30. BI - 详解 Graph Embedding 的 DeepWalk 算法及实例
本文为 「茶桁的 AI 秘籍 - BI 篇 第 30 篇」

Hi, 我是茶桁。
接着上节课咱们继续来讲。上一节中咱们讲了 Graph Embedding 的一些概念以及其中比较相关的「非欧几里得数据」是什么,介绍了 Graph Embedding 三种主流的技术,图因子分解机,随机游走以及深度学习。
那这节课,我们来看看 Deep Walk 算法, 还是要拿上节课的那张图过来:
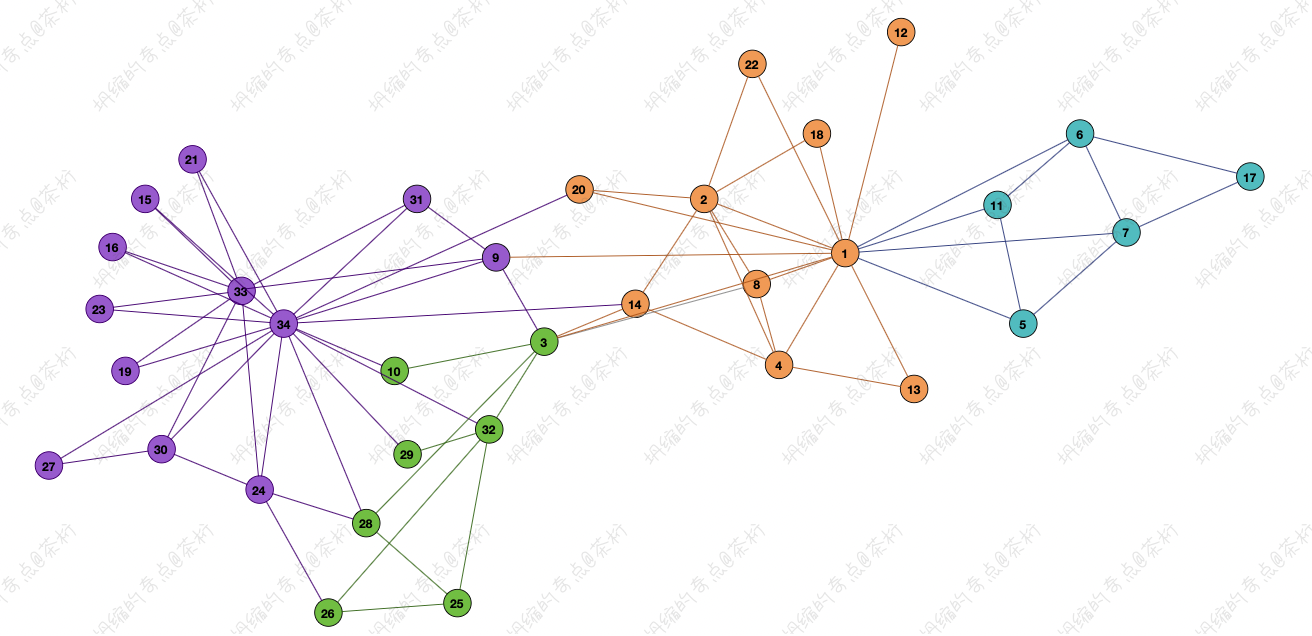
今天要用到的数据模型就是上图这样的形态,这个形态可以用于很多场景。
有了这样的数据表达,如何去把顶点的特征学出来?2014 年就有作者提出来一个种算法叫做 DeepWalk。
「[DeepWalk Online Learning of Social Representations, 2014 KDD」1这篇文章是开辟图的表征学习的开山之作,感兴趣的同学可以自己去看一看。KDD 这个会议应该算是在数据挖掘,知识发现里面非常顶级的会议。如果你有机会在上面发表一些文章,基本上在高校里面拿一个老师的职位都不成问题。

它输入是一张图的网络,输出就是网络中顶点的向量表达。做法是通过「截断随机游走」的方式(truncated random walk)去学习出一个网络的社会表示(social representation),在网络标注顶点很少的情况也能得到比较好的效果。它具有可扩展的优点,能够适应网络的变化。
作者所用的方法也是借鉴了 NLP 中的 word2vec,也就是 Word Embedding 词嵌入的方式。Word Embedding 的基本元素是 word,在 Graph 中表示的就是 Node。既然都是在做 Embedding,都是在做特征表达,做 word Embedding 输入的是一系列的单词,和图相比两种数据结构并不一样,有没有一些方式可以把图的这种内容去转化出来,让它变得一样。

想对任何的一个数据进行学习,可以先去找其中的一个顶点,顶点和顶点之间是有一条边联系。可以从它的邻居中找到任意的一个邻居去做游走,这样就可以在顶点上面游走出来一条路径,这样的路径就特别像一个句子。
word embedding 是对构成一个句子中单词序列进行分析,在 Graph Network 中 Node 构成的序列就是 Random Walk。
Random walk 指的就是从某一个特定的端点开始,去找它的一个邻居,再从邻居出发找下一个邻居,游走的每一步都从与当前节点相连的边中随机选择一条,沿着选定的边移动到下一个顶点,一直不断的重复这个过程。
