01. BI - Project one, 员工离职预测

[TOC]
Hi,你好。我是茶桁。
又是开始了一个新的阶段。我不建议一些没基础的同学直接从这里开始,还是要先去之前的课程里补补基础。有的时候即便依葫芦画瓢的把代码写出来了,但是基本原理不清楚。而有的时候,则可能听都听不懂。
好了,接下来的课程里,我给大家讲解一下机器学习的预测神器。就是是 XGBoost,LightGBM 以及 CatBoost 这样的一些方法。这个方法在后续的机器学习工作中会经常使用到。不光是在工作中使用,如果你打一些比赛,也是一个必知必会的模型,基本上属于 TOP3 的级别。
在讲解机器学习神器之前要给大家看一看比较常见的预测的全家桶。
首先先看一个题目,这个数据是一个「员工离职的预测」,第二个项目是关于「男女声音的识别」。这两个项目里面我们都是要做一些分类任务,所以会有一些分类算法的讲解,包括 LR,SVM 和 KNN。矩阵分解我们会用到,FunkSVD, BiasSVD 以及 SVD++, 还有就是树模型,除了上面我提到的神器之外,还有 GBDT 以及 NGBoost。
那三种机器学习的神器应该是属于必知必会的内容,未来在工作中基本上大家都掉包就可以。那很多人都知道,我们的工作会被戏称为掉包侠,这个是你入职之后可以调包,但是入职之前面试官经常会考一些问题,考察一下你对原理是不是了解。我建议大家第一次学习的时候还是要了解一下它背后的一些原理,这样使用的时候你会更有感觉。
我在这第一节课上先做一个调查,就是小伙伴们对这 3 种方法有了解的同学可以在下面进行留言。那我们还是先要去了解原理再去理解工具的使用。在项目中我们会使用这些工具去解决我们的问题。
接下来,咱们先看一张图:
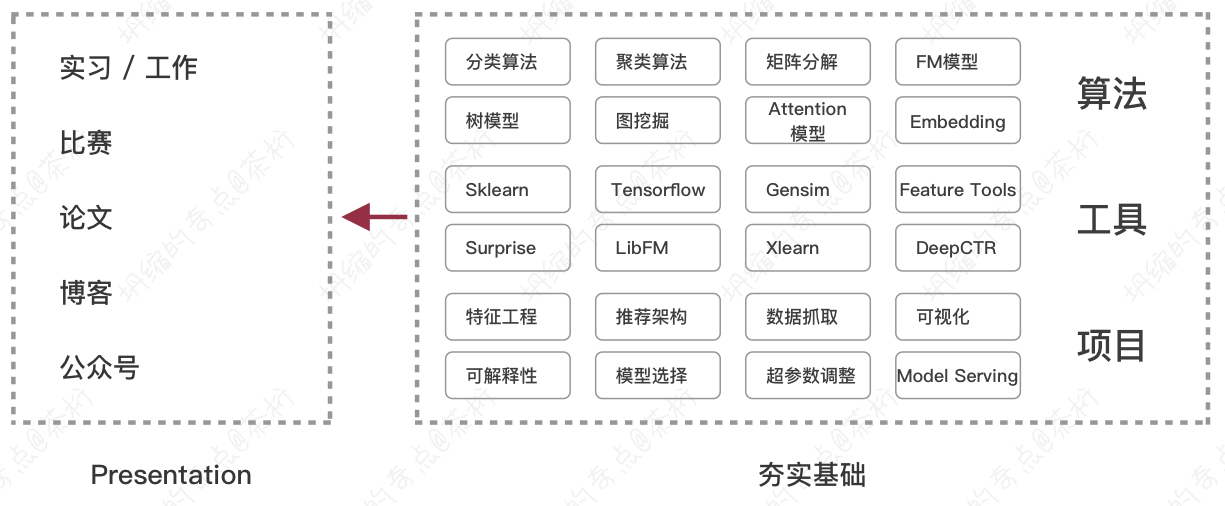
最后如果要找工作的话,要竞争,背后的这个基础就是算法的原理、工具的使用、简历中的项目经验。有了这样一些基础以后去找工作才会更加有竞争性,尤其现在咱们这个大环境下,属于岗位少,但是竞争的人数多。一个职位可能会有多个人一起去竞争,那面试官一定会考核各个方面的部分,尤其在面试的时候也可能会问到一些算法的原理。
