29. 深度学习进阶 - 卷积的原理

Hi,你好。我是茶桁。
在结束了 RNN 的学习之后,咱们今天开始来介绍一下 CNN。
CNN 是现代的机器深度学习一个很核心的内容,就假如说咱们做图像分类、图像分割,图像的切分等等。
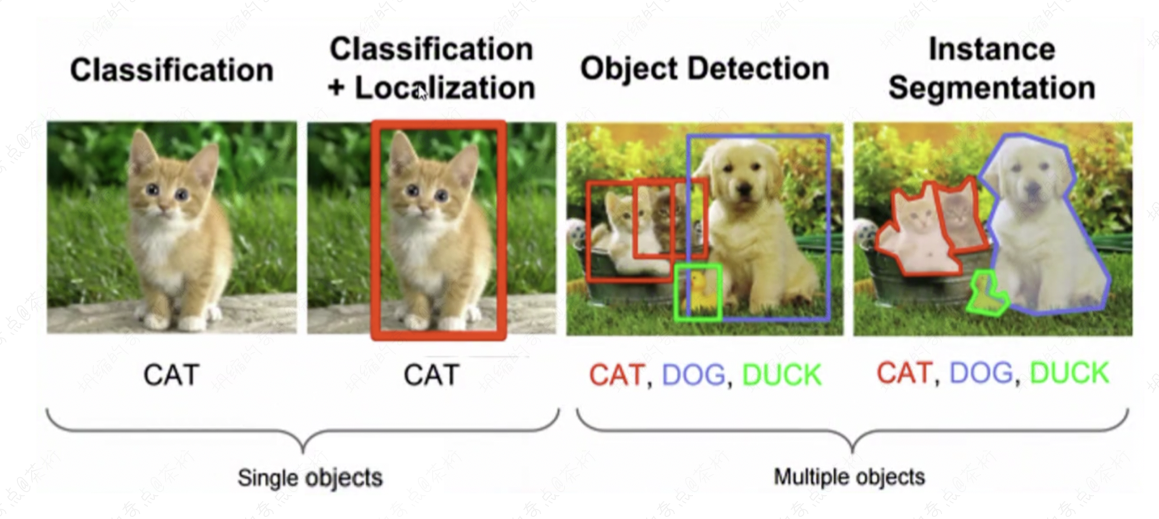
其实这些过程就是你让计算机能够自动识别,不仅能够识别图像里有什么,还能识别图像里这些东西分别是在什么地方。这种复杂操作其实都是基于啊 CNN 的变体。要给计算机有识别图像的能力。
再比方说大无人驾驶汽车,它要识别行人在哪里。
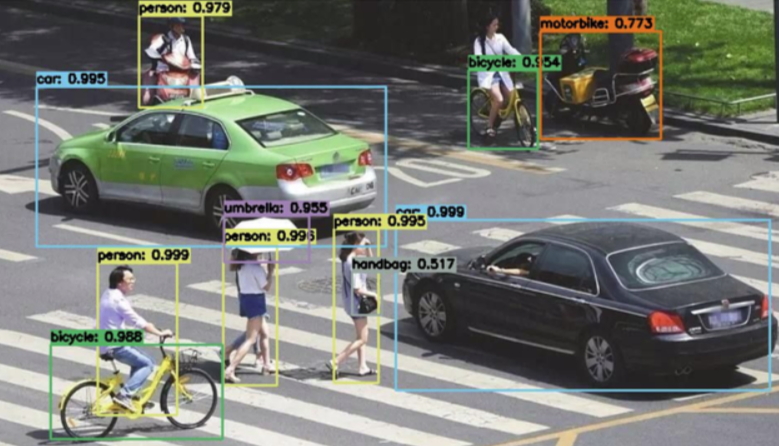
再比如安防的摄像头,要能够检测出来我们人在哪里。
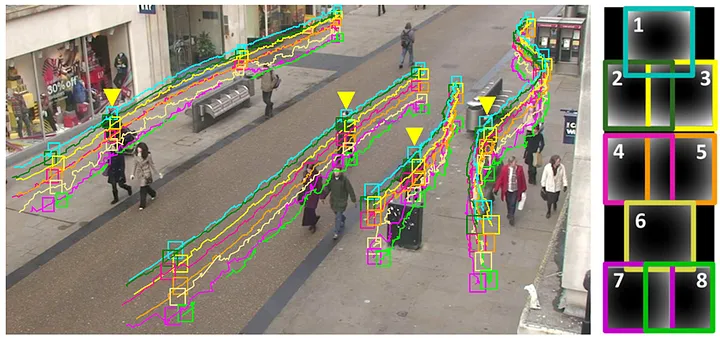
这些事情背后都是计算机视觉的问题。
大概一九五几年、六几年的时候,哈佛大学曾经做过一个研究,给猫的大脑上装了一些电极,让这个猫去看前面的一个幻灯片,然后通过切换幻灯片的内容,然后观察猫的大脑哪些地方活跃。
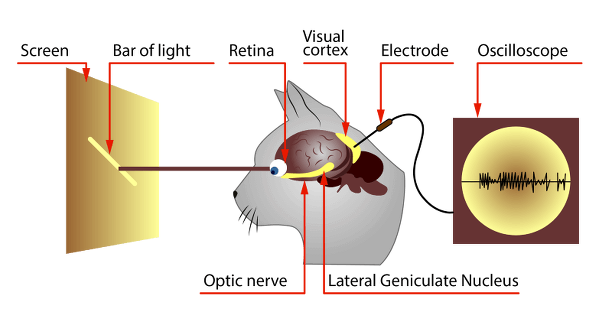