我们可以去制定要去游走的步数,把这样一条路径抽出来就得到了一个句子。不断的反复就得到很多的句子。有了这些句子就可以利用 word2vec 这样的技术去学习,把所有的单词的特征都可以学出来。
DeepWalk
它的逻辑就是由随机游走做了一个模型的转换,这样就可以把图跟单词之间去做一个关联,DeepWalk = Random Walk + Skip-gram。
第一步咱们给定当前访问起始节点,从其领居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件,产生大量词序列(句子)。然后将这些词序列作为训练样本输入 word2vec, 用 Skip-gram + Hierarchical softmax 进行训练,得到 Embedding。

咱们还是以美国大学生足球队为例。一共有 115 支球队,每支球队都可以看成一支顶点,每个顶点都可以为起始进行出发,比如说以 A 为起始要游走多少次,每支球队游走 5 次,这个次数是人工来设定出来。那么以 A 为例就会有 5 个句子,每个句子的长度也可以自己来去定义,比如说每个句子的长度都为 10,这样就以 A 为开始,会有 5 个长度为 10 的句子。
咱们一共是有 115 支球队,如果通过这种方式来进行一个随机游走,应该是 575 个句子。将这 575 个句子作为数据就可以把每一个足球队学出来。
作者用一个巧妙的一个衔接,把 word2vec 这个工具跟图连接到一起去,衔接方式叫做随机游走(random walk),所以 random walk 是在图的学习过程中一种比较常见的技术,也是当下比较主流的一个技术。
通过 random walk 在刚才的例子里面创建了 575 个句子是第一步,第二步是把句子作为训练样本喂给 word2vec 就可以让它学出来。 word2vec 有两种学习模式, 一种是 Skip-gram,还有一种呢叫 CBOW,不管采用哪种学习的模式都可以把一个单词的 Embedding 策略给学出来。
现在回到应用场景,来看推荐系统。推荐系统要去对一个商品的特征去学习,所以你可以把它理解成任务就是要做 item embedding。那商品的什么特征,有怎么样的一个数据?以用户的行为数据来去做建模。
举个例子,我们来看图:
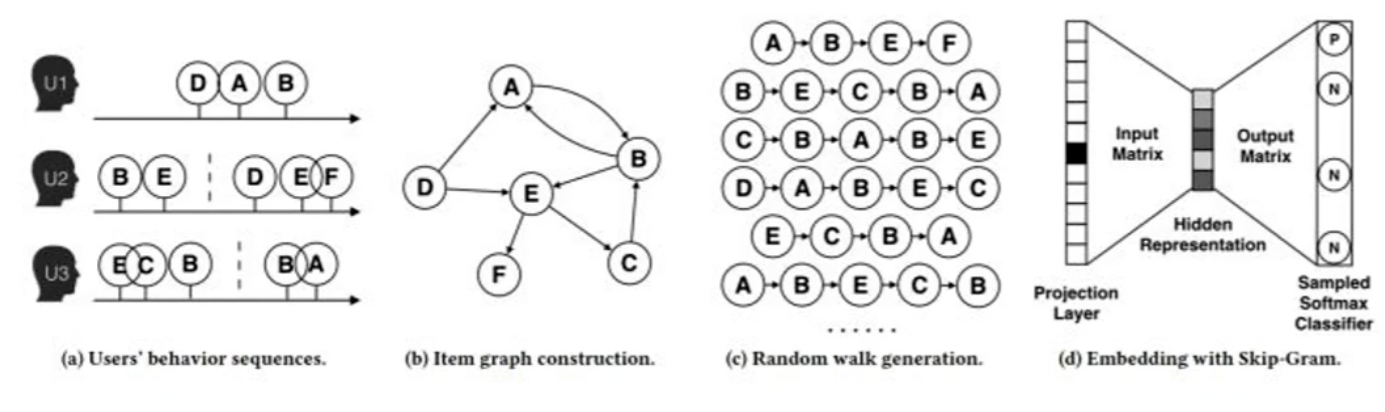
图中有三个用户,每个用户都点击了一些商品。用户 1 点击了 D,A,B,这个点击序列是要按照时序的顺序,先点击了 D,再点击 A,再点击 B。
第 2 个用户的时序就是 B 和 E,然后是 D,E,F。中间有一个虚线,虚线是把点击的序列做了一个分割,原来把这个数据叫做 sequence,持续的序列数据,现在分割把它称为 session。
