Python 中的 SHAP 简介
本文中有多篇计划文章,后期会补充相关链接。鉴于公众号内无法后期修改文章,请关注原文链接。
如何创建和解释 SHAP 图:瀑布图、力图、平均 SHAP 图、蜂群图和依赖图
可直接在橱窗里购买,或者到文末领取优惠后购买:
SHAP 是用于理解和调试模型的最强大的 Python 包。它可以告诉我们每个模型特征对单个预测的贡献。通过汇总 SHAP 值,我们还可以了解多个预测的趋势。只需几行代码,我们就能识别和可视化模型中的重要关系。
我们将介绍用于计算和显示 SHAP 值的代码。其中包括对以下 SHAP 图的解释:
- Waterfall Plot
- Force Plot
- Mean SHAP Plot
- Beeswarm Plot
- Dependence Plot
我们针对预测连续目标变量的模型执行此操作。如果你需要分类的解释,日后会专门写相关文章,届时可以参阅 [[二元和多类目标变量的 SHAP]],你可以在 GitHub1 上找到完整的项目。
数据集
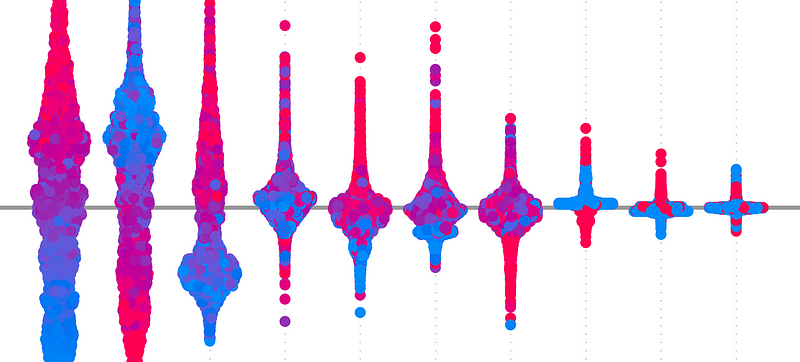
为了演示 SHAP 包,我们将使用包含 4,177 个观测值的「鲍鱼数据集」2。下面,你可以看到我们的数据集的快照。鲍鱼是一种贝类美食。我们想使用数据集来预测它们的年龄。更具体地说,我们的目标变量是鲍鱼壳中的环数。我们将使用shell length、shell diameter
和鲍鱼的 whole weight 等特征。

在下图中,我们直观地展示了一些特征与目标变量之间的关系。
Shucked weight
是鲍鱼肉的重量(即从壳中取出后的重量)。我们可以看到,去壳重量增加时,环的数量往往会增加。这是有道理的,因为我们认为年龄较大的鲍鱼会更大,肉也更多。

我们还可视化了鲍鱼的性别,这是一个分类特征。在模型中使用此功能之前,我们需要使用 One-Hot 编码对其进行转换。正如你所看到的,这会导致每个生成的二进制特征都有一个单独的 SHAP 值。这使得很难理解原始分类特征的整体贡献。我们将在后面专门写一篇文章「分类特征的 SHAP」探讨一种解决方案。
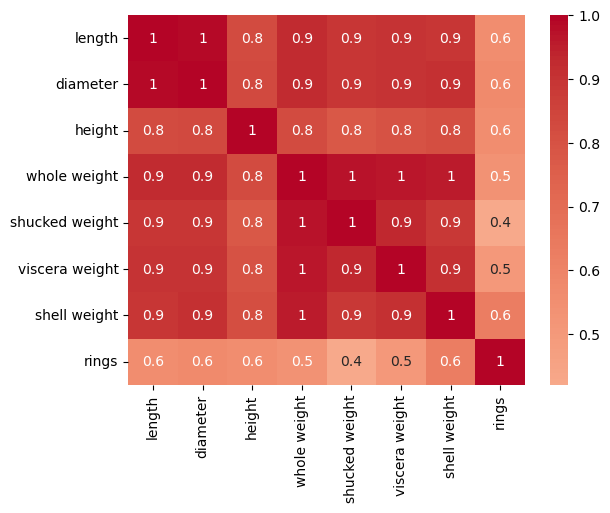
