据探索时,你可能希望将特征限制在你感兴趣的子集内。
PDP 忽略了互动
如前所述,使用平均值,PDP 可能会错过交互。因此,基于 PDP
的特征重要性也会错过这些交互。这意味着,如果存在交互,分数可能会低估特征的重要性。我们在
car_age 特征中看到了这一点。一种解决方案是使用 ICE
图或仅坚持排列特征重要性。
实施的局限性
在接下来的部分中,我们将向你介绍用于实现这些方法的代码。我们将看到每个实现都有自己的优点和缺点。有些包不会实现我们讨论的所有图。例如,如果你使用 Python,则没有(据我所知)用于衍生 PDP 或特征重要性的实现。
PDP 和 ICE 图的 R 代码
在本节中,我们将向你介绍用于创建 PDP 和 ICE 图的 R 代码。我们将研究使用三个不同的包。我们使用 ICEbox5 和 iml6 来创建图。结合起来,我们可以创建上面讨论的所有图。对于特征重要性分数,我们使用 vip7 。你可以在 GitHub8 上找到我们讨论的所有代码。
我们首先加载数据集(第 1 行)。这与文章开头表 1 中讨论的数据集相同。我们还将 car_type 设置为分类特征(第 2 行)。
1 | |
建模
在创建 PDP 和 ICE 图之前,我们需要一个模型。我们使用 randomForest 包来执行此操作(第 1 行)。我们使用价格和 6 个特征构建一个模型(第 4-6 行)。具体来说,我们使用了一个包含 100 棵树的随机森林(第 6 行)。
1 | |
对于下面的大多数图,我们将使用模型
rf。该模型已在连续目标变量上进行了训练。我们还想在二进制目标变量上构建一个模型
rf_binary。这是为了向你展示不同类型的目标的代码和输出有何不同。
首先,我们创建二元目标变量。如果原车价格高于平均水平,则其值为 1,如果低于平均水平,则其值为 0(第 2-4 行)。然后,我们像以前一样构建一个随机森林(第 7-9 行)。有了这些模型,我们现在可以继续使用 PDP 和 ICE 图来了解它们的工作原理。随着我们的前进,输出将显示在相关代码下方。
1 | |
包 — ICEbox
我们将从 ICEbox 包开始(第 1 行)。我们将使用它为
car_age 创建 PDP。我们使用 ice 函数为
car_age 创建 iceplot 对象(第 4-7
行)。我们传递模型、特征和目标变量(第 4-6 行)。此对象将包含
car_age 的所有单独预测线。它还将包含平均预测线(即
PDP)。
然后,我们使用 plot 函数显示 iceplot 对象(第 9-11
行)。默认情况下,此包将始终显示 ICE 图。要创建
