28. BI - 图论工具和算法, 社区发现以及最短路径
本文为 「茶桁的 AI 秘籍 - BI 篇 第 28 篇」

Hi, 我是茶桁.
咱们已经讲了好几节课的 PageRank, 也了解了 PageRank 的原理就是基于图论. 之前我有给讲过, 在「数学篇」中我们有用四个章节来详细的讲解图论的相关知识。其中包括:
在 2024 年初的时候,我将整个数学篇做成了电子书,这样大家就不需要一篇一篇的打开阅读,直接下载整本电子书就好了。


有兴趣拓展的小伙伴可以去下载阅读下。
不过,由于数学篇的内容是付费内容,所以可能有些人并不太愿意去购买。 可是咱们一些相关内容和图论相关性又比较强,在这里, 咱们就花点时间来给大家拓展一些图的相关内容。
图论工具的作用
图,不仅仅是一个排序的问题,还有很多工具可去使用.
前几节课中给大家介绍的NetworkX,
在这个工具箱里也存在着除了PageRank以外的一些方法.
咱们应该很多人都用过高德地图或者百度地图, 在图上面最经典的一个算法就是求路径.
比如你想从人民广场到静安寺, 就需要进行路径导航. 可以是步行, 骑车或者交通工具. 不同的方式就是不同的参数, 具体的算法都是图的一个应用.
除此之外, 在银行的存款来往过程中会有一些诈骗行为, 银行的人怎么去发现诈骗行为?用一个方式就是社区发现, 可以发现一些小规模的社区, 有可能是诈骗团伙.
整个图的过程图是由什么组成的? 之前我们也提到过, 是顶点和边. 顶点和边是抽象的模型, 要做的事情可以是对单词做分析, 对句子做分析, 甚至对图像做分析, 对用户做的分析, 这些就是顶点. 它可以是各种各样的一些类型, 它背后代表的数据有可能是各种各样的一些类型.
社区发现
先介绍一下什么叫社区发现.
图里面可以发现各种各样的一些社区, 社区发现本质是一种聚类思想.
图里面有社交网络, 社交网络就会有各种各样的社区. 交通也是一样, 交易也是一样. 它可以帮我们做一些精准的营销, 找到相同社区的人.
我们来看下面这张图, 看看这张图内有几个社区:
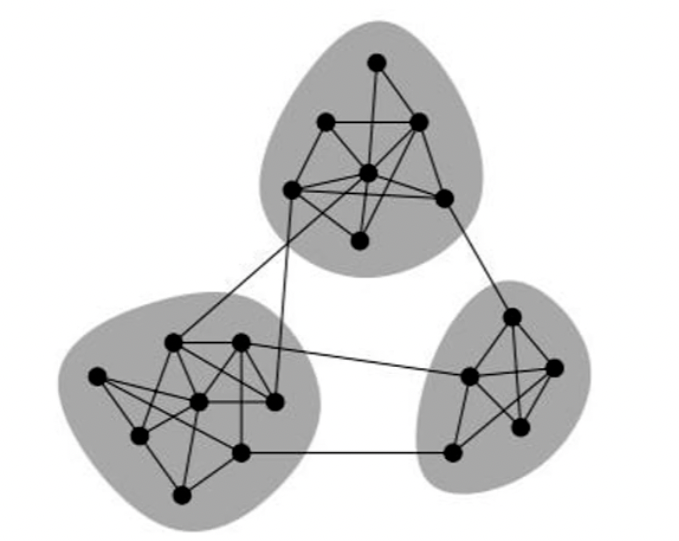
这张图里面, 按照它互相连接的行为聚成了三个社区, k=3. 为什么是三个社区? 因为相同的社区比较接近, 比较相似. 不同的地方它们之间边连接的比较少, 所以社区内部互相连接或者边数比较多, 社区外部连接的比较少. 这样我们就可以知道哪些人是一伙的, 去定位群体.
在讲社区发现的时候我们要知道, 它本质上是一种机器学习方法. 机器学习本身可以分成以下三种形式:
第一种监督学习, 监督学习是人标记好以后学习人的一些经验. 人的标记需要时间成本, 还有金钱成本, 成本还是很高的.
第二个无监督学习, 无监督是数据没有标注, 利用没有标注的样本进行类别划分, 这种方式也叫聚类方法.
今天给大家讲解的 LPA 社区发现是属于第三种方法, 叫半监督学习.
