最好的学习就是输出,所以虽然这个预测很多人做过了,我还是在这里再做一遍,纯粹是为了自己学习.
前言
这次预测使用的是 Sklearn 中的决策树模型:
1
| clf = DecisionTreeClassifier(criterion='entropy')
|
其中 criterion 是标准,决定了构造分类树是采用 ID3 分类树还是 CART
分类树,对应的取值分别是entropy和gini
entropy: 基于信息熵,也就是 ID3 算法, 实际结果与 C4.5
相差不大;
gini: 默认参数,基于基尼系数. CART
算法是基于基尼系数做属性划分的,所以criterion=gini时,
实际上执行的是 CART 算法.
其完整参数:
1
2
3
4
5
6
| DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
|
参数代表的含义如下表:
criterion |
在基于特征划分数据集合时,选择特征的标准。默认是
gini,也可以是entropyo |
splitter |
在构造树时,选择属性特征的原则,可以是best或者
random。默认是best,best代表在所有的特征中选择最
好的,random代表在部分特征中选择最好的。 |
max_depth |
决策树的最大深度,我们可以控制决策树的深度来防止 决策树过拟合 |
max_features |
在划分数据集时考虑的最多的特征值数量。为int或float类型。其中int值是每次split时最大特征数;float值是百
分数,即特征数=max_features * n_featureso |
min_samples_split |
当节点的样本数少于min_samples_split时,不再继续分
裂。默认值为 2 |
min_samples_leaf |
叶子节点需要的最少样本数。如果某叶子节点数目小于
这个阈值,则会和兄弟节点一起被剪枝。
min_samples_leaf的取值可以是int或float类型。
int类型:代矗小样本数;
float 类型:表示一个百分比,这是最小样本数
=min_samples_leaf乘以样本数量,并向上取整。 |
max_leaf_nodes |
最大叶子节点数。int类型,默认为None。
默认情况下是不设置最大叶子节点数,特征不多时,不
用设置。特征多时,可以通过设置最大叶子节点数,防 止过拟合。 |
min_impurity_decrease |
节点划分最小不纯度。float类型,默认值为0。
节点的不纯度必须大于这个阈值,否则该节点不再生成
子节点。通过设置,可以限制决策树的增长。 |
minjmpurity_split |
信息増益的阀值。信息増益必须大于这个阀值,否则不 分裂。 |
class_weight |
类别权重。默认为None,也可以是diet或balanced。
diet类型:指定样本各类别的权重,权重大的类别在决策
树构造的时候会进行偏倚。
balanced:算法自己计算权重,样本量少的类别所对应
的样本权重会更高。 |
presort |
bool类型,默认是false,表示在拟合前,是否对数据进
行排序来加快树的构建。当数据集较小时,使用
presort=true会加快分类器构造速度。当数据集庞大
时,presort=true会导致整个分类非常缓慢。 |
在构造决策树分类器后,我们可以使用 fit 方法让他分类器进行拟合,
使用predict方法对新数据进行预测, 得到预测的分类结果,
也可以使用score方法得到分类器的准确率.
fit、predict和score方法的作用如下表:
| fit(features, labels) |
通过特征矩阵, 分类表示,让分类器进行拟合 |
| predict(features) |
返回预测结果 |
| score(features, labels) |
返回准确率 |
本次数据集一共两个,一个是train.csv, 用于训练,
包含特征信息和存活与否的标签, 一个是test.csv, 测试数据集,
只包含特征信息.
训练集中,包括了以下字段:
| Passengerld |
乘客编号 |
| Survived |
是否幸存 |
| Pclass |
船票等级 |
| Name |
乘客姓名 |
| Sex |
乗客性别 |
| SibSp |
亲戚数虽(兄妹、配偶数) |
| Parch |
亲戚数虽(父母、子女数) |
| Ticket |
船票号码 |
| Fare |
船票价格 |
| Cabin |
船舱 |
| Embarked |
登陆港口 |
流程
整个流程可以划分为三个阶段:
- 获取数据
- 准备阶段
- 数据探索
- 数据清洗
- 特征选择
- 分类阶段
- 决策树模型
- 模型评估&预测
- 决策树可视化
获取数据
这一步还包含了引入所需依赖
1
2
3
4
5
6
7
8
9
10
11
12
|
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.tree import DecisionTreeClassifier
import os
path = os.path.expanduser('~/data/python/Titanic_Data/')
train_data = pd.read_csv(path + 'train.csv')
test_data = pd.read_csv(path + 'test.csv')
|
准备阶段
对数据进行探索,分析数据质量,并对数据进行清洗,然后通过特征选择对数据进行降维,
以便于之后进行分类运算;
数据探索
1
2
3
4
5
6
| train_data.info()
train_data.describe()
train_data.describe(include=['O'])
train_head(5)
train_tail(5)
train_sample(5)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
None
------------------------------
PassengerId Survived ... Parch Fare
count 891.000000 891.000000 ... 891.000000 891.000000
mean 446.000000 0.383838 ... 0.381594 32.204208
std 257.353842 0.486592 ... 0.806057 49.693429
min 1.000000 0.000000 ... 0.000000 0.000000
25% 223.500000 0.000000 ... 0.000000 7.910400
50% 446.000000 0.000000 ... 0.000000 14.454200
75% 668.500000 1.000000 ... 0.000000 31.000000
max 891.000000 1.000000 ... 6.000000 512.329200
[8 rows x 7 columns]
------------------------------
Name Sex ... Cabin Embarked
count 891 891 ... 204 889
unique 891 2 ... 147 3
top Peter, Mrs. Catherine (Catherine Rizk) male ... B96 B98 S
freq 1 577 ... 4 644
[4 rows x 5 columns]
------------------------------
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.2500 NaN S
1 2 1 1 ... 71.2833 C85 C
2 3 1 3 ... 7.9250 NaN S
3 4 1 1 ... 53.1000 C123 S
4 5 0 3 ... 8.0500 NaN S
[5 rows x 12 columns]
------------------------------
PassengerId Survived Pclass ... Fare Cabin Embarked
886 887 0 2 ... 13.00 NaN S
887 888 1 1 ... 30.00 B42 S
888 889 0 3 ... 23.45 NaN S
889 890 1 1 ... 30.00 C148 C
890 891 0 3 ... 7.75 NaN Q
[5 rows x 12 columns]
------------------------------
PassengerId Survived Pclass ... Fare Cabin Embarked
619 620 0 2 ... 10.5000 NaN S
330 331 1 3 ... 23.2500 NaN Q
647 648 1 1 ... 35.5000 A26 C
716 717 1 1 ... 227.5250 C45 C
860 861 0 3 ... 14.1083 NaN S
[5 rows x 12 columns]
|
数据清洗
探索之后, 我们发现 Age、Cabin 这两个字段的数据有缺失.