那首先咱们还是先来看看咱们的预测全家桶。
项目概要
先从第一个项目开始
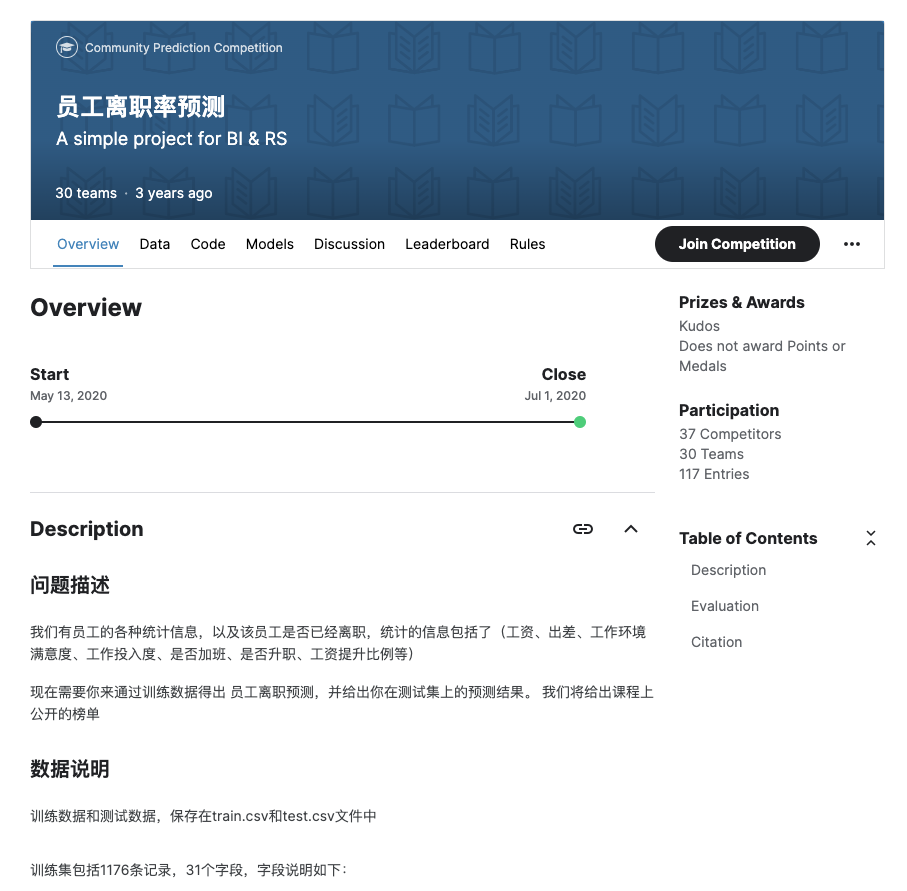
这个项目是来自于 Kaggle 开过的一场比赛,大家可以去这里去查看项目本身,也可以在这里下载相关数据集:https://www.kaggle.com/competitions/bi-attrition-predict/
题目要做的是员工离职预测,有一些员工的属性,这些属性包括了公司、出差信息、工作满意度、投入度、加班等等。大概有 31 个 feature,这 31 个 feature 要去预测那个 y, target,一会儿可以看一看咱们这个 target 是什么,大家可以跟我一起来看一下。
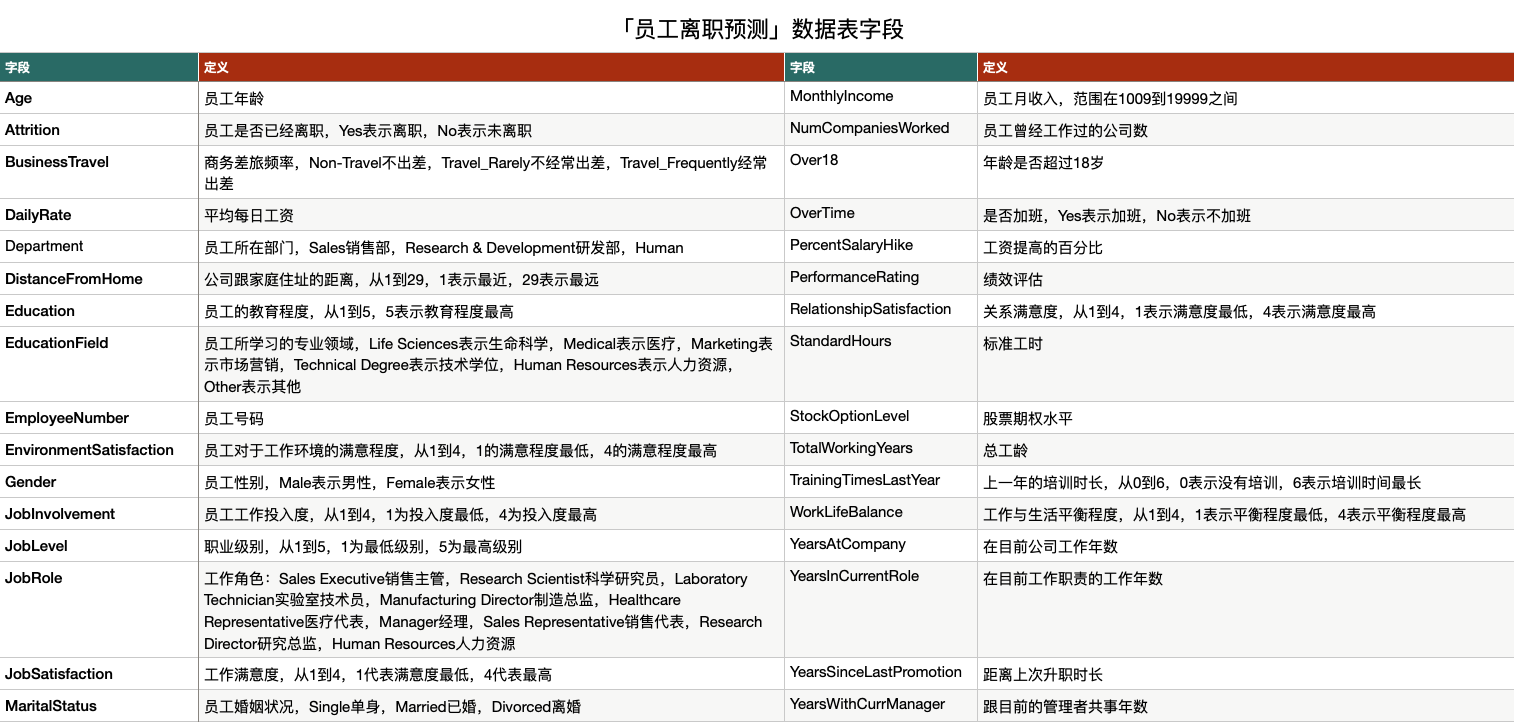
这些数据的字段,Age, Attrition, businessTravel 等等,那想从这里面的词段里面找到一下我们要预测的那个字段,看一看是哪一个字段。
我们要做的任务是员工离职预测任务,首先拿到这个题目要思考的问题是我们要去选用怎样的模型。我们当前的任务应该是典型的分类任务,而且是一个 2 分类问题。我们需要预测它是 yes 还是 no。所以,我们要预测 Attrition 字段。除此之外,所有此段都属于它的特征,大概是在 31 个特征维度。
这些特征一般来说把它分成两种,一种叫做类别,还有一种叫做数值。关于类别和数值有什么区别,我们曾经在机器学习的篇章里给大家有详细的解释。
来看一看哪些是类别特征,第 3 个字段 businessTravel,应该属于类别特征,是一个三分类的特征。那第四个字段 DailyRate,这个可能就是一个数值类型。所以变量可以把它分成类别特征和数值类型特征。这两种之间还是有比较明显的区别的。