对于最后一点数据探索,我们为连续特征创建一个相关矩阵。 可以看到,我们正在处理高度相关的特征。 长度和直径完全相关。 同样,全重与其他重量测量值也高度相关。 例如肉的重量(去壳重量)和除去肉的外壳重量(外壳重量)。
包
我们在下面导入必要的 Python 包。我们有一些用于管理和可视化数据的标准库(第 4-9 行)。XGBoost 用于对目标变量进行建模(第 13 行),我们导入一些包来评估我们的模型(第 14 行)。最后,我们导入 SHAP 包(第 16 行)。我们初始化包(第 17 行)。这样我们就可以在笔记本中显示一些 SHAP 图。
1 | |
建模
我们使用数据探索来指导特征工程。首先,我们从 X 特征矩阵中删除长度和整体重量(第 10-11 行)。我们发现这些与其他特征完美相关。
1 | |
我们看到性别是一个分类特征。在将其用于模型之前,我们需要将其转换为 3 个虚拟变量(第 2-4 行)。然后,我们从特征矩阵中删除原始特征(第 5 行)。
1 | |
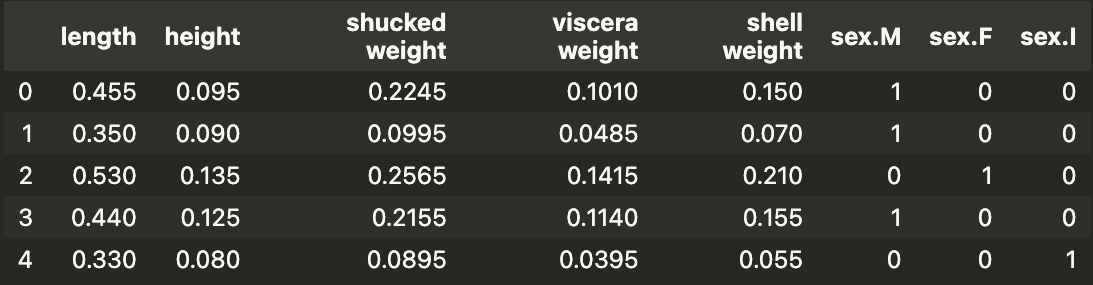
我们现在有 8 个模型特征。你可以在下面看到这些特征的快照。
现在,我们可以训练一个用于预测鲍鱼壳环数的模型。由于我们的目标变量是连续的,因此我们使用XGBRegressor(第
2 行)。我们在整个特征集上训练模型(第 3 行)。
1 | |
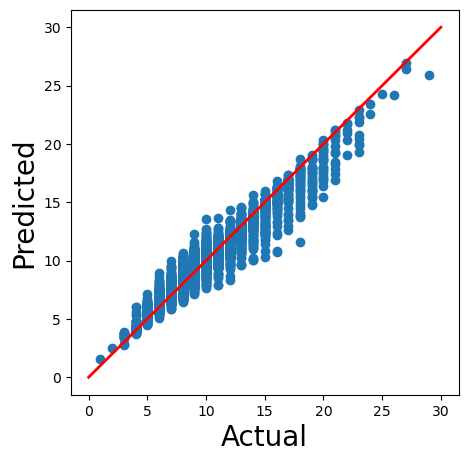
这个模型应该足以演示 SHAP 包。我们可以通过使用图 3 中的散点图对其进行评估来看到这一点。我们正在将模型的预测(第 2 行)与实际环数进行比较。红线给出了如果我们有完美预测的值。
注意:我们没有在模型上投入太多精力。除非你使用 SHAP 进行数据探索,否则你应该始终使用最佳实践。你的模型越好,你的 SHAP 分析就越可靠。
SHAP 图
最后,我们可以使用 SHAP 值来解释这个模型。为此,我们将模型传递给
shap.Explainer器函数(第 2
行)。这将创建一个解释器对象。我们使用它来计算特征矩阵中每个观测值的
SHAP 值(第 3 行)。
1 | |
图 1:Waterfall
特征矩阵中的 4,177 个观测值中的每一个都有 8 个 SHAP
值。也就是说,我们模型中的每个特征都有一个 SHAP 值。我们可以使用