半监督学习, 从字面上可以看到, 它是介乎于监督和无监督之间, 既利用了已标注的数据又利用了那些没有标记的数据.
有可能某一些数据只标记了一部分, 10%, 另外 90% 都没标记. 如果只用有监督学习方式, 发现可以利用的数据太少了. 如果只用无监督学习数据, 发现标记的数据没有利用, 又太可惜了. 所以可以用半监督的学习方法, 把两种学习方式一起来进行使用.
今天讲解的 LPA 标签传播算法就是半监督学习的方式. 它的原理是基于数据分布上的模型假设, 利用少量的一标注数据进行指导并预测未标记数据的标记, 并合并到标记数据集中. 这个就是 LPA 的思想.
社区是分成为重叠和非重叠的, 两个顶点之间没有交集就没有重叠. 比如一个点要么属于社区 A, 要么属于社区 B.
重叠社区就是某一点可以属于多个社区, 就比如你很有钱, 社区 A 买了一套房子, 社区 B 也买了一套. 那么你就既属于社区 A,也属于社区 B.
LPA 标签算法全称是Label Propagation Algorithm,
属于非重叠社区发现算法.
这个算法相对计算起来会简单一点.
那重叠社区可以基于它的拓展的方式来进行计算,
其算法称作COPRA,
全称为Community Overlap PRopagation Algorithm.
LPA 是一个非重叠社区的一种发现方式, 我们来看看它整个的一套流程, 一起来看一看原理.
我们先假设每个节点拥有独立的标签, 标签采用的方式叫标签传播, 它会把标记传给周围的邻居, 也就是向邻居节点传播自己的标签. 然后标签就会更新, 每个节点的标签更新为领居节点中出现次数最多的标签. 有点随大流的感觉. 如果存在多个选择, 则随机选择一个.
当节点变成这个分类跟之前的分类结果不一样, 状态发生了变化, 还要把这个状态通知给邻居. 只要节点发生了变化, 我们把它称为叫做激活态.
也有一些可能性就是节点没有激活态, 因为标签没有发生改变. 如果大家都不发生改变, 都是非激活态, 那这个社区发现就稳定了. 当节点稳定以后, 相同标签的节点就属于同一个社区.
所以这里存在着标签传播和标签更新两个步骤.
只是这样讲似乎比较抽象, 让我们来看一个具体的例子, 一起体验一下.
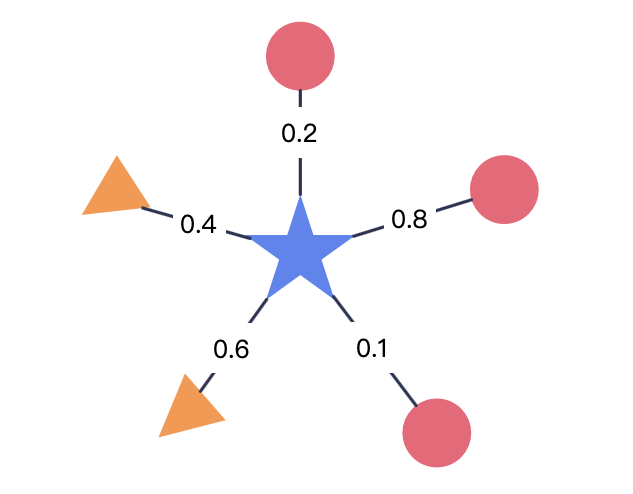
我们看到中间这个五角星, 它有 5 个邻居. 5 个邻居里面 3 个是圆心, 2
个是三角形. 这个点会变成哪一个类型? 这里用有权重的方式,
如果你跟你的邻居关系比较近, 数值会大一点. 比如说0.8,
远的话数值又会小一点, 比如说0.1.
如果中间五角星它的邻居有 5 个, 3 个圆 2 个三角, 这个五星会变成什么.
实际上这个变化过程中各种情况都有可能.
我们先看按加权和的方式发现圆形的比重比较大,
圆形是是1.1, 三角形是1.0,
1.1 > 1.0, 所以应该是圆形.
但是还有一种其他的方式, 如果做的是加权平均,
圆形标签的影响力平均下来是 0.367. 三角形是两个,
平均影响力就是0.5. 按照加权平均的话又变成了三角形.
所以主要还是看定义, 默认情况下应该是第一种.
这里有几个比较经典的例子.