有些时候我们可以看一看,比如 WorkLifeBalance, 工作与生活平衡程度, 1-4。那咱们分析一下,这样的一个词段是类别特征还是数值类型?有些情况我们看到它也是个数字啊,1-4,从这个个数去看的话我们可以把它看成分类,更接近于类别。但是这种类别特征又有区别于我们以往的类别特征。因为 1-4 的话,它是有顺序关系的,所以它又具有数值的一些属性、数值特征,就是一个明显的数顺序关系。
所以可以把它理解成是有顺序关系的类别特征。在处理的过程中可以把它看成四个分类,这是没有问题的。但是在运算逻辑上我们要取它的数值大小,不能把它再去做一遍。所以它是属于一个特殊的一个维度。
针对这个项目怎么做呢?
常用预测(分类、回归)模型: 1. 分类算法: LR, SVM, KNN 2. 矩阵分解: FunkSVD, BiasSVD, SVD++ 3. FM 模型:FM,FFM,DeepFM,NFM,AFM 4. 树模型: GBDT, XGBoost, LightGBM, CatBoost, NGBoost 5. Attention 模型: DIN,DIEN,DSIN
我们要看一看预测模型有哪些,典型的机器学习分类器有 LR,这个 LR 应该把它称为叫做 logistic regression,逻辑回归。还有 SVM 和 KNN,这些是属于传统机器学习的方法。除了这个以外我们还有一些,像 CART 决策树,这些也都属于机器学习的方法。
矩阵分解它也是一种预测模型,在推荐系统里面我会给大家进行讲解,后面会有详细的推荐系统的章节会使用到。
还有推荐系统里面会使用到的 FM 模型,矩阵分解和 FM 模型都是在推荐算法里面。
树模型呢,跟分类器是一样的,这两个部分都可以做分类任务,也可以做回归任务。
Attention 是属于一种技术,它也是在推荐系统里面。
整个处理这道问题的流程,脑海中要先想到我们可以采用哪些模型。就是第 1 个类别分类任务,还有第 4 个树模型,这些是可以使用的。
模型要使用的话基本上掉包就可以了,所以大家可以思考一下区别,如果你要得到一个很好的成绩区别在哪?区别是在于模型的使用还是在于特征工程的一个拆解?