PDP,我们需要隐藏各个预测线。我们通过将它们全部设为白色(第 11
行)来实现这一点。我们还隐藏了给出原始 car_age 值的点(第
10 行)。
1 | |
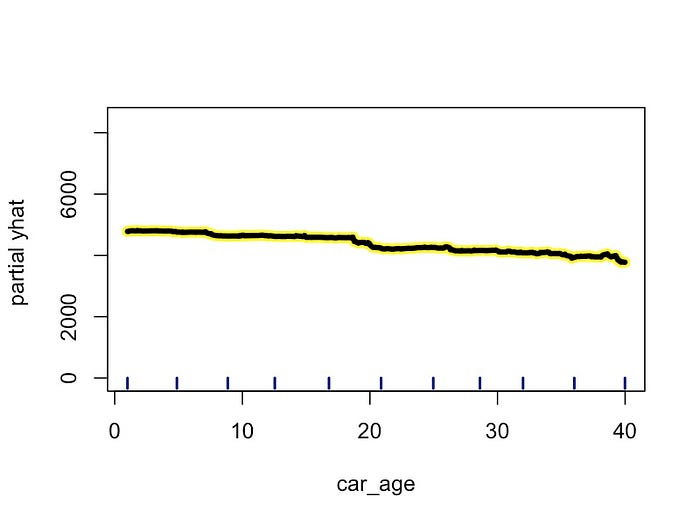
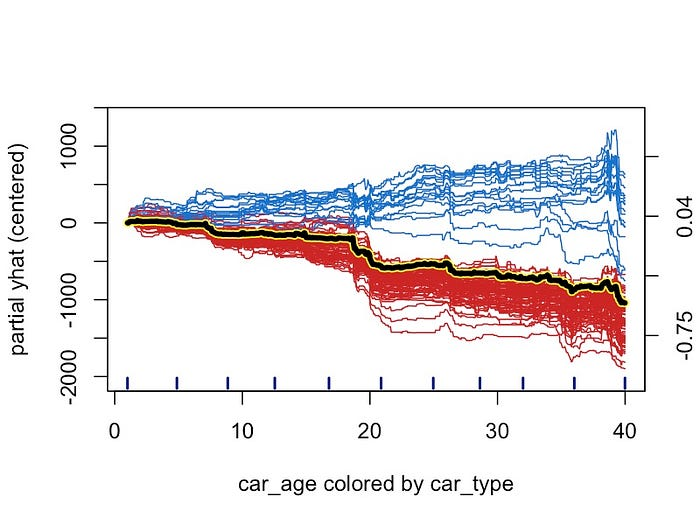
要创建 ICE 图,我们可以使用相同的 iceplot 对象。现在,我们不再隐藏各个线条,而是根据它们的 car_type 为它们着色(第 5 行)。经典汽车和普通汽车通过将线条分别设为蓝色和红色来区分。我们还输入了 ICE 图(第 3 行)。我们通过仅绘制 10% 的各个线条(第 2 行)将图限制为 100 个观测值。
1 | |
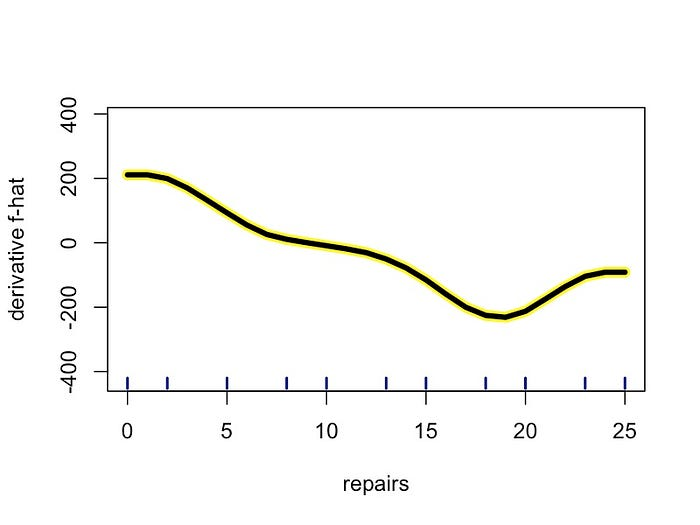
我们还可以使用 ICEBox 包来绘制衍生 PDP。我们以与之前相同的方式创建一个用于修复的 iceplot 对象(第 1-4 行)。然后我们使用它来创建一个骰子对象(第 5 行)。最后,我们绘制骰子对象(第 7-10 行)。我们设置了 plot_sd = F(第 10 行)。这隐藏了各个预测线的标准偏差。
1 | |
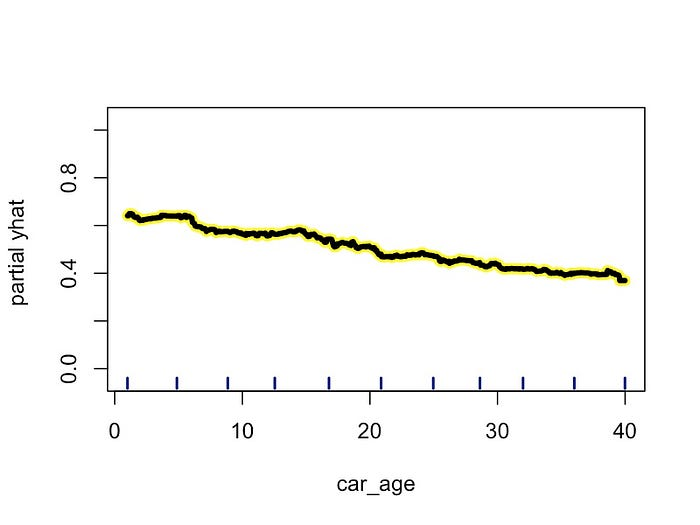
我们使用此包创建的最后一个图是二进制目标变量的
PDP。代码与之前类似。除了使用 rf_binary
之外,唯一的区别是传入一个预测函数(第 4-6 行)。这让 ice
函数知道我们的预测是以概率形式给出的。
1 | |
ICEBox 包有一些优势。通过使用另一个特征为 ICE 图着色,我们可以清楚地看到交互作用。它也是唯一实现了衍生 PDP 的包。在限制方面,它不处理分类特征。这意味着我们无法为 car_type 特征创建图。它还没有为 2 个特征实现 PDP。
包 — iml
下一个包 iml 可以解决其中的一些限制。我们将首先使用它为 car_age 创建 PDP。我们使用随机森林和数据集创建一个预测器对象(第 4 行)。然后,我们使用它创建一个特征效果对象(第 7-9 行)。我们使用“pdp”作为特征效果方法(第 9 行)。最后,我们绘制这个特征效果对象(第 10 行)。
1 | |
我们使用类似的代码为 car_age 创建 ICE 图。我们使用与之前相同的预测器对象(第 1 行)。现在我们将方法设置为“pdp+ice”(第 3 行)。这将为我们提供一个组合的 PDP 和 ICE 图。我们还将图居中,因此所有预测线都从 0 开始(第 4 行)。将方法设置为“ice”将删除黄色 PDP。
