SHAP 的局限性
SHAP 如何受到特征依赖性、因果推理和人为偏见的影响
SHAP 是最流行的 IML/XAI 方法。它是一种强大的方法,可用于了解我们的模型如何进行预测。
但不要让受欢迎程度说服你。
SHAP 仍有局限性。使用该方法得出结论时需要牢记这些局限性。
我们将讨论 4 个重要的限制:
- 第一个来自 SHAP 包本身
- 第二个来自于 SHAP 值的计算方式——我们假设特征是独立的
- 第三个是我们如何使用它们——不是为了因果推理
- 最后一点来自于人类使用它们的方式——我们编造故事
1 SHAP 包
第一个与 SHAP 包本身有关。内核 SHAP 在理论上是一种与模型无关的方法,但这并不意味着它在实践中也是与模型无关的。为什么?因为它尚未在所有包中实现。
就我个人而言,我已经将该软件包与 5 个建模软件包一起使用:Scikit learns、XGBoost、Catboost、PyTorch 和 Keras。请记住,如果你使用的是不太流行的建模框架,可能会遇到一些麻烦。即使是深度学习软件包,SHAP 也可能相当不稳定。我很难让它与 PyTorch 一起工作
2 特性依赖性
特征依赖性是指两个或多个模型特征相关联或相关。也就是说,一个特征的值取决于另一个特征的值。SHAP 以两种方式受到特征依赖性的影响。
第一个问题来自于 SHAP 值的近似方法。以 KernelSHAP 为例。该方法通过排列特征值并对这些排列进行预测来工作。一旦我们有足够的排列,就可以使用线性回归来估计 Shapley 值。问题是,在排列特征时,我们假设它们是独立的。
与许多其他基于排列的解释方法一样,当特征相关时,Shapley 值方法会包含不切实际的数据实例。
— 克里斯托夫·莫尔纳
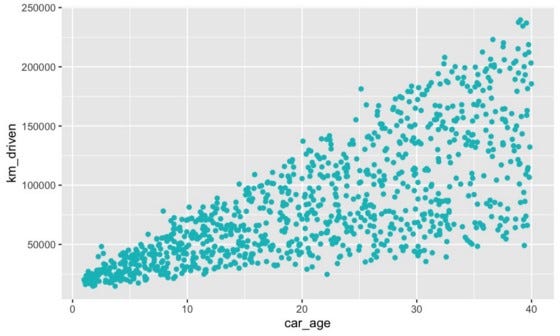
这个假设并不总是正确的。以图 1 中的 km_driven 和
car_age
散点图为例。这些特征用于预测二手车的价格。它们之间存在明显的相关性。车越旧,我们增加其行驶里程的时间就越多。
现在以图 2 中的红色观察结果为例。这辆车已有 10 年车龄。这个年龄的汽车将在实心椭圆内行驶距离。当模型经过训练时,它只会“看到”这些现实的观察结果。
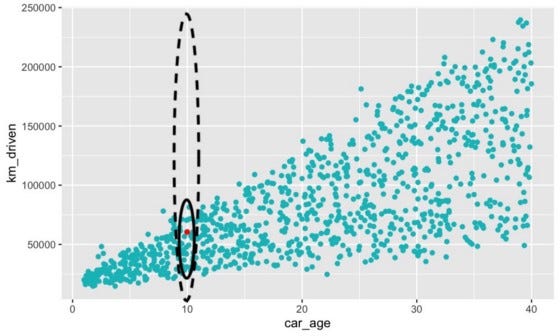
然而,在计算 SHAP 值时,我们会在整个范围内对特征进行置换。对于
km_driven,
这包括虚线内的不切实际的观察结果。我们期望模型对这些观察结果做出预测。这可能会导致不可靠的预测和
SHAP 值。
在解释 SHAP 图时,特征依赖性也会导致一些混乱。例如,模型可以使用原籍国来预测患皮肤癌的几率。某些国家的人是否易患皮肤癌?防晒霜是否更贵?不,这是因为每个国家的日照水平不同。
原籍国被称为代理变量。模型使用它们的原因可能并不明显。归根结底,这是因为机器学习只关心相关性,而代理变量与事件的真实原因相关。这引出了我们的第二个限制。
3 因果推理
SHAP 值不能用于因果推理。这是寻找事件/目标的真正原因的过程。SHAP 值告诉我们每个模型特征对预测的贡献。它们没有告诉我们特征对目标变量的贡献。这是因为模型不一定能很好地代表现实。
Shap 不是衡量“现实世界中某个特征有多重要”的标准,它只是衡量“某个特征对模型有多重要”。—— Gianlucca Zuin
预测可能不正确。在这种情况下,SHAP 值将对与真实目标不同的预测做出贡献。如前所述,即使模型 100% 准确,也可能使用代理变量。所有这些都意味着我们不应该得出超出模型范围的结论。即使这样做很诱人……
4 人为错误
从技术分析到占星术,人类喜欢寻找实际上并不存在的特征。数据科学也不例外。
在分析 SHAP 值时,我们可能会产生错误的叙述。为什么该模型预测癌症发病率很高?一定是因为帽子不流行了!
即使这些故事来自模型怪癖,我们也可以强行将这些故事强加到分析中。由于确认偏差,我们可以无意识地这样做。它也可以恶意地支持对某人有利的结论。这类似于 p-hacking 的过程。我们反复修改数据和模型,直到它们给我们想要的结果。
确认偏差——无意识地偏向那些证实你先前信念的信息
最后,所有这些限制都应该增加你对使用 SHAP 得出的结论的怀疑。结论可能基于对特征独立性的错误假设。永远不要接受超出模型范围的结论——尤其是当它支持别有用心时。
我们总体上研究了 SHAP 的局限性。不同的近似方法会有各自的特定局限性。例如,KernelSHAP 速度很慢。TreeSHAP 速度更快,但它与模型无关。我们在文章《KernelSHAP 与 TreeSHAP》中讨论这些和其他考虑因素。
参考
S. Lundberg, SHAP Python package (2021), https://github.com/slundberg/shap
S. Lundberg & S. Lee, A Unified Approach to Interpreting Model Predictions (2017), https://arxiv.org/pdf/1705.07874.pdf
C. Molnar, Interpretable Machine Learning (2021), https://christophm.github.io/interpretable-ml-book/
S. Masís, Interpretable Machine Learning with Python (2021)
Chandan Durgia Using SHAP for Explainability — Understand these Limitations First (2021) https://towardsdatascience.com/using-shap-for-explainability-understand-these-limitations-first-1bed91c9d21
SHAP 的局限性