模型使用基本上如果参加项目的时候都掉包,而且参数可能也不会有太大的变化,所以区别应该是在于前面,就是特征工程,好的特征工程是拿分的关键。
在工作里面也是一样,这 31 个特征能不能再做一些组合,看看哪些特征之间给你更多的一些启发。所以特征工程在工作中、在项目的比赛中都很关键。这个先记住,这是它的特征工程重要性。
那我们先看一看模型。第一类的模型像 LR,SVM 和 KNN。先通体上介绍一下,我们怎么去使用这些模型来进行求解。
数据集处理
拿到这个程序,我们前面这个模块是要读取数据,有训练集和测试集,把数据读取进来。
1 | |
在模型调包之前,还有一项任务是要做数据的探索。数据探索的目的就是看一看这个数据长什么样,给你直观的一个感受。最直接的就是看
label,比如Attrition里面它到底长什么样。
1 | |
非离职的 988,离职的 188。所以我们可以看到,这个二分类应该是属于不平衡的。就是不离职的类别特征会更多一点,而且它还不是数值类型,如果不是数值类型还要做一个映射处理,所以咱们下面做一个映射处理。yes 变为 1,no 变为 0,这样就会把它转化成数值类型。
1 | |
还有一些数据探索比较关键是看一看我们的缺失值的个数。这个我们用isna.sum()来进行判断。
1 | |
可以看到数据还是比较完善的,没有什么缺失值。如果缺失值的话在模型预测之前可能需要做一个缺失值补全的任务。
在探索过程中能发现一个问题,就是有个字段叫EmployeeNumber,这个字段是员工号码,对我们的这个判断来说这个字段应该是没有意义的。为什么没有意义我们可以通过
value counts 来看一看。
1 | |
她没有太多其他维度的特征,所以这个字段在入模之前可以给它 drop 掉。
1 | |
还有,StandardHours觉得有意义吗? 它都等于 80, 一共是
1,176 个人,所有值都一样。那我们一样,可以给它去掉。就变成:
1 | |
这里,我们对训练集和测试集采用同样的操作,直接给它 drop 掉了。
这其中的属性axis=1是表示按列的方式进行操作。
我们找一找分类特征, 分类特征有一种方式, 我们可以将它的 info 属性打印出来看看。
1 | |
里面有一个
Dtype,这个值就是表示是什么类型的数据,如果是int64代表的就是数值类,那就不属于类别,我们就把object类型给它取出来。
1 | |
这些类别特征是通过筛选 object 类型来去提出来的,这个是直接写出来了,都属于类别特征。类别特征它就不属于数值类型,在机器学习入模之前,需要把它转换成为数值类型。
我们可以使用 one-hat
编码,除此之外,还有什么其他方法方式进行编码吗?数值编码有两种常见的方法,一种是刚才提到的
one-hat,还有一种方法的话叫LabelEncoder,
我们把它称为叫做标签编码。
1 | |
如果你有 10 个类别,这 10 个类别会分别编码成多少呢?会编码成 0-9 对吧?