1 | |
iml 包还可以处理分类特征。下面我们为 car_type 创建 PDP(第 2-5 行)。这为我们提供了下面的直方图。同样,我们为 car_type 创建 ICE 图(第 8-11 行)。这为我们提供了箱线图。
1 | |
iml 的另一个优点是它为 2 个特征实现了 PDP。下面我们为 car_age 和 km_driven 创建 PDP。代码与之前类似。唯一的区别是我们传递了一个包含两个特征名称的向量(第 2 行)。
1 | |
最后,我们为二进制目标变量创建一个 PDP。我们使用
rf_binary (第 1
行)创建预测器对象,但其余代码与以前相同。你可以看到我们现在有两个图。请注意,它们是彼此相反的。这是因为第一个图给出了汽车低于平均水平的概率(0)。第二个图给出了它高于平均水平的概率(1)。当你的目标变量具有超过
2 个值时,为每个值绘制图很有用。
1 | |
套餐 — vip
上述两个包都没有实现特征重要性分数。为了计算这些分数,我们使用 vip 包(第 1 行)。创建基于 PDP 的分数(第 4 行)和基于 ICE 的分数(第 7 行)非常简单。我们将方法设置为“firm”。这代表特征重要性排名度量。
1 | |
PDP 和 ICE 图的 Python 代码
在本节中,我们将向你介绍用于创建 PDP 和 ICE 图的 Python 代码。你也可以在 GitHub9 上找到此代码。我们将使用 scikit-learn 的 PartialDependenceDisplay10 实现。另一个我们不会讨论的软件包是 PDPbox11 。
我们首先导入 Python 包。我们导入一些用于处理和可视化数据的常用包(第 2-4 行)。我们有两个不同的建模包 - RandomFrorestRegressor (第 6 行)和 xgboost(第 7 行)。最后,我们用我们的包来创建 PDP 和 ICE 图(第 9-10 行)。第一个包用于可视化图。第二个包用于获取用于创建图的预测。这在我们稍后探索分类特征时会派上用场。
1 | |
PDP 包由 scikit-learn 提供。你仍然可以将它们用于未使用 scikit-learn 包创建的模型。稍后当我们使用 xgb 包对二进制目标变量进行建模时,你会看到这一点。
连续目标变量
我们将从连续目标变量开始。我们加载数据集(第 2 行)。这与我们在文章开头的表 1 中讨论的相同。我们得到目标变量(第 5 行)和特征(第 6 行)。我们用它们来训练随机森林(第 9-10 行)。具体来说,随机森林由 100 棵树组成。每棵树的最大深度为 4。