首先第一个例子是一个美国大学生足球联赛的复杂网络数据集, 包括了 115 支球队(节点)和 616 场比赛(边). 实际上参赛的 115 支球队被分成了 12 个联盟, 比赛机制为: 联盟内部的球队进行小组赛, 然后是联盟之间的比赛.
那我们最终社区发现会是多少个社区呢? 一定是 12 个吗? 也不一定.
数据集是gml格式, 这个格式就是graph xml,
来先看看数据集是怎样的.
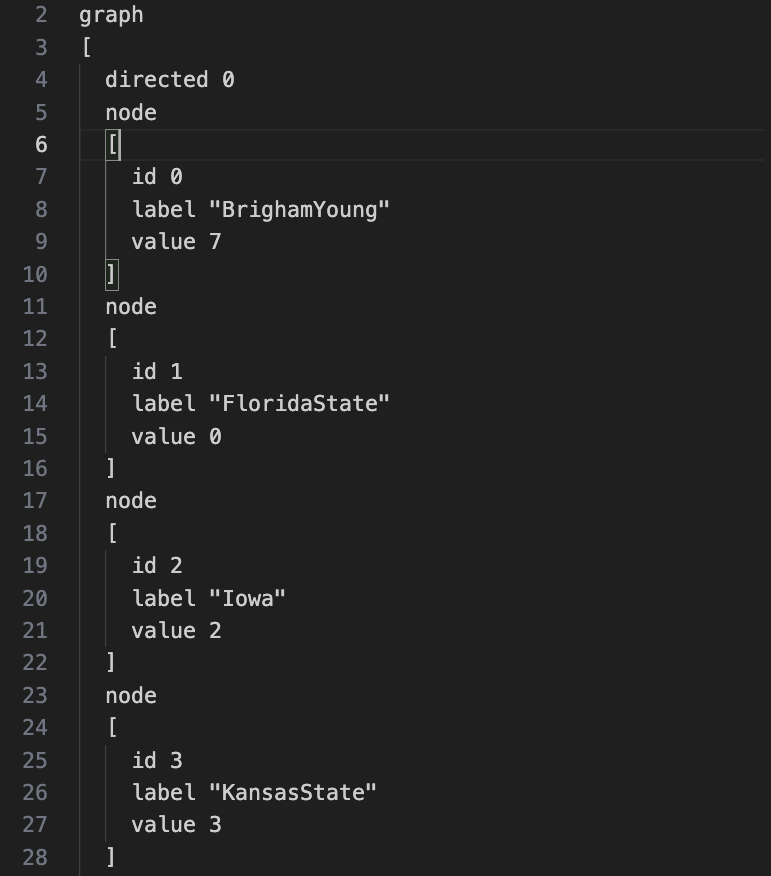
先去定义了顶点, 每个node的id是多少.
后面定义了边:
边里面就是source和target.
前面已经定义好的顶点包含了 ID, 现在就直接把顶点 ID 放进去.
所以gml也比较简单, 就直接定义了两种元素: 顶点和边.
让我们先把数据加载进来:
1 | |
这个包是NetworkX官方提供的链接,
当然你也可以直接下载进行解压缩. 这个包里包含了两个文件,
一个是football.txt, 是对数据集进行说明的,
一个是footbal.gml, 也就是我们要的一个数据集.
在包获取之后, 我们需要对其进行处理一下, 才可以使用
nx.parse_gml 来读取 gml 格式的数据.
1 | |
有了顶点和边这张图其实就应该唯一确定了.
所以怎么放到NetworkX里,
可以使用read_gml来直接读取,
它可以自动生成一个G, 生成以后直接调包就可以了.
1 | |
如果你是下载了压缩包在本地解压缩之后拿到的 gml 文件,
可以使用read_gml方法:
1 | |
然后咱们就可以讲节点图打印出来看看:
1 | |
大家应该注意到了我是先写了一个设置项,
然后在进行draw的时候直接使用了这个设置项, 同时,在 pos
里我用了 seed. 听过我前面机器学习基础课程的同学应该对这个不会陌生,
就是控制随机性的种子. 因为 2024 年了嘛, 所以我改了随机种子的参数, 改成了
2024.
这个图可以看到, 还是比较复杂的. 当然,
如果图中节点并不是很多的话你可以在设置里将 labels 加上,
不过对于这张图的话, 我们加上之后会变成这样:
1 | |
是不是蛮乱的? 根本看不出个所以然来.
不过没关系, 咱们现在最主要的目的不是要去绘制图, 而是要进行社区发现.