那针对每一个
feature,就是从这个列表里面去进行提取,先去做了一个fit_transform。就是先去
fit,同时去做 transform,把 feature 做了一个转换。
我们是对训练集做了个转换,测试集只要应用就好了。那想想,为什么测试集里面没有做 fit?因为训练集你已经 fit 完了,训练集和测试集标准是统一的,同样的一种编码规则,所以这里就不需要做 fit 了。
为什么测试集不用
fit,因为我们的编码规则要统一。举个例子,BusinessTravel这个特征,很少旅行我们把它称为叫
2,不旅行叫 0,经常旅行叫 1.在测试集里面我们也有
Travel,那如果出现的顺序跟之前的顺序不一样,你还会去做一个
fit,它有可能编码的关系就发生了变化。就是说我们的类别特征在训练集里面出现了,在测试集里面也会出现。我们需要让它的编码的规则是一致的,训练集里面如果他指定的Travel_Rarely是
2 的话,在测试集里面也必须是 2。如果我们重新 fit,有可能它就不是 2
而有可能变成 1。如果变成 1
的话两个代表的含义就不一致了,就会造成运算的错误。所以我们在测试集里面是直接应用
fit 的含义,fit 含义的话就是指定关系,fit 就是指定我们的 label encoder
的关系。transform 是应用这种 label encoder 的关系进行编码。
又或者,我们可以将这两个数据集合并一下,合并成一个大的数据集,统一进行 fit,fit 之后再将它们分开。当然,这样做也是可以的。
我们就用刚才的 LabelEncoder 直接做 transform,把测试集也做一个编码。编码之后,依次的这个类别特征就编码好了,就可以把它输出出来。你可以看一看他的 LabelEncoder 的这个逻辑关系。
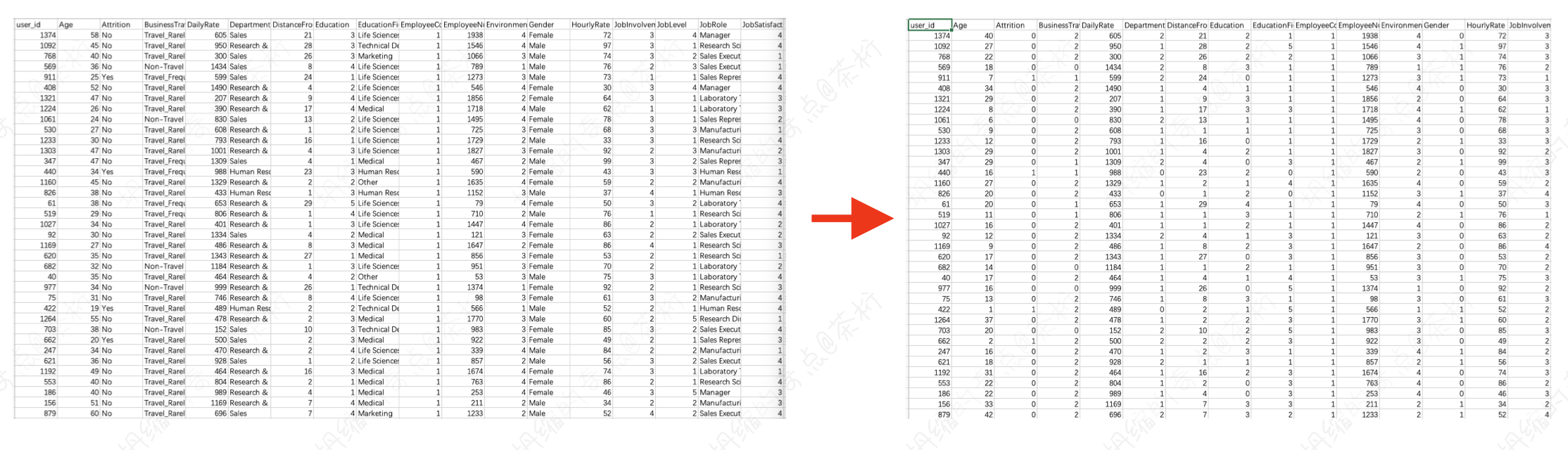
可能里面的文字太小看不清,大家可以自己拿着数据集测试,跑到这一步的时候和一开始的数据进行一个比对。那么对它的这个逻辑就比较了解了。
机器学习训练一定都是数值类型,不能出现字母,如果出现字母它是处理不了的,就是需要进行标签编码。
处理好以后的我们就可以用机器学习建模了,下面就是属于建模的环节,这里的建模用的是个分类模型。
1 | |
这里应该是数据train,
因为之后这个数据集还要用,所以我做了个保存再读取,所以变成了train_load,
test 也一样。
我们在建模的时候又切分了一下数据集,切分用的是train_test_split,这个就是一个比较常见的切分的工具。在前面基础课程中我有一节专门将了数据集的处理,里面也有详细的说到。
指定它的切分的数量是 20%,也就说测试集是 20%。至于为什么不拿百分百的数据用于训练,我们之前的课程里也详细的说过,最后会无法评估模型的效果。
然后我们用
20%的数据作为切分,在切分过程中,我们设置了一个random_state,这里是随机数的种子。如果不写随机数的种子的话,同样的模型的参数得出来的结果可能是不一样的,我们就不好评估哪一个模型的参数会更好。所以一般来说我们可以写一个random_state作为随机数的种子。
我这里的设置的今年的年份,可以参考这样的写法,这样每次运行的结果就不会因为随机数种子的问题产生不一样的情况。
LR
然后咱们来用一个逻辑回归方法。
1 | |
逻辑回归以后调包,去 fit 它。fit 以后我们就可以 predict, 得到一个结果。
1 | |
直接 predict 得到的是个二分类结果,就是 0 和 1。0 和 1