1 | |
我们现在可以使用 PartialDependenceDisplay
包来了解该模型的工作原理。首先,我们将为 car_age 创建一个
PDP。为此,我们使用 from_estimator 函数。我们传入模型、X
特征矩阵和特征名称。你可以在代码下方看到输出。
1 | |
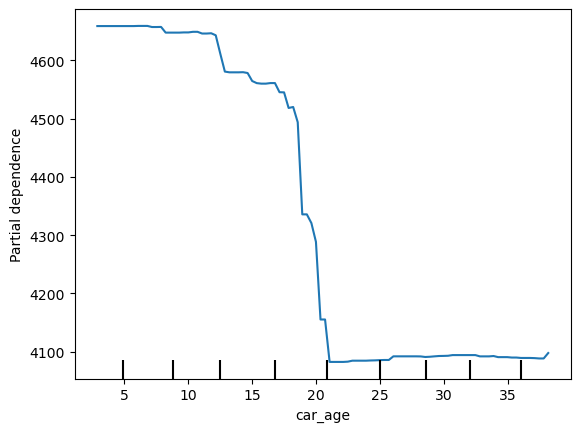
要创建 ICE 图,我们需要将 kind 参数设置为“individual”(第 4
行)。我们还将图居中(第 6 行)。默认情况下,这些函数仅显示特征的 5% 到
95% 百分位数。如果要显示 car_age
的全部范围,则需要更改此设置。即 0 到 40。我们在第 5 行执行此操作。
1 | |
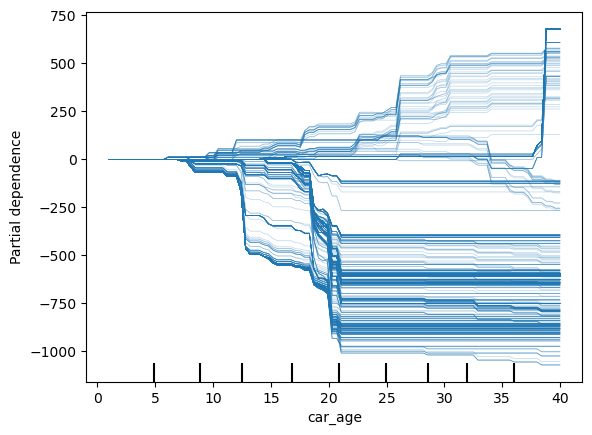
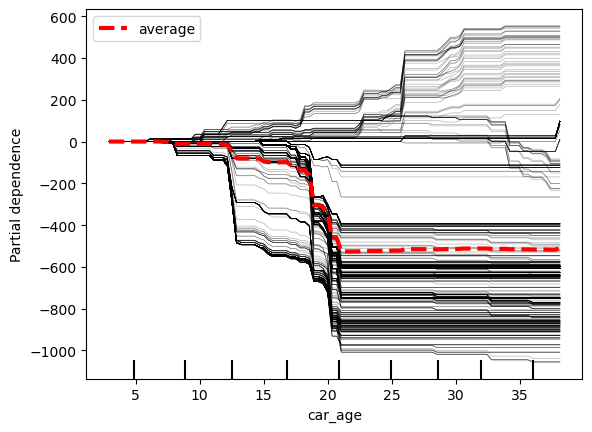
下面我们探讨一些其他选项。将 kind 功能设置为“both”将同时显示 PDP 和
ICE 图(第 6 行)。我们还可以使用 ice_lines_kw ( 第 7
行)和 pd_line_kw(第 8 行)参数分别更改 ICE 图和 PDP
线的样式。
1 | |
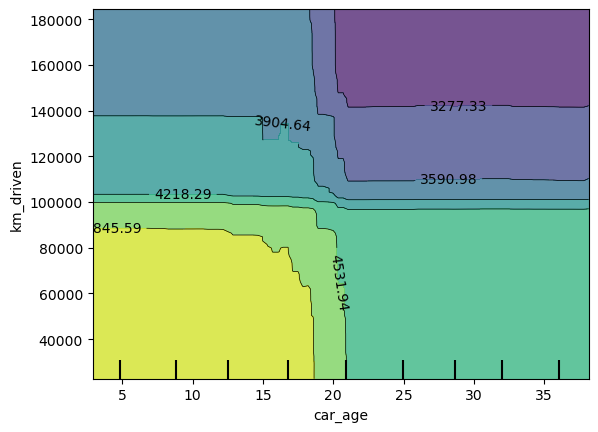
创建 2 个特征的 PDP
与之前类似。我们需要做的就是传递一个特征名称数组,而不是单个特征名称。你可以在下面看到我们如何为
car_age 和 km_driven 执行此操作。
1 | |
scikit-learn 包的一个缺点是它将分类特征视为连续特征。你可以在下面看到其结果。PDP 和 ICE 图由线给出。直方图和箱线图可以给出更好的解释。
1 | |
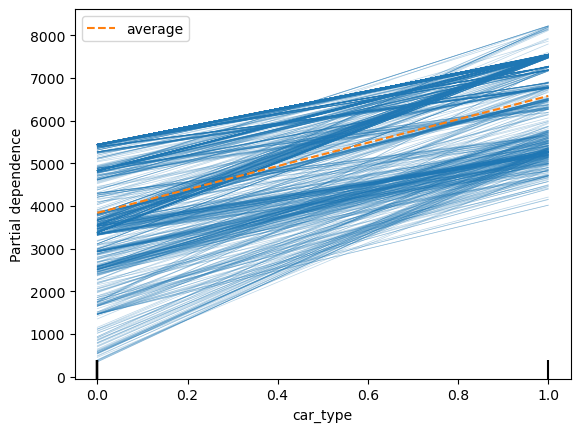
我们可以通过创建自己的图来解决这个问题。我们使用
partial_dependence 函数(第 3
行)来实现这一点。我们使用这个函数的方式与 for_estimator
函数相同。不同之处在于它不显示图。它只返回用于创建图的数据。pd_ice
将包含 car_type 的 PDP 和 ICE 图的数据。
1 | |
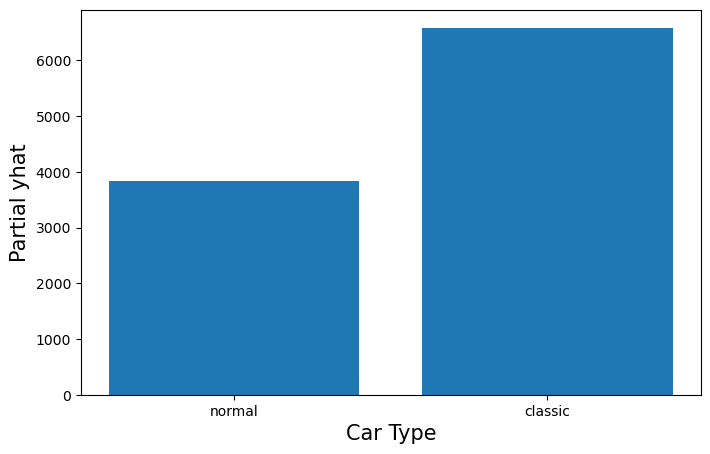
你可以在下面看到我们如何使用它来创建 PDP。我们首先从
pd_ice (第 2
行)获取平均值。这将是普通汽车和经典汽车的平均预测。使用这些,我们绘制了一个条形图(第