我们用community, 标签传播的一个方法.
把G喂进去就可以得到发现的社区,
然后把这个发现的社区打印出来.
1 | |
最后我打印了一下社区个数, 可以看到就如我们一开始猜测的一样, 并没有发现 12 个社区, 而是 11 个, 跟我们之前说的 12 个联盟是不一样的. 那这两个为什么不一样? 你要思考这 12 个联盟是怎么来的,12 联盟应该是地理位置, 有点像中国有多少个省, 每个省就有地理位置. 那一定是属于一个地理位置里面都属于同一个社区发现吗? 并不一定, 因为数据是动态的比赛数据, 有可能在比赛中其属性跟其他的属性会比较接近, 所以 LPA 就帮你来做社区发现了.
除了用刚才NetworkX以外还可以用igraph做判断,
igraph要比 NetworkX 更强大,
处理的节点数量更多, 但是 NetworkX 会更好用一点.
这两个工具都可以, 节点不多的情况下用NetworkX会更好一些.
1 | |
社区也是0-10, 11 个社区. 不过其实这个并不固定,
只是恰巧又是 11 个而已, 再运行一遍可能就是 10 个, 12 个甚至 13 个.
实际上标签传播还可以应用于别的一些场景, 用来做训练也会比较好用. 后面简单再给大家说一说其它的例子, 关于图论的例子.
最短路径问题
在这之前, 咱们提到过高德地图, 高德地图使用到最短路径. 在数学篇中,
咱们专门介绍过路径和算法,
在里面专门讲过一个最短路径算法, 就是Dijkstra算法. 除此之外,
还有一种floyd算法. 这就是在路径上最主要的两种方法.
这两种方法如果在大学期间学的是计算机, 计算机的课程专门有一门课叫算法与数据结构, 课上会专门讲到最短路径问题. 这两种方法用的还是挺多的, 尤其在导航里面是使用的这个算法.