session 称为会话,在浏览器里面有一个 session,在推荐系统里面因为你的点击有可能持续会特别长,以淘宝为例,如果从十多年前你就开始用淘宝,那你的点击序列可能 10 年前最开始的那个时间就已经开始做记录了,到目前为止可能你前两天刚刚看完淘宝,这个 sequence 序列可能会很长。你如果点击过 10 万个商品,那就会有 10 万个 item 组成的一个 sequence。
如果你把它看成一句话,一个序列,这个序列实际上就会特别长,有点像去看一本小说,如果所有的内容都是一句话的话,过程中没有任何的断句,实际上也是不合理的。
那么最合理的方式就是可以按照章节,按照一个时间的关系去给他做一个断句。我们采用浏览器的断句的方式,以 30 分钟为一个阶段,前后两个商品的点击如果小于 30 分钟我们就认为它是属于一个 size。如果它的前后两个点击大于 30 分钟,就认为它是不同的 size。
你可能昨天去看了一个衣服,但是今天你再去上淘宝的时候去看一本书。因为时间间隔已经相对比较长了,那么搜索的目标或者你的这些内容已经发生了一些迁移,人们更容易在相同的时间段之内做类似的事情,隔了一段时间可能就会有下一个任务产生。所以这里用一个虚线把它分隔出来。
对于一个用户来说有很多的句子,前面是一句话是 30 分钟之内,后面又是一句话,对于用户 3 来说也有这样一个句子。原始数据可以把它看成就是每一个用户会产生很多的点击的序列,click 的 sequence。
今天要去使用的是 Graph Embedding,原来的数据还要把它构造出来一张图。有了点击的序列,点击的关系可以用图的方式来作表达,也就是从 A 到 B 的过程。
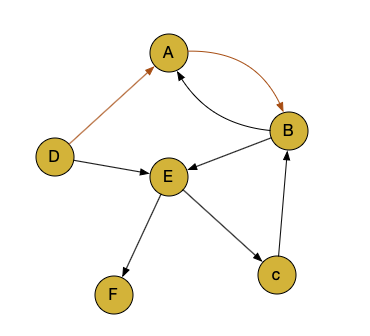
先来看用户 1,他点击的顺序是 D,A,B,这里 D 是第一个单词,然后是 A,然后是 B。我们用边代表它随机游走的逻辑。
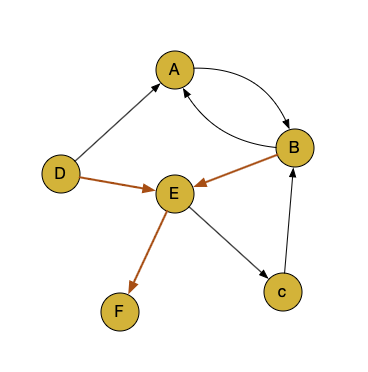
用户 2 是 B 和 E,B 和 E 走完了,E 和 D 之间是一个断开的关系,所以并没有连接边。再之后就是 D 到 E,E 到 F。
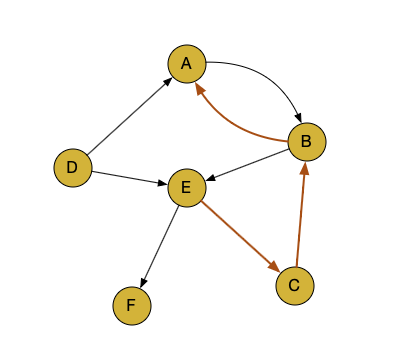
用户 3 的序列是 E 到 C 是一个, C 到 B 是一个, 然后断开了,在之后就是 B 到 A。
这样把三个链接逻辑组成一张图,就可以得到一张最终转化出来的图
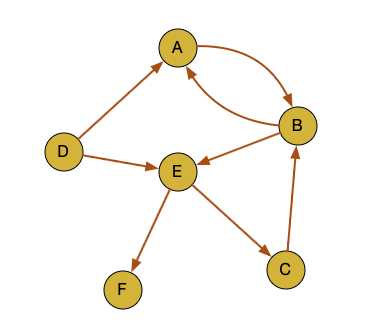
用户的是形成了三个 sequence,现在形成了一张图。第一步构造图的过程就完成了,做成了一个 Graph。原始数据是用户的点击序列,每个都是一个 sequence,最终讲这些 sequence 转成了图。