5-14 行)。
1 | |
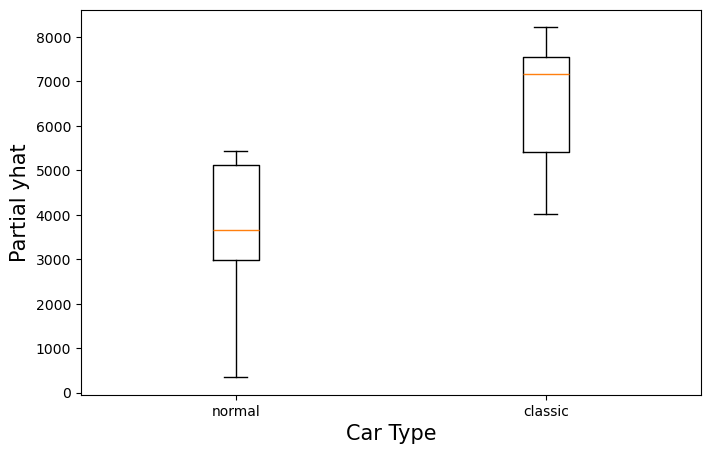
对于 ICE 图,我们可以创建一个箱线图。我们从 pd_ice
中获取单个预测(第 2
行)。然后,我们将它们分为普通汽车和经典汽车预测(第 4-6
行)。最后,我们绘制箱线图(第 9-14 行)。
1 | |
二元目标变量
最后,我们将为二进制目标变量创建一个 ICE 图。首先,我们创建变量(第
2-3 行)。如果原车价格高于平均水平,则其值为
1,如果低于平均水平,则其值为 0。我们使用这个二进制变量训练模型(第 6-7
行)。这次我们使用了 max_depth 为 2 且有 100 棵树的
XBGClassifier。
1 | |
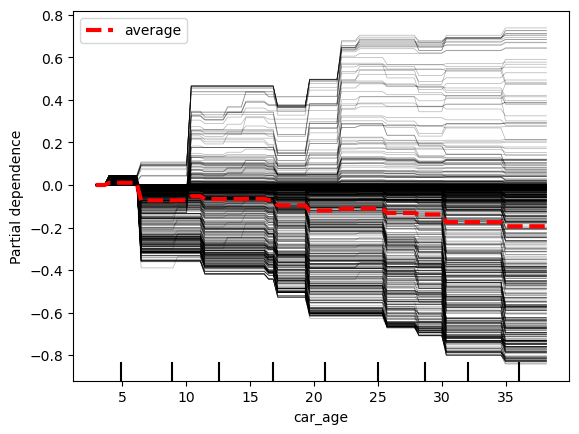
我们像之前一样绘制了 car_age 的 ICE 图。你会注意到,y
轴现在给出的是(中心)概率而不是价格。你还可以看到,将 scikit-learn
包与其他建模包一起使用非常简单。
1 | |
使用 Python 的缺点是,据我所知,没有针对衍生 PDP
和特征重要性分数的实现。不过,对于大多数问题,上述图表就是你所需要的。如果你需要其他方法,你可以使用
partial_dependence 函数自行实现它们。
希望你觉得这篇文章有用!我真的希望它成为PDP 和 ICE 图的终极指南。如果你认为我遗漏了任何内容,可以给我留言提出。此外,如果有任何不清楚的地方,请告诉我。我很乐意更新文章(不过公众号无法大幅度更新内容,需要在其他地方进行更新。) :)
PDP 和 ICE 图是可解释的机器学习方法。它们用于了解我们的模型如何进行预测。另一种流行的方法是 SHAP。SHAP 值的优点是它们可用于了解单个预测是如何做出的。它们也可以汇总起来以了解整个模型的工作原理。在文章《Python 中的 SHAP 简介》中,我们探讨了如何使用 Python 应用此方法。
希望这篇文章对你有所帮助!你还可以阅读我的其他文章,或者查看有关企业 AI 实战项目的教程,相信会让你拥有更多收获。
「AI秘籍」系列课程:

参考
C. Molnar, Interpretable Machine Learning (2021), https://christophm.github.io/interpretable-ml-book/
S. Masís, Interpretable Machine Learning with Python (2021)