什么是最短路径, 比如说你从人民广场到巨鹿路, 如何去规划路径最短,
我们使用高德地图的时候它一般会给你推荐多种路线, 有最短路径, 有最短时间,
有最少费用的等等. 最后都用 Dijkstra 算法.
Dijkstra 算法
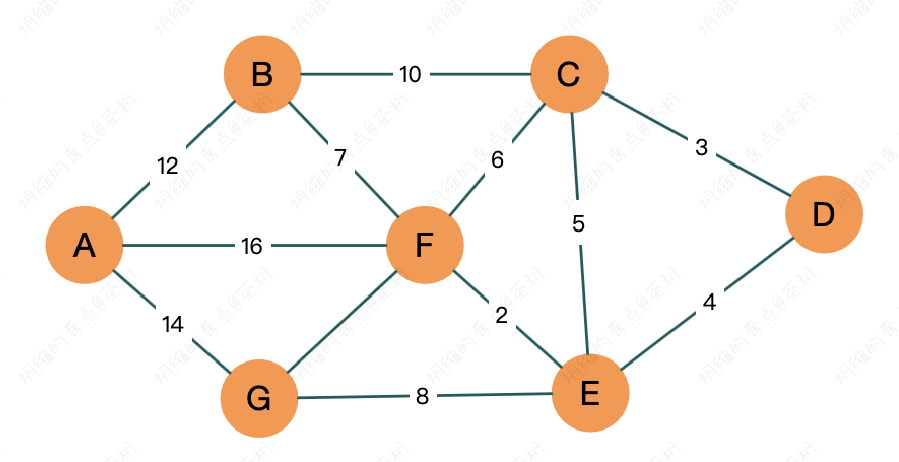
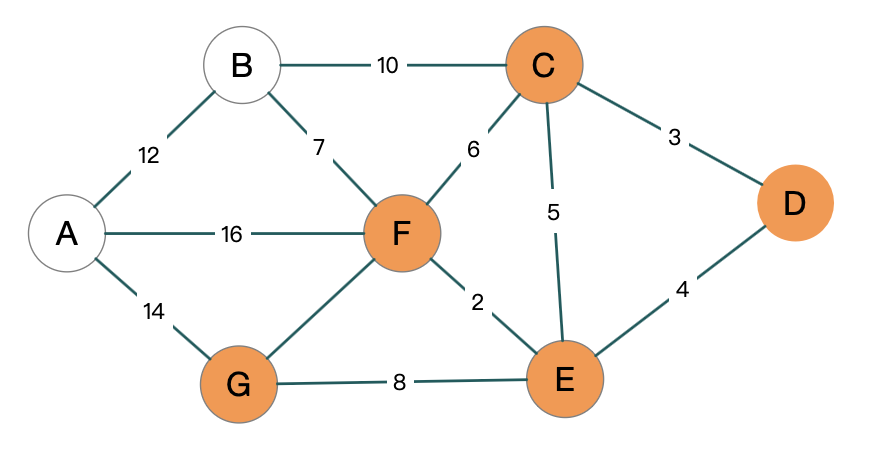
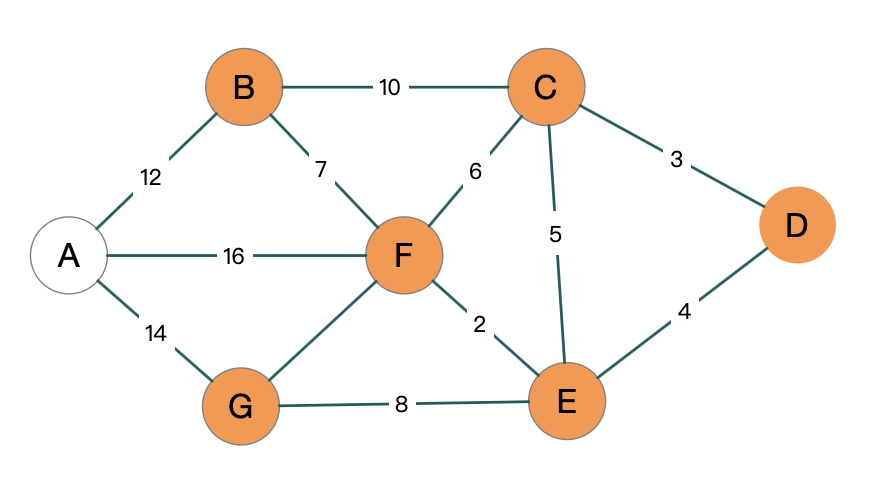
我们来看这张图, 从 A 开始, 比如说 A 是人民广场, D 就是巨鹿路. 中间会经过很多的点, 如何去安排会更好.
Dijkstra 要用两个集合来去做的计算, 指定起点 s,
引进两个集合 S 和 U. S 是已经求出来最短路径的顶点和相应的距离. U
就是还没有求的最短路径的顶点.(注意大小写)
最开始的时候是从起点开始的, 所以已经求出来的顶点只有 1 个, 就是 s, 剩下都是放到 U 里面去了. 计算过程是从 U 里面找到一个最短的路径放进去, 然后更新 U 中的顶点到顶点的一个路径, 不断地去反复, 让 S 越来越多, 让 U 越来越少, 最终把这个结果遍历完, 就可以把结果输入出来了.
这个就是Dijkstra的整个原理, 看着比较抽象,
我们还是来看一个具体的例子.
还是之前那个图
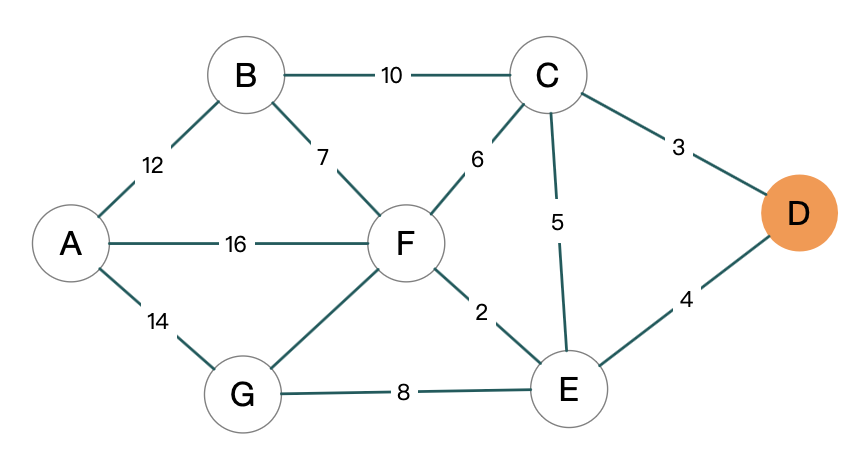
我们想计算 D 到其它点的距离, 起点就是从 D 开始的:
S = {D(0)}, U = {A(∞), B(∞), C(3), E(4), F(∞), G(∞)}.