DeepWalk 上面给大家讲了,是两个阶段组成的,第一个阶段是 Random Walk,第二个阶段是 Skip-gram。它的本质就是 word2vec。
那么现在就从每个顶点开始都去随机游走一些边数。从 A 开始,A 可以走到 B 到 E 到 F。
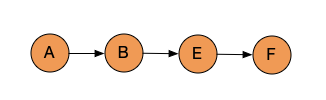
每个游走的过程都是找它邻居,邻居里面随机的去选取一个就可以。有 5 个邻居,在 5 个邻居里面随机的去选中一个,如果找到了 B,B 还有很多邻居,再去随机选中其中一个。
长度假设设为 5,那为什么有些地方到 4 就结束了?因为到 F 这个位置就没法再走了,走不了。所以就直接停掉了。
这样就从形成的图走到了下一个过程,这一步里就是产生了很多个随机走出来的句子。
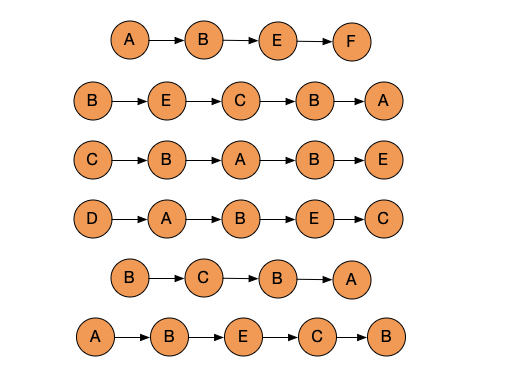
原来是三句话,现在产生无数句话。这是随机游走的过程,有了随机游走,再喂给第二步 Skip-gram。通过 Embedding with Skip-gram 把每个单词的含义学出来, 作为它的表达。
回到这个例子里面来,我们通过图的方法已经把每一个商品的特征学习出来了。那么商品特征学习出来以后,当用户点击了某一个商品就可以找跟他类似的 Embedding,求它的 similariting 相似度,最相似的那些商品的 TopN 来进行推荐。
我们以上整个过程是一共分了四步去做,那我们可不可以不走图的方式,拿到 sequence 以后就直接去进行特征学习呢?其实图的学习方式只是一种 Embedding 的策略,如果不走第二、第三步,也就是不去随机游走组合成句子理论上也是可行的。
那为什么还要走第二步和第三步呢? 或者说走这两步有什么好处。原来我们只有三句话,零零星星的拿到几种可能性,这种可能性只是告诉我们它们可以构造出来一张图,每条边代表它的一种可能。
因为用户的点击不是全量点击,也没有把所有的可能性都枚举出来,那我们就可以基于第二步去生成一些新的可能性,这样我们就会通过随机游走的方式拿到更多的句子。
在第三步的基础上再进行学习,实际上是通过第二步的方式去创建更多的 sequence,这样再通过 Embedding 去学习后面更多单词的特征表达。
DeepWalk 有一个随机的概念,走到某个节点 vi 后,然后再去遍历 vi 的临接电 vj 的概率。如果物品的相关图是一个有向的有权图的话。
是什么意思呢?比如我们在点击序列过程中 A 到 B 的出现次数可能是 10 次,这样我就会把这条边的设置为 10 的权重。如果 B 到 C 是 1 次,就可以设置为 1 的权重。这个权重对后续的跳转转移还是有影响的。如果 A 到 B 是 10 次,它的次数要更多,那么在未来模拟 generate 的时候,理论上也应该比其他的跳转概率会更多一点。