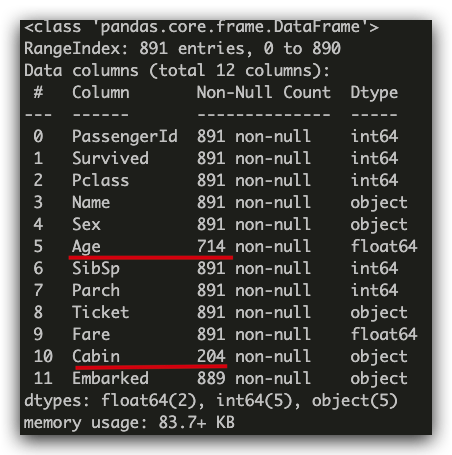
其中, Cabin 为船舱, 有大量的缺失值, 在训练集和测试集中的缺失率分别为
77%和 78%, 无法补齐, Age 可以获取平均值进行补齐, 而 Embarked 是登陆港口,
这个字段也有少量(2 个)缺失值, 可以使用最大数据进行补齐.
1
2
3
4
5
| train_data['Age'].fillna(train_data['Age'].mean(), inplace=True)
test_data['Age'].fillna(test_data['Age'].mean(), inplace=True)
train_data['Embarked'].fillna(train_data['Embarked'].value_counts().idxmax(), inplace=True)
test_data['Embarked'].fillna(test_data['Embarked'].value_counts().idxmax(), inplace=True)
|
分类阶段
特征选择
需要选择有用的字段作为特征,这一步其实很重要:
1
2
3
4
5
6
7
8
9
|
train_data.columns
features = ['Pclass', 'Sex', 'Age', 'SibSp', 'Fare', 'Parch', 'Embarked']
train_features = train_data[features]
test_features = test_data[features]
train_labels = train_data['Survived']
|
这中间有一些事字符串字段, 是不适合进行后续运算的,
需要在这里转变为数值类型,比如 Sex 字段, 男女两种取值需要转变成 0 和
1
再比如 Embarked 有 S, C, Q 三种可能, 我们可以改成 Embarked=S,
Embarked=C, Embarked=Q 三个字段,然后用数值 0 和 1 来表示, 其中 sklearn
特征选择中的 DictVectorizer 类(上面已引入依赖),
可以处理符号化的对象, 将符号转变为 0/1 进行表示:
1
2
| dvec=DictVectorizer(sparse=False)
train_features=dvec.fit_transform(train_features.to_dict(orient='record'))
|
fit_transform这个函数可以讲特征向量转化为特征值矩阵,
我们查看下:
1
2
3
|
['Age', 'Embarked=C', 'Embarked=Q', 'Embarked=S', 'Fare', 'Parch', 'Pclass', 'Sex=female', 'Sex=male', 'SibSp']
|
我们讲 Embarked 转化为三列
(['Embarked=C', 'Embarked=Q', 'Embarked=S']), Sex
变为了两列 ([Sex=female', 'Sex=male'])
决策树模型
1
2
3
4
|
clf=DecisionTreeClassifier(criterion='entropy')
clf.fit(train_features, train_labels)
|
模型预测 & 评估
我们首先得到测试集的特征值矩阵, 然后使用训练好的决策树 clf 进行预测,
得到预测结果:
1
2
3
| test_features=dvec.transform(test_features.to_dict(orient='record'))
pred_labels=clf.predict(test_features)
|
模型评估中,决策树提供了 score
函数直接得到准确率,但是我们并不知道真实的预测结果,所以无法用预测值和真实的预测结果做比较,
需要使用训练机中的数据进行模型评估, 可以使用决策树自带的 score
函数计算:
1
2
3
| # 得到决策树准确率
acc_decision_tree=round(clf.score(train_features, train_labels), 6)
acc_decision_tree
|
其实,以上准确率评估并不准确,因为我们用训练集做了训练,再用训练集做准确率评估,
并不能代表决策树分类器的准确率.
要统计决策树分类器的准确率, 可以使用 K 折交叉验证,
cross_val_score 函数中的参数 cv
代表对原始数据划分成多少份,也就是我们的 K 值,一般建议 K 值取
10,因此我们可以设置 CV=10
1
2
3
4
| import numpy as np
from sklearn.model_selection import cross_val_score
np.mean(cross_val_score(clf, train_features, train_labels, cv=10))
|