S={D(0)} 表示 D 到 D 的距离为 0, 后面几个顶点
距离指向的是到 D 的距离. 那 A 到 D 是(∞), 也就是不直达,
所以用一个无穷大的符号. B 到 D 也是. C 到 D 为 3, E 到 D 为 4, F 和 G
都为不直达.
U 里面从数值上面比较明显应该是 C 到 D 的距离是最小的, 所以把 C 抽出来放到 S 里面去.
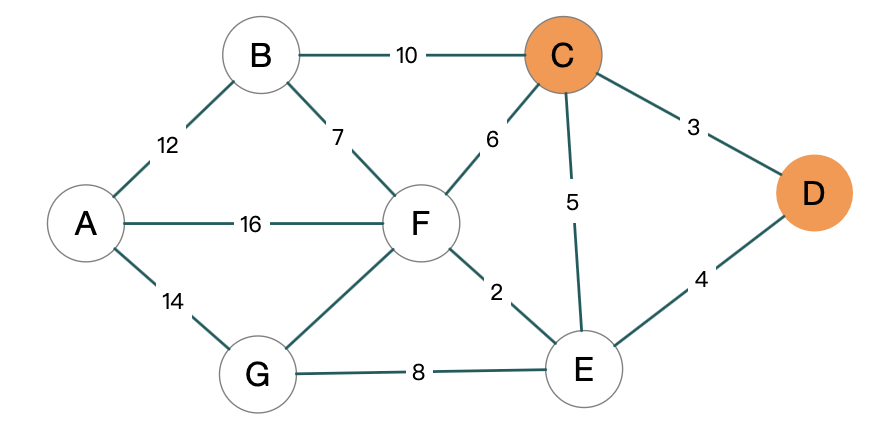
下一步就是要去更新, 通过 C 到 D 能不能去做一些优化, 看其他的点能不能通过 C 到达.
因为 C 已经是最优的了, 就可以去利用 C 找到 D . C 的邻居都可以利用 C, 其邻居有 B, F 和 E. 可以看到 B 原来并不能直接到达 D, 但是通过 C 就可以.那这个距离就应该是 10+3 = 13, 那其他几个 C 的领居也可以这样去做.
1 | |
E 原来是直达, 等于 4, 利用 C 的走变成了 8, E 是直接到 D 比较好, 因为我们要求最短路径, 8 要比原来的路径要大, 对于那些比较大的路径就不取它, 所以它不更新.
C 已经被放到了 S 中, 所以现在 U 中最小的路径就是 E 点, 那我们接着把 E 放到 S 里面去, 然后找 E 的邻居里通过 E 到达 D 的路径进行优化
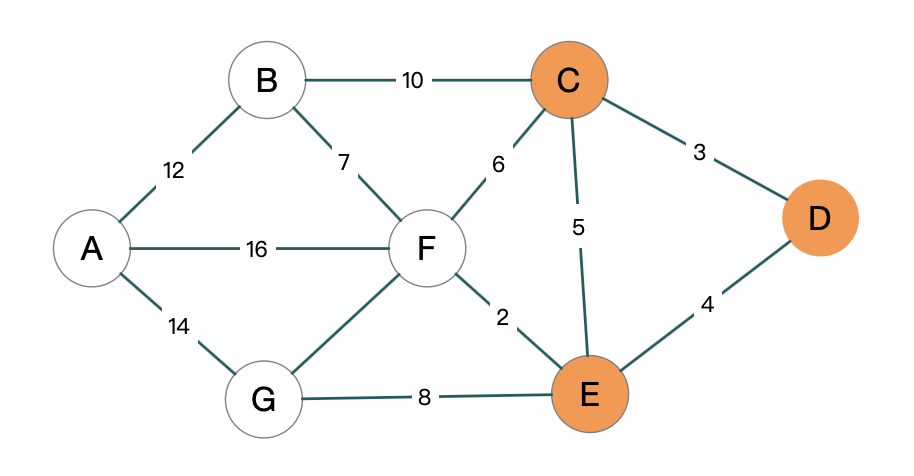
1 | |
接下来就重复上一个步骤, 现在是 F 最小, 放到 S 里面去, 接着去计算 F 领居的最小路径.