所以我们可以把跳转概率概率 P 在节点 \(v_i\) 走到 \(v_j\) 的可能性给求出来。
\[ \begin{align*} P(v_j | v_i) = \begin{cases} \frac{M_{ij}}{\sum_{j\in N_{+}(v_i)}M_{ij}} , v_j \in N_{+}(v_i) \\ 0, e_{ij} \notin \ \end{cases} \end{align*} \]
\(M_{ij}\) 代表的是节点 \(v_i\) 到节点 \(v_j\) 两者之间边的权重, \(N_{+}(v_i)\) 是节点 \(v_i\) 所有的出边集合。
如果物品相关图是无向无权图,那么跳转概率将是上面公式的一个特例,即权重 \(M_{ij}\) 将为常数 1, 且 \(N_{+}(v_j)\) 应该是节点 \(v_i\) 所有「边」的集合,而不是所有「出边」的集合。
比如,A 到 B 的概率是 10,B 到 C 的概率是 1,现在有 D 和 E,A 到 D 的概率是 1,A 到 E 的概率是 1。
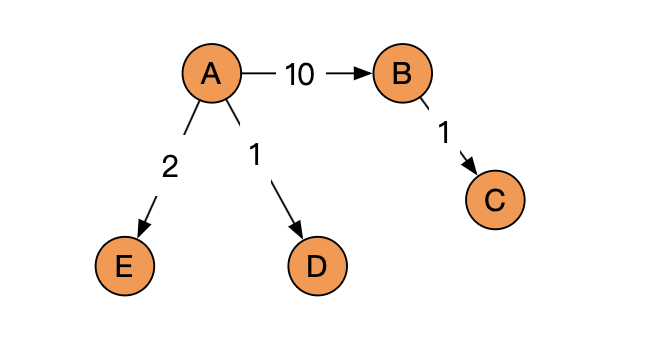
现在 A 有三个邻居,我们把权重放进去,那 A 到 B 的概率就是 \(10 / (10+2+1)\)。这样就会更加真实的去模拟出来从 A 到 B 的一种跳转概率的可能性。
所以总来说原来的数据可能是一些样本的采样点,产生了一些用户点击的行为序列。通过它去构造一张图,图中把原来的采样的概率求出来,这种采样概率最终我们还可以让它生成出来更多种可能性。
就有点类似于像样本补全一样的策略,就可以在图中的产生出来更多句子,可以更充分的去学习这些点击序列的特征。所以在 DeepWalk 里面是可以设置有向的有权图,权重可以代表点击的次数。
实例:美国大学生足球队 Embedding
回到美国大学生足球队的这个实例,来看一看这个工具该怎么去做。
先使用 networkx
来构造一张图,这个是之前的课程给大家讲解的。图的数据结构是专门有自己的文件格式gml,因为图无外乎就是点和边。自己去一个一个加也是完全可以的,也可以通过
networkx 来生成一个:
1 | |
有了这张 G,我们就可以对它的顶点情况,边的情况来进行查询了。然后我们将顶点和边分别打印出来查看一下。
1 | |
接着咱们来模拟整个运算的过程,第一个模拟的就是 random walk:
1 | |
我们先去选中一个顶点, 给他一个
node,然后人工参数指定要游走的长度。游走的 random walk 记录好的句子呢从
node 开始了,剩下的长度就是设定的长度减 1。比如说设定
path_length 为 10,后面还要走 9 步。