就发现两个特点,第一个它有一种一层一层的特性,比方说我换了颜色,它固定的就这几层会活跃,离眼睛远的地方会活跃。如果换了线条,颜色没变,会是另外的一层区域会活跃,不同层其实对于不同的特定变化是不一样的。
第二个发现,越靠近眼睛的地方,越低级的层次的变化会越明显,比如线条颜色。眼睛越远的距离,线条和颜色没变,但是眼睛变大了或者变小了,那么这些地方它会更明显。
也就是说,第一个它是有分层的,第二个,它不同的这个层的抽象性是不一样的,对于什么东西的感受力是不一样的。
沿着这个思路,人们当时就提出来了一些方法。当时人们做计算机视觉,主流不是机器学习。但是人们提出来一个一个这样的 filter:
1 | |
这样的 filter 是人刻意的,主观的提出来的。他们把这个 filter 去应用到一个一个的图像上。
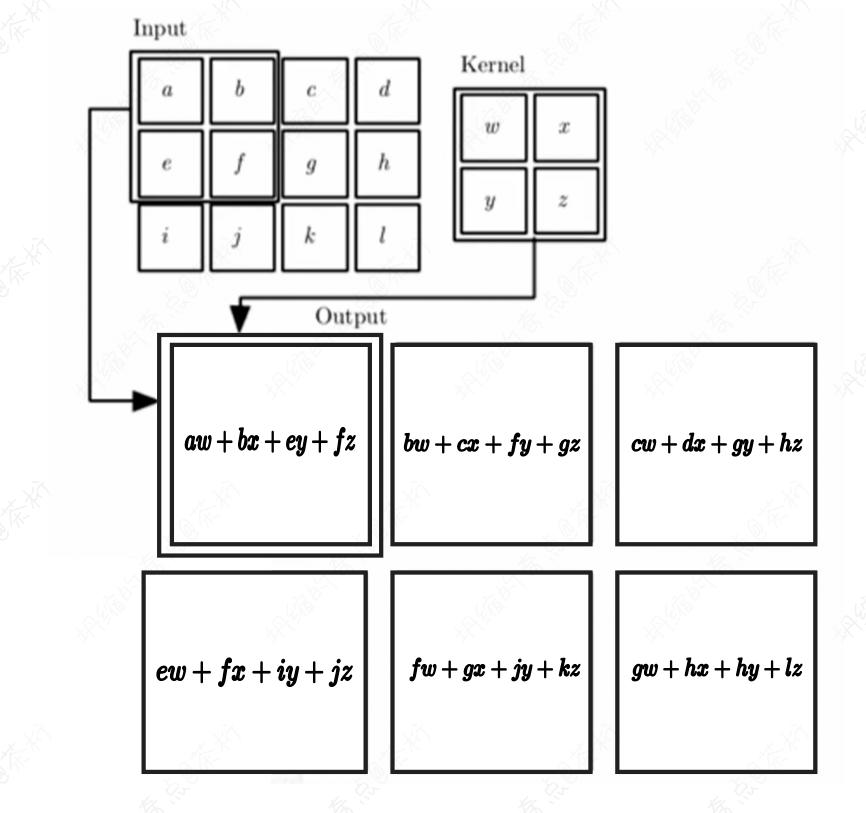
比方说我们的图像是a b c d e f g h i j k l,然后按 4*4
的矩阵相乘,再加起来,比如\(aw+bx+ey+fz\),这样就得到了一个新的内容。大家把这个操作就叫做卷积操作。
看个示例:
1 | |
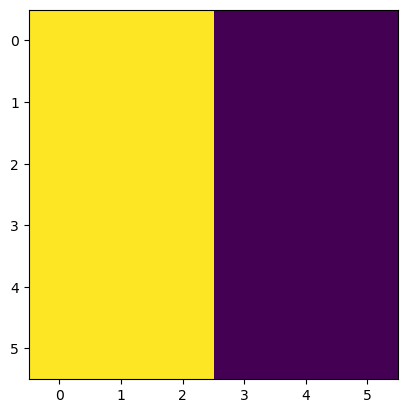