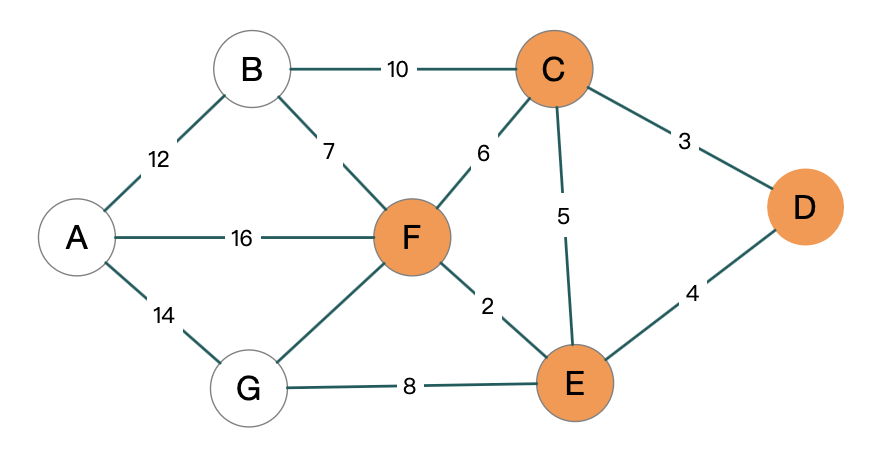
1 | |
接下来是将 G 放进 S 中,继续优化 U, 然后再继续上面步骤持续优化
1 | |
1 | |
优化到最后, 最终我们得到从 D 到城市其他地方的最短距离
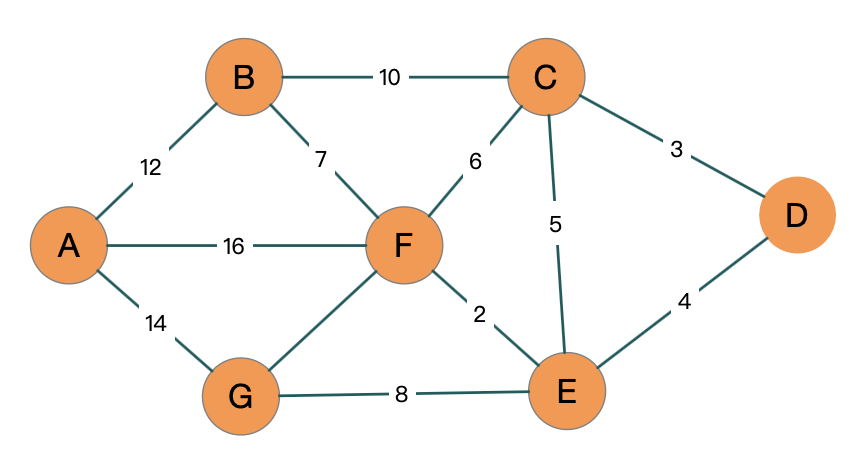
1 | |
最终也可以求出来 D 如果想要到 A 要走多少距离, 最少要走 22 的距离.
这个就是 Dijkstra 算法, 每次是通过集合 S 和 U 来去迭代 U, 找一个最短的路径. 这个方法原理建议大家能去明白, 高德地图的导航过程中也是采用这种方法, 在路径规划中这个方法的使用频率还是比较高的.
Floyd 算法
以上, 我们看到的是一个点到其他所有点的距离. 现在咱们变化一下问题,
变成所有点到所有点的距离, 这样我们就需要采用另外一种算法,
就是Floyd算法.
Floyd算法是先用一个叫邻接矩阵, 把邻居的距离做了一个标记.
我们还是来看这张图:
再来看相关距离矩阵
\[ \begin{align*} A = \begin{bmatrix} 0 & 12 & \infty & \infty & \infty & 16 & 14 \\ 12 & 0 & 10 & \infty & \infty & 7 & \infty \\ \infty & 10 & 0 & 3 & 5 & 6 & \infty \\ \infty & \infty & 3 & 0 & 4 & \infty & \infty \\ \infty & \infty & 5 & 4 & 0 & 2 & 8 \\ 16 & 7 & 6 & \infty & 2 & 0 & 9 \\ 14 & \infty & \infty & \infty & 8 & 9 & 0 \\ \end{bmatrix} \end{align*} \]
矩阵中无穷大就是未直接到达, 0 就是自己到自己. 这个距离矩阵是一个初始状态的矩阵, 没有距离也知识现在没有, 邻接矩阵表只看邻居. 所以到 C D E 都是无穷.
在代码中, 可以使用 NumPy 来创建这个矩阵:
1 | |
我用 99 来代替了正无穷,
这个其实只要是将距离数值放到最大就可以了. 这里从其他数值上来看,
即便所有所有点的距离全部相加也不会大于 99, 所以这里设置
99 就 OK 了.