每个步骤先去找 node 的邻居,它的 neighbor。邻居里面现在在做的是一个不重复的采样,如果直接走过就把它去掉了,剩下的过程中看一看它有没有元素,没有元素就 break。所以它的长度有可能是小于 10 的。
如果它的长度现在还有一些可以走的邻居,就从这个邻居过程中去做一个 random choice,随机去选择其中一个。把这个选择好的 random node 加到之前游走的这个列表的队列过程中,再把 random node 移动到下一站,把 node 变成了刚才采样的这个邻居的顶点。然后再去做一个 for 循环,因为 node 已经更新了,就会找到新的 node,它的 neighbor,以此类推。
最终有可能等于 10,就是 length 指定的长度。然后把游走的序列给它返回过去。
最后我们打印一下,顶点 EastCarolina 生成 10
个长度的句子。我们再运行一下:
1 | |
可以看到和上一次打印的结果相比已经发生了一些变化,所以它每次游走有可能是不一样的。
随机游走完成以后接下来要去做一个遍历,遍历它所有的顶点。
1 | |
一共 115 个顶点,每个顶点的遍历过程都走了 5 个句子,5 这里是人工指定的,每一次句子的长度是 10 也是人工指定的。
这样 random walks 里就变成了 115 x 5 = 575 个句子。
接下来,再把它的 rendom works 打印出来, 以及它的长度。
1 | |
它的长度还是比较长,随机游走出来了非常多条边。有了这 575 个句子,可以把它看成英文的百科全书,它是一个非常大的语料库。
接下来就是掉包了,去使用 word2vec,从这样的一个语料库去学习每个单词的特征表达。
word2vec 有几个核心参数,window 是上下文的长度,因为单词只跟上下文预测相关,所以要去限定它的 window size。后面还有一些负采样的一些比值。
1 | |
设置好了这个 model 以后,就可以让 model 去创建一个词汇表,从 random woalks 里面,就 575 个句子里面去 build 一下 vocabulary。
1 | |
然后再去做一个训练,把原来的语料喂给它去做一个训练。
1 | |
训练好以后就可以有些功能在 word2vec 里面去使用了,一个比较常见的使用功能就可以去找跟它相似的顶点还有哪些。
还是以 EastCarolina 为例,找一找在现在的这个 model
里面跟它相近的顶点,跟它相近的球队有哪些。
1 | |
通过图上的表达的学习可以得出来跟它最接近的列表。Army
是最接近的,相似度是 0.982。 后面还有
AlabamaBirmingham, Louisville等等。