waterfall 函数来可视化第一个观测值的 SHAP 值(第 2
行)。
1 | |
E[f(x)] = 9.933 给出了所有 4,177
只鲍鱼的平均预测环数。f (x) = 12.668是这只鲍鱼的预测环数。SHAP
值是介于两者之间的所有值。例如,去壳重量使预测环数增加了1.68
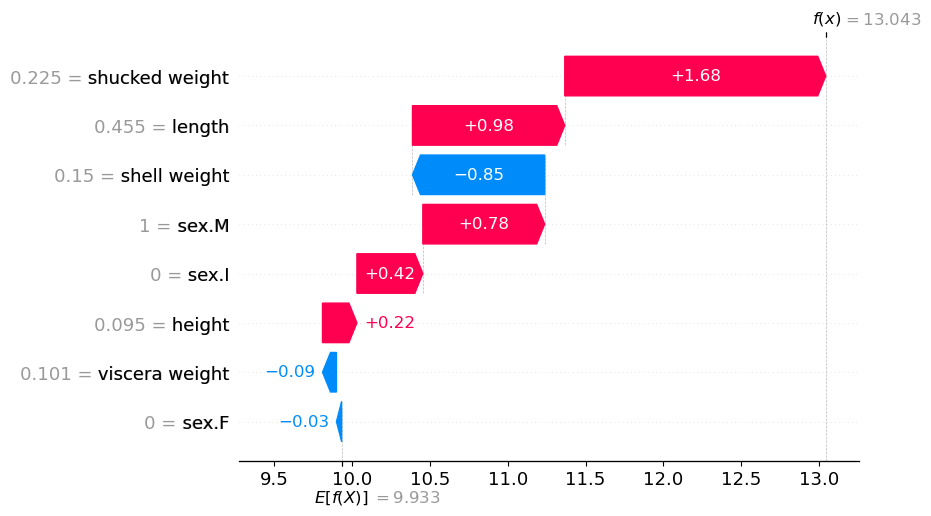
我们数据集中的每个观测/鲍鱼都会有一个独特的瀑布图。它们都可以用与上述相同的方式进行解释。在每种情况下,SHAP 值告诉我们与平均预测相比,特征对预测的贡献如何。较大的正/负值表示该特征对模型的预测有显著影响。
图 2:Force Plot
另一种可视化方法是使用力图。你可以将其视为浓缩的瀑布图。我们从相同的基值9.933开始,你可以看到每个特征对最终预测
13.04 的贡献。
1 | |

图 3:叠加 Force Plot
瀑布图和力图非常适合解释单个预测。要了解我们的模型如何进行总体预测,我们需要汇总 SHAP 值。一种方法是使用堆叠力图
我们可以将多个力图组合在一起以创建堆叠力图。在这里,我们在力图函数中传递前 100 个观测值的 SHAP 值。每个单独的力图现在都是垂直的并且并排堆叠。
1 | |
你可以在下面看到此图是交互式的。我们还可以更改图的顺序并选择要显示的特征贡献。

例如,在下面的图中我们有:
仅显示壳重量的
SHAP 值(y 轴 = **shell weight effects )
按壳重量特征值对力图进行排序(x 轴 =
**shell weight)
从该图中我们可以看出,随着壳重的增加,SHAP 值也会增加。换句话说,年龄较大的鲍鱼壳往往更重。

这是了解我们的模型所捕获关系的性质的一种方法。我们将看到蜂群图和依赖图也可以以这种方式使用。
图 4:Mean SHAP
下一个图将告诉我们哪些特征最重要。对于每个特征,我们计算所有观测值的平均 SHAP 值。具体来说,我们取绝对值的平均值,因为我们不希望正值和负值相互抵消。最后,我们得到下面的条形图。每个特征都有一个条形图。例如,我们可以看到壳重量具有最大的平均 SHAP 值。
1 | |
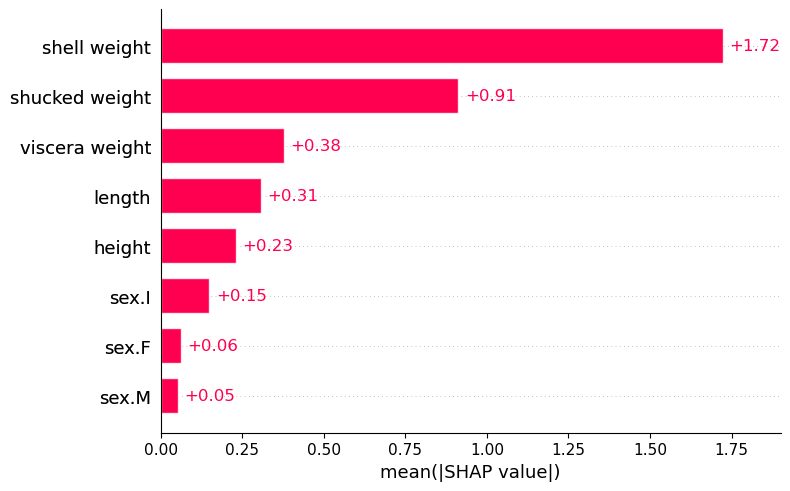