然后我们来写几层循环:
1 | |
相比较而言, Dijkstra 算法的算法复杂度是 n 的平方,
两层循环. 这里Floyd则是三层循环, 有 k,
i 和 j, 那它的算法复杂度就会是 n 的三次方.
这个速度并不快.
循环之后, 我们来输出结果:
1 | |
我们用了i和j, 这是两个顶点,
在最前面的还有个k. k 在最外层,
如果找到一个比i 到 k 的距离加上 k
到 i 的距离小的就更新, 如果没有就不更新.
那在这里, 三层中的变量循环顺序是不能做颠倒的. 打比方说, 我们将
k 放到中间去:
1 | |
来看这次的结果, 是[25 13 3 0 4 6 12],
将之前的结果放过来做对比: [22 13 3 0 4 6 12]. 可以发现,
A 到 D 的距离发生了变化, 从 22 变成了 25.
这就说明, 这三层循环的顺序是不能进行颠倒的. 既然如此, 那就说明
k 在最外层一定有其含义的,
它的含义叫做阶段性.
我们可以把它分成不同的阶段去做迭代, 每次迭代都由顶点和终点去做遍历.
实际上Floyd的这个阶段的思想在算法里面是很有名的一个思想,
一般我们称之为动态规划, 就是换成多个阶段,
当前状态是只跟上一个阶段相关.
其实想一想, 在做最短路径规划的时候, 阶段是只跟上一个阶段相关.
比如你到了F, F 是上海, D 是北京.
那么到底是从哪里到上海的重要吗? 其实并不重要, 只要现在到了这个阶段.
到了这个阶段, 不管是从 C 来的还是 E 来的,
其实对后续的结果都没有影响. 从北京到上海这个状态只要是最小的,
不管到底是走这条路径还走哪条路径,
只要看上一个状态就可以了.
所以动态规划里面大量运用阶段的思想, 是跟上一个状态去做比较. 顶点的编号为了方便, 把它设为 1 到 n, 以两点之间最短距离经过的顶点中最大的顶点编号作为阶段, 两点间目前算出的最短路径作为状态的值.
假设\(f_k(i, j)\)为顶点编号
i 和 j 两点经过最大顶点编号不超过
k 的最短路径长度
\[ \begin{align*} f_k(i,j) = \min \begin{cases} f_{k-1}(i, j) \\ f_{k-1}(i, k) + f_{k-1}(k, j) \end{cases} \end{align*} \]
一个城市,
i到j经过的最大的中间城市不超过k,
那么它的距离肯定跟上个阶段相关. 如果i到j,
它的最大顶点距离是k-1, 在这里其实就不经过k.
如果他下一次不经过k, 他的最大距离还是k-1,
这就是一种可能性.
除了不经过k的还有经过k的,
经过k就要看i到k之间的k-1以及k到j之间的k-1.
除了i到k和k到j,
中间的顶点不超过k-1,
那么也就是说这两个阶段可以把它衔到一起,
那么在第二种可能性里面是一定会经过k的.
整个动态规划有两种可能性, 所以要对这两种可能性去求一个最小值.
所以这里的k代表阶段, 这个阶段是在最外层,
需要计算完才能计算下个阶段.
如果这个阶段还没有计算完就开始开启了下个阶段, 数据就有可能发生一些问题.
所以这里的k如果代表的是阶段的含义,
把它放到中间就有可能上个阶段还没有跑完又跑到下个阶段,
结论有可能是错误的.
因此在结论上去看k代表阶段应该放到最外层.
那接下来我们来看下使用NetworkX这个工具来求一下路径.
我们还是拿之前的数据来用, 先来看看路径
1 | |
从 Buffalo 到 Kent 是直达的, 到
Rice 中间是经过了两个顶点.
接着我们来看一下Dijkstra算法的结果:
1 | |
Dijkstra 是看一个点到所有点的路径.
第一个看Buffalo到所有点,
第二个是看Buffalo和Rice这两个点到其他所有点的路径.
然后还有就是Floyd的一个结果:
1 | |
Floyd 整个G里面没有指定路径,
计算的是G里面任何两点之间的距离的路径.
打印出来的结果还是蛮多的, 这里只是放了一点, 大家可以自己跑一下看看.
28. BI - 图论工具和算法, 社区发现以及最短路径