刚才已经指定了,1 代表离职,0
代表不离职。我们也可以把它转换成一个概率型的问题,需要在 predict
的后面加一个 probability, 函数名称为predict_proba():
1 | |
这样我们就可以知道它离职的概率是多少,最后把它打印出来。
就着这个结果,我给大家再回头来说一下random_state,
当我们设置为 2023 的时候,那这个结果,就比如 1229
这个员工,它的离职概率是
0.173611,是不会发生变化的。当我们设置一个其他的参数,或者个干脆删除的话,它预测的值就会发生变化,比如,我删除了random_state之后,结果为:
1 | |
可以看到 442 和 1229 这两个员工的概率都变了。再设置回来,那它的结果又会变成原来的值,也就是说,我们模型和数据都没有发生变化的时候,那么对最后的结果发生影响的就是这个种子值。有的时候,我们看到结果发生变化,可能会认为我们模型有可能变好了或变坏了,实际上模型是没有发生任何的变化,我们也没有改变它。
所以为了去衡量模型的好坏我们把那些变化量给它固定住,让它设置成为一个固定的随机数种子。这样我们再去调参的时候就可以知道这个模型的好坏了。
机器学习还有个过程叫做超参数的调整,比如说max_iter可能不用
100,我们试试看 50
的好坏等等。怎么去衡量它,要把random_state固定下来,来去对比
50 好还是 100 好,这样才能有更清晰的一个判断标准。
所以ramdom_state是帮助你去衡量模型的好坏的。比如说我们下一次用
SVM 来去判断,这样我们先用随机数种子也给大家固定起来。
接下来,如果我们要将概率转化为二分类进行输出,加一个简单的判断,map 一下就可以了:
1 | |
大家可以自己运行一下,好好看一看这个逻辑。可能第一次写机器学习的同学需要后面逐渐熟悉一下,包括我们这些流程的过程,代码呢在我的课程仓库里,大家可以自行去获取: Core BI
以上就把这个流程简单给说完了, 这里用的是一个 LR 的模型,其实可以采用其他的模型一起去做。
LR 就是一个逻辑回归,逻辑回归是属于线性模型,比较简单的一个模型。我们今天先不着重讲解逻辑回归背后的原理,这个咱们之前的基础课程里也有详细的给大家讲过。现在只是让大家先有个整体的概念,知道都有哪些工具可以去使用它。
LR 工具:
from sklearn.linear_model._logistic import LogisticRegression
参数:
penalty: 惩罚项,正则化参数,防止过拟合,l1 或 l2,默认为 l2C,正则化系数λ的倒数,float 类型,默认为 1.0solver: 损失函数优化方法,liblinear(默认),lbfgs, newton-cg, sagrandom_state: 随机数种子max_iter: 算法收敛的最大迭代次数,默认为 100tol=0.0001: 优化算法停止条件,迭代前后函数差小于 tol 则终止verbose=0: 日志冗长度 int:冗长度;0:不输出训练过程;1:偶尔 输出; >1:对每个子模型都输出n_jobs=1: 并行数,int:个数;-1:跟 CPU 核数一致;1:默认值
常用方法: - fit(X, y, sample_weight=None) -
fit_transform(X, y=None, **fit_params) -
predict(X),用来预测样本,也就是分类 -
predict_proba(X),输出分类概率。返回每种类别的概率,按照分类类别顺序给出。