其实,如果我们再去运行一下,这个排序理论上是有可能会不一样的。因为在做训练的过程中,random walk 有可能每一次都不一样,之前的 575 个句子和下一次运行的 575 个句子有可能不同。咱们并没有设随机数种子,所以得出来的内容,训练的语料不一样,那得出来的 Embedding 也可能不一样。
但也能看到整体的趋势,细节上面有些稍微的调整,但是整体的趋势是不会发生变化的。总来说它的相似度计算还是比较准确的。
我们还可以用一个 PCA 的工具。PCA 这个工具可以去降维到一个很小的一个维度向量里面去。原来在做 word2vec 的时候是 100 维,一个顶点它是一个 100 维的一个长度,而 100 维的长度要去从可视化的角度上去看基本上是不可能的。就要把它通过主成分变化的方法映射到 2 维的坐标系里面去。它最大的好处就是可以做平面的直角坐标系的呈现,通过 PCA 来进行计算,然后再把计算的结果以散点图 scatter 的形式呈现出来。这样就可以知道哪两支球队会更近一点。
1 | |
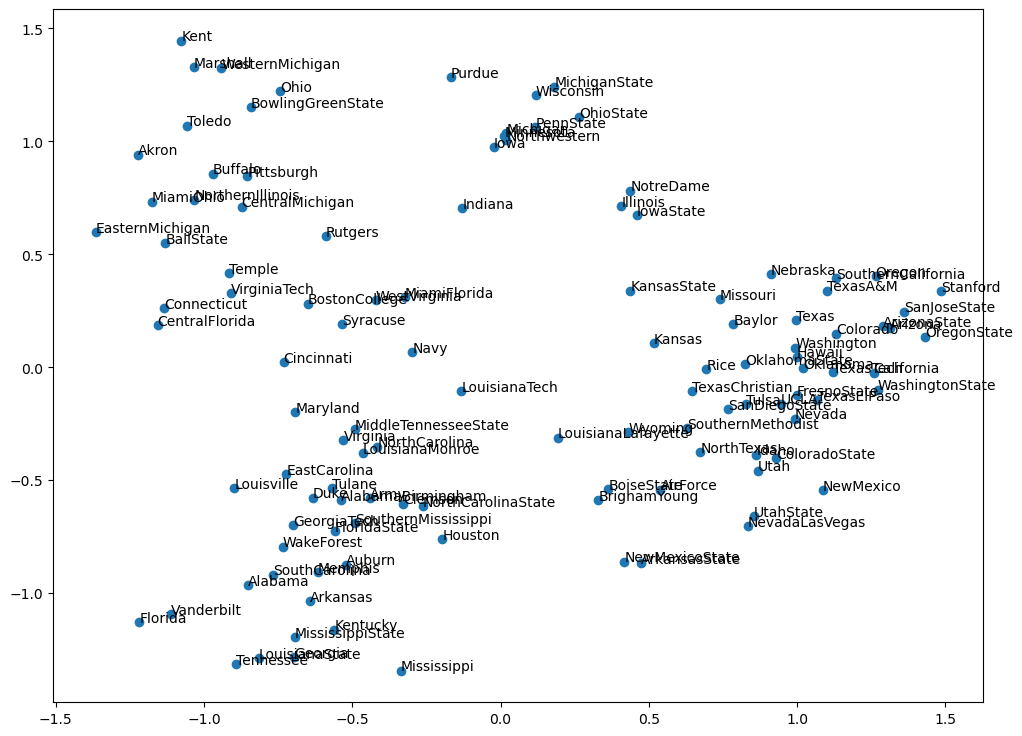
最后我们来看一看可视化的一个结果。
115
支球队数量还是比较多的,通过二维可视化可以看出来他们之间的一些相似程度。比如说
navy,可能跟 Boston,Indiana
相对来说会近一点,离 Stanford 就会比较远,离
Purdue 也比较远。
虽然压缩以后会有些精度的损失,但总来说主要特征还是比较明确的。以上整个过程就是我们所求的球队的一个表达。这样我们就可以知道每支球队的向量,也可以方便你去计算哪两支球队是比较接近的。原始的数据是通过
gml 来完成的,然后自己去写了一个 random walk
来进行采样,得到 Embedding 的工具还是 word2vec,用它来去完成,word2vec
是最早提出来的 Word Embedding。
其实这种例子可以用到很多的场景,不仅仅是美国大学生足球队。人和人之间的社交行为,看谁的行为特征是更接近的,也是完全可以的。
整个我们看出来 Deep Walk 的思想还是非常巧妙的,做了一个衔接,可以把原来的 word2vec 直接无缝的去衔接利用上。这个算法就是最早的 Graph Embedding 的一个开山之作,原来做 random walk 是它最大的创新,而 random walk 没有考量随机策略。
那我们下一节课就来看看,在这两年之后,也就是 2016 年提出来的
Node2vec。
https://classes.cs.uoregon.edu/17S/cis607bddl/papers/Perozzi.pdf↩︎
30. BI - 详解 Graph Embedding 的 DeepWalk 算法及实例
https://hivan.me/30. BI - 详解 Graph Embedding 的 DeepWalk 算法及实例-1/