具有较大正/负贡献的特征将具有较大的平均 SHAP 值。换句话说,这些特征对模型的预测产生了重大影响。从这个意义上讲,此图的使用方式与特征重要性图相同。
图 5:Beeswarm
接下来,我们得到了最有用的图表。蜂群将所有 SHAP 值可视化。在 y 轴上,这些值按特征分组。对于每个组,点的颜色由特征值决定(即,特征值越高,颜色越红)。
1 | |
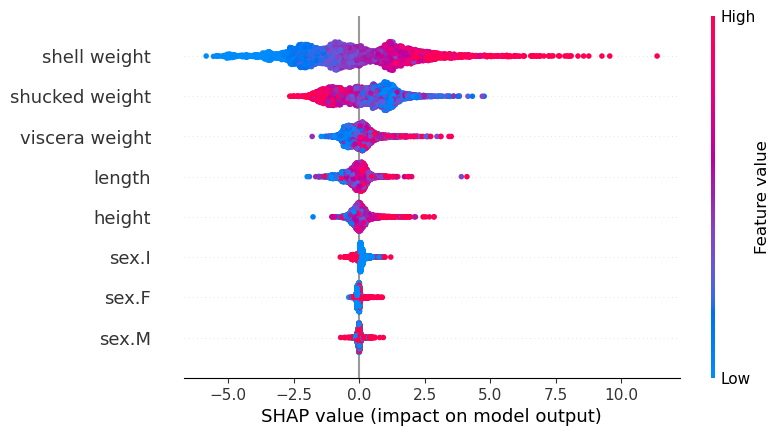
与平均 SHAP 一样,蜂群可用于突出重要关系。事实上,上图中的特征是按平均 SHAP 排序的。
我们也可以开始理解这些关系的性质。对于壳重,请注意 SHAP 值如何随着特征值的增加而增加。我们在堆叠力图中看到了类似的关系。它告诉我们,壳重值越大,预测的环数也就越多。
你可能已经注意到,去壳重量具有相反的关系。查看蜂群图,我们可以看到此特征的较大值与较小的 SHAP 值相关。我们可以使用依赖图仔细研究这些关系。
图 6:Dependence Plot
依赖图是单个特征的 SHAP 值与特征值的散点图。如果特征与目标变量具有非线性关系,则它们特别有用。
例如,以壳重的依赖关系图为例。查看蜂群图,我们可能假设 SHAP 值随特征值线性增加。依赖关系图告诉我们,这种关系并不是完全线性的。
1 | |
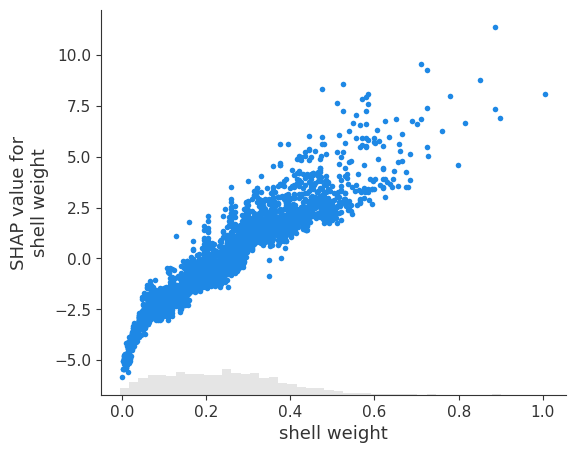
我们还可以使用第二个特征的值来为散点图着色。现在我们有了相同的图,去壳重量越大,点越红。我们可以看到,当壳重和去壳重量都很大时,SHAP 值也很大。
1 | |
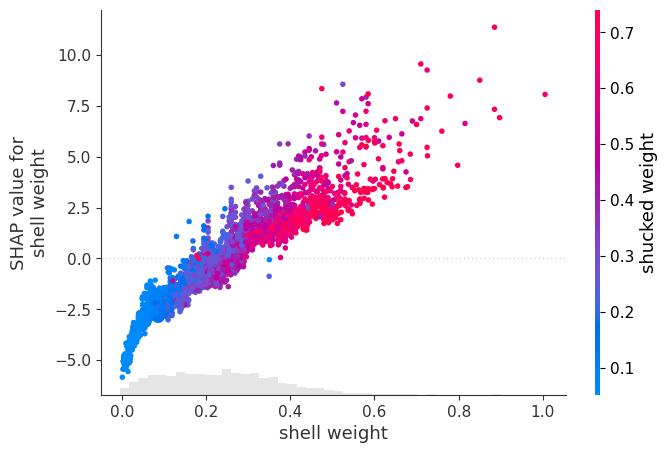
这些图可用于可视化特征之间的相互作用,但要小心!在我们的例子中,该图是两个特征之间相关性的结果。
我们还有去壳重量(即鲍鱼肉的重量)的依赖关系图。使用此图,我们可以确认我们在蜂群图中看到的关系。SHAP 值确实会随着去壳重量的增加而下降。
1 | |
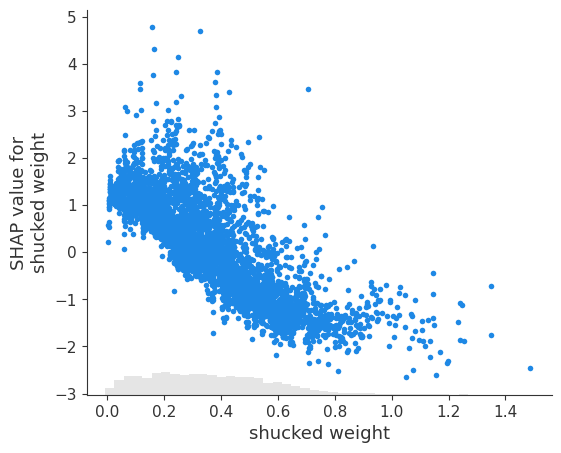
直观地看,这种关系似乎很奇怪。我们不是希望年龄较大的鲍鱼更大、肉更多吗?事实上,这是壳重和去壳重量相互作用的结果。由于相关性,我们在依赖图中看不到它。在文章《分析与 SHAP 的相互作用》中,我们探讨了如何使用 SHAP 交互值来识别此类相互作用。