Greenwell, B.M., Boehmke, B.C. and McCarthy, A.J., (2018) . A simple and effective model-based variable importance measure. https://arxiv.org/abs/1805.04755
ICEbox,https://cran.r-project.org/web/packages/ICEbox/ICEbox.pdf↩︎
iml, https://cran.r-project.org/web/packages/iml/iml.pdf↩︎
vip, https://www.rdocumentation.org/packages/vip/versions/0.3.2↩︎
PartialDepenceDisplays, https://scikit-learn.org/stable/modules/generated/sklearn.inspection.PartialDependenceDisplay.html↩︎
ICEbox,https://cran.r-project.org/web/packages/ICEbox/ICEbox.pdf↩︎
iml, https://cran.r-project.org/web/packages/iml/iml.pdf↩︎
vip, https://www.rdocumentation.org/packages/vip/versions/0.3.2↩︎
Github, R, https://github.com/hivandu/public_articles/blob/main/src/interpretable_ml/PDPs_and_ICE_Plots/PDP_ICE.R↩︎
Github, Python, https://github.com/hivandu/public_articles/blob/main/src/interpretable_ml/PDPs_and_ICE_Plots/PDP_ICE.ipynb↩︎
PartialDepenceDisplays, https://scikit-learn.org/stable/modules/generated/sklearn.inspection.PartialDependenceDisplay.html↩︎
PDPbox, https://pdpbox.readthedocs.io/en/latest/index.html?highlight=importance#the-common-headache↩︎
PDP 和 ICE 图的终极指南