-
score(X, y, sample_weight=None),返回给定测试集合的平均准确率(mean
accuracy)
这个工序里面我们怎么去设置参数,比较常见的像penalty,正则化系数C等等。
随意数种子、迭代次数这些参数都是可以调整的,也可以用它默认的参数直接去创建。
predict(X)和predict_proba(X)这两个分别代表的一个是等于类别,就是
0 和 1
输出的结果。还有一个输出的就是个概率值。根据需求,到底是直接看类别还是概率值,可以选择不同的函数来去完成。
那这边我们就把 LR 使用的一个流程在我们的项目中,通过这个例子来给大家讲完了。咱们先从整体上去了解,细节的地方下来再慢慢的去看,自己加一些笔记。
SVM
除了 LR 以外还可以用 SVM,这个我们在之前的基础课程也有重点讲过,支持向量机。这个方法在 2010 年前后很火,这模型在 10 几年前是主流模型。现在的风头已经被神经网络,就是我们的 neural network,以及大数据模型掩盖住了。但是在 2010 年左右那阵主流模型就是 SVM。不管是做分类任务还是图像识别,它的效果都是不错的。
它有三种包,分别是 SVC,NuSVC 和
LinearSVC。这个包有啥区别呢?其实一般来说,前两种只要用一个就可以,这两种都是我们的支持向量机,无外乎就是它的参数、配置会有些区别而已,一个是C,
一个是nu,用哪一个都可以。推荐大家使用第一个。
后面有个 LinearSVC,我们把它称为线性的。支持向量机一般来说是非线性的特征,它由低维的空间映射到一个高维空间里面去了,所以通常我们用非线性的话用第一种 SVC。如果你认为我们的变化是个线性变化,那我们可以用 LinearSVC 也是一样的。
这三种方法分别如下:
1 | |
常用参数:
C,惩罚系数,类似于 LR 中的正则化系数,C 越大惩罚越大nu,代表训练集训练的错误率的上限(用于 NuSVC)kernel,核函数类型,RBF, Linear, Poly, Sigmoid,precomputed,默认为 RBF 径向基核(高斯核函数)gamma,核函数系数,默认为 autodegree,当指定 kernel 为'poly'时,表示选择的多项式的最高次数,默认为三次多项式probability,是否使用概率估计shrinking,是否进行启发式,SVM 只用少量训练样本进行计算penalty,正则化参数,L1 和 L2 两种参数可选,仅 LinearSVC 有loss,损失函数,有‘hinge’和‘squared_hinge’两种可选, 前者又称 L1 损失,后者称为 L2 损失tol: 残差收敛条件,默认是 0.0001,与 LR 中的一致
这些是一些比较常见的一些参数,我们可以做一些配置,这个你自己可以看一看。
工具的使用啊,其实工具的使用就掉包就好了。我们在学习的时候也稍微了解一下它的一个原理。机器学习和深度学习原理呢,咱们之前课程都详细的讲过,这里简单给大家讲解一下。
SVM 的思想就是把一些原来不太在线性平面上,不好分割的数据,通过一个超平面让它去分割。
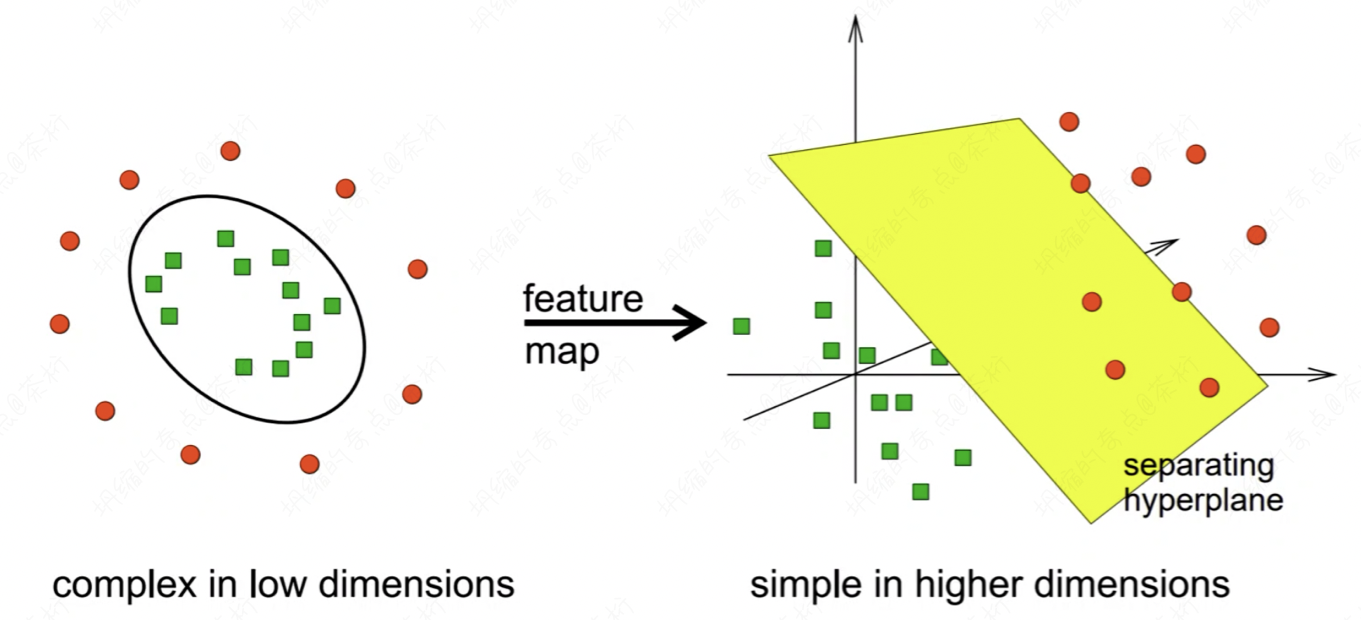
比如说左图,这是个物体在一个平面的桌子上面去摆放。这个平面桌子上有两种物体,一种是红色的圆球,一种是绿色的方块。那我们在桌子上去任意的划分,以线性分类器做分类,他们能把它分类出来吗?你去切很多刀,每次的话都是线性的,线性就是一条直线的方法。能不能把红色和绿色给它一分为二,分的比较好呢?