SHAP 用于分类
你会很高兴地知道,分类问题的 SHAP 图与上面的非常相似。除了二元目标变量之外,我们根据对数几率来解释 SHAP 值。对于多类目标,我们使用softmax。一个缺点是我们最终会为多类目标中的每个类绘制单独的 SHAP 图。我们将在后面一篇文章中讨论了一些更好的聚合值的方法,暂定标题为[二元和多类目标变量的 SHAP],当你的模型预测分类目标变量时,代码和 SHAP 图的解释指南。
我们可以看到,SHAP 值是一种有用的工具,可用于了解我们的模型如何进行预测。然而,我们只是触及了该软件包所能提供内容的表面。如果你想了解更多信息,我日后将会写一些有关 SHAP 的文章,用于更深入地探讨了 SHAP 和 Shapley 值的某些方面,包括:
[从 Shapley 到 SHAP — 数学理解], 如何计算 SHAP 特征贡献的概述
[[KernelSHAP 与 TreeSHAP]], 根据速度、复杂性和其他考虑因素比较 SHAP 近似方法
[使用 SHAP 调试 PyTorch 图像回归模型], 使用 DeepShap 理解和改进自动驾驶汽车模型
由于本人常年使用双向链接软件写文,在粘贴的时候会时常有类似[[XXX 文章名]]的样式,这只是我文章相互连接的格式,如若不能链接到别处大概率就是还未成文发布。
AI 进阶:企业项目实战3
参考
S. Lundberg, SHAP Python package (2021), https://github.com/slundberg/shap
S. Lundberg & S. Lee, A Unified Approach to Interpreting Model Predictions (2017), https://arxiv.org/pdf/1705.07874.pdf
C. Molnar, Interpretable Machine Learning (2021) https://christophm.github.io/interpretable-ml-book/shap.html
希望这篇文章对你有所帮助!你还可以阅读我的其他文章,或者查看有关企业 AI 实战项目的教程,相信会让你拥有更多收获。
「AI秘籍」系列课程:

Python 中的 SHAP 简介