你会发现很难对不对?怎么画都很难。所以在低维空间中它是无法线性可分的。这个时候,咱们就想了一个方式,用手猛地一拍桌子,这些物体瞬间腾空而起,在他腾空的那一刹那时空静止,咱们再次用手在它的平面处切了一刀。可以看到这个平面在黄色之上的,我们把它分割出来是红色的圆球,在平面之下就是绿色的方块。
所以在高维空间中我们可以让它变得线性可分。那么 SVM 的特点就是去找到一个从低维到高维的映射,让它在高维空间中线性可分。现在大家能明白 SVM 的一个原理了吧?它的作用就是找到一个映射关系,方便你在高维中进行一个线性可分。
我今天没有着重去推数学的工具,这些如果要推的话可能会花很长的时间,那我只是给大家介绍机器学习的全家桶,先让大家有一个整体的认知。你知道 SVM 的作用是什么,下一次想到它就会想到我们刚才讲的那个场景。由低维到高维。
那由低维到高维找到这个空间怎么找呢?我们有一些找的方式。
去设置一个核函数,这个叫做 Kernel。它的 Kernel, 核就是映射关系。有几种核,一种叫线性核,线性核还是一种桌子平面,只不过把这个桌子变成了另一个桌子。
多相式核就是一个非线性的空间,更高维了。
RBF 属于高斯核函数,也是一个非线性的关系。
包括 sigmoid 核,sigmoid 在 SVM 里面可以设置这 4 个核函数,sigmoid 是其中之一。这个 sigmoid 如果你之前有看我的前面的「核心基础」部分,那是经常会提到它。我们在构建神经网络的时候,它就是神经网络的激活函数。它也是逻辑回归的一个过程。
sigmoid 的原理就是把线性的映射成为非线性,所以它也是一个非线性的映射。
我们有很多种映射关系,都可以帮你找一找能不能在这样的高维空间中变得线可分,有可能。所以我们可以尝试不同的核,去做一些切分。
在使用过程中如果你要用不同的核,尤其是高维的核,你要用 SVC 了。如果你觉得它就是个线性过程的话,我们就用 LinearSVC,它就是个线性的变化。
针对我们离职员工预测这个问题,它的数据集比较简单,规律也没有那么复杂,所以可以两种方式都尝试一下,看看谁的效果好。
1 | |
我这里用的 LinearSVC 做一个设置,整个调包过程都是类似的,都是创建好了这个包然后用模型去 fit,再去 predict,把 predict 之后的结果进行输出即可。调包的原理、过程都是一样的,只不过你可以调不同的包来去完成。
以上是 SVM 的过程, 可以用 SVC 也可以用 LinearSVC。
那在这段代码里,我在执行 LinearSVC 之前还做了一个操作,这个操作是一个叫做 MinMaxScaler, 这个是 0~1 规范化,它也属于数据预处理的一个环节。
用 0-1 规划化的目的是把数据映射归一化。归一化到 0-1 区间。原来的数据类型如果你去看那个大小,比如说工资就有可能是几千到几万不等,他的数据的范围比较大,工作时长有可能就是从几十到上百不等,可能维度相对小一点。不同的维度我们现在都给他统一。
统一的目的是啥?如果不统一对我们的模型有没有影响?记住,如果不统一的话,对于这种通过距离来做分类的这样一些模型是有影响的。
怎么影响呢?举个例子,比如说我要两种类别,一种类别叫做
Salary,这个salary以 0-1
万为例。还有一个我们叫做work hour,可能是由 0-100
为例。如果不给它统一,哪一个指标会占主导?是 Salary 还是
hour?这两个相对来说哪个更主导?
应该是属于量纲范围更大的,它的范围越大就越影响整个的模型的计算的过程,所以 Salary 就会更加的主导一点,还有其他的词段也是一样的。所以为了保持统一,我们就把 0-1 万都转换成 0-1。而 work hour 也转换成 0-1。这样的话我们的权重都是一致的。否则 Salary 的重要性就变成 100 倍的 work hour,或者其他的维度的指标。
所以这个规划的过程是跟距离相关的模型,对距离相关的模型我们需要先采用规律化的方法。因为你的距离,他的量纲要保持统一才可以。
好,以上就是我们整个的过程。SVM 就直接吊包去使用。当对它的了解,概念有些认知之后,我们可以直接去调用这个 LinearSVC 的包。具体的 SVM 原理,还是推荐大家去看看我之前的一章专门讲解支持向量机的课程。
那这个项目过程就给大家讲完了。咱们下节课再讲一个例子,带大家一起来看一个男女声音识别的例子。
01. BI - Project one, 员工离职预测