我们可以看到,这个矩阵的前三列全是 10,后两列都是 0,最后生成的图像有一个明显的分界,伴随着两个不同的颜色。
我们现在给这个图像矩阵加上一个 filter, 然后按上面的方法进行操作:

那左上角的 3*3 的小矩阵的运算结果就是 0。
那同理,我们以此往后算,第二个结果是 39, 第三个结果是 39.... 大家后面可以自行计算一下,最后的计算结果就是:
1 | |
我们可以看出来,当分割的小矩阵内数据相同的时候,值为 0,如果说矩阵内的这个部分图像差距不是很大,那它也是近乎接近于 0,意味着差别很小。如果说分割的这个小矩阵左右两边是相反数的时候,两边的差别是最大的,不管最后相加的值是正的还是负的,绝对值下应该是最大的。这个地方其实是图像竖着的边缘。
那如果我们将 filter 改一下,改成下面这样:
1 | |
如果是这样,计算的结果就是图像横向的边缘的绝对值最大。
基于这种原理,我们就可以找到图像所有竖向和横向的边沿,给它拿出来。
这整个的一个过程,就叫做卷积: convolution。convolution 就是两个东西之间互相起作用。最早是出现在信号处理上,两个信号把它做一个合并。
卷积的操作是为了干什么呢?卷积的操作是用来提取图片的某种特征,抓取图片特征。在上个世纪后期,计算机视觉的老科学家们提出了大量的 kernel,当时叫做算子,现在叫做卷积核。
卷积的操作就是给定一个图片,然后给定一个卷积核,和卷积核一样大小的窗口里边的每个值相乘,相乘之后再做相加。
假如咱们有一张图片,一般来说,咱们现实生活中图片往往是三维,通常是红绿蓝(RGB),然后我们让这张图片和这个 filter 去做相乘的操作。
这三个层里面每一层都会和 filter 做一个相乘的操作,咱们就假设这三个层分别为:
1 | |
然后再假设 filter 为:
1 | |
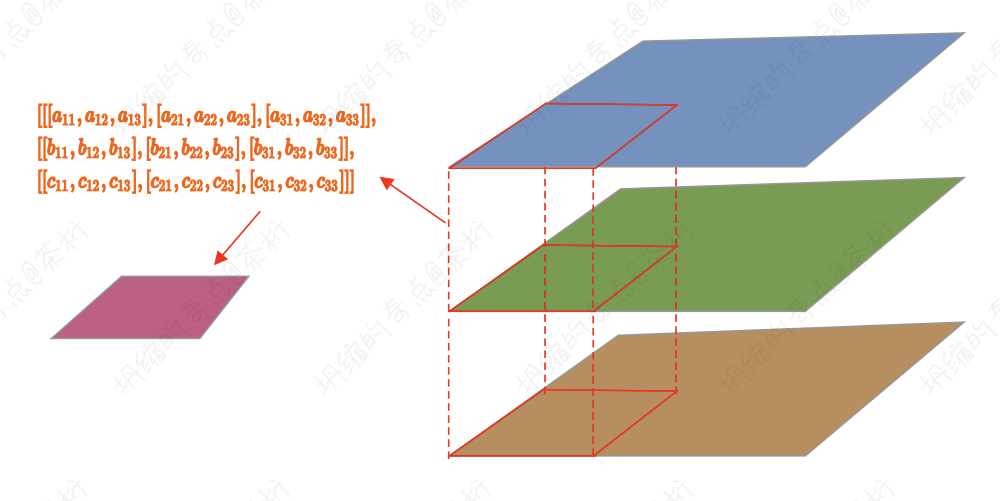
那这个 filter 会分别和这三个层进行卷积操作,产生的卷积结果为 v1, v2, v3, 然后这三个结果再进行相加,最后会产生一个新的层。
我们来看一下下面这张图:
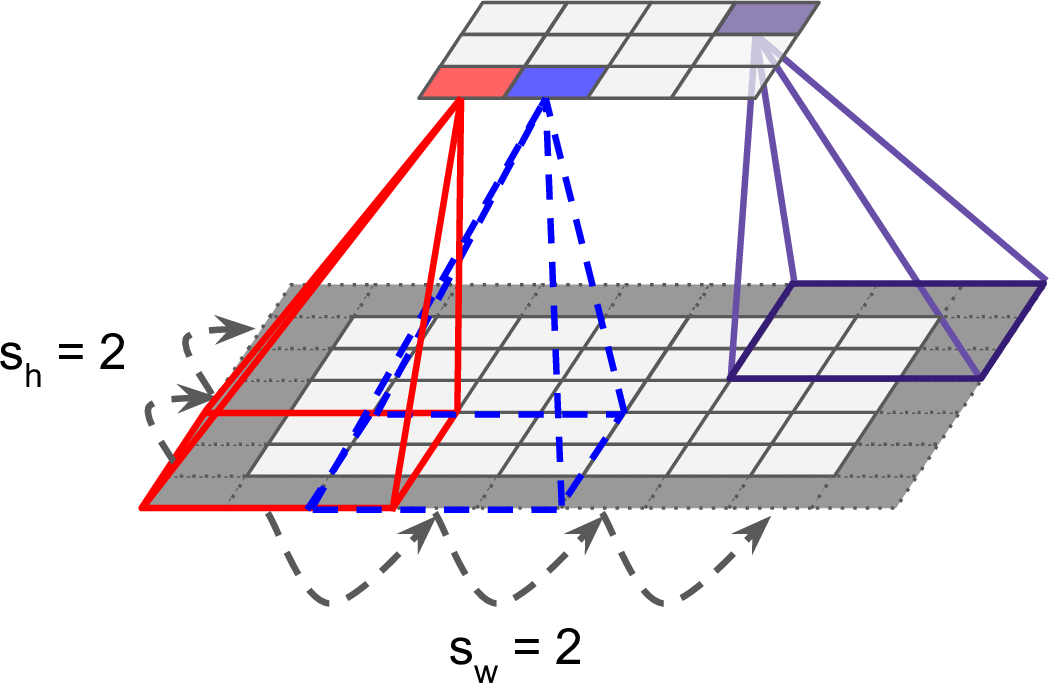
这张图显示的是一层的情况,一个 filter 大小的矩阵被卷积成了一个点,然后这个操作不只是针对一层的,而是对整个一个纵向体积内的所有层都做这样一个操作:
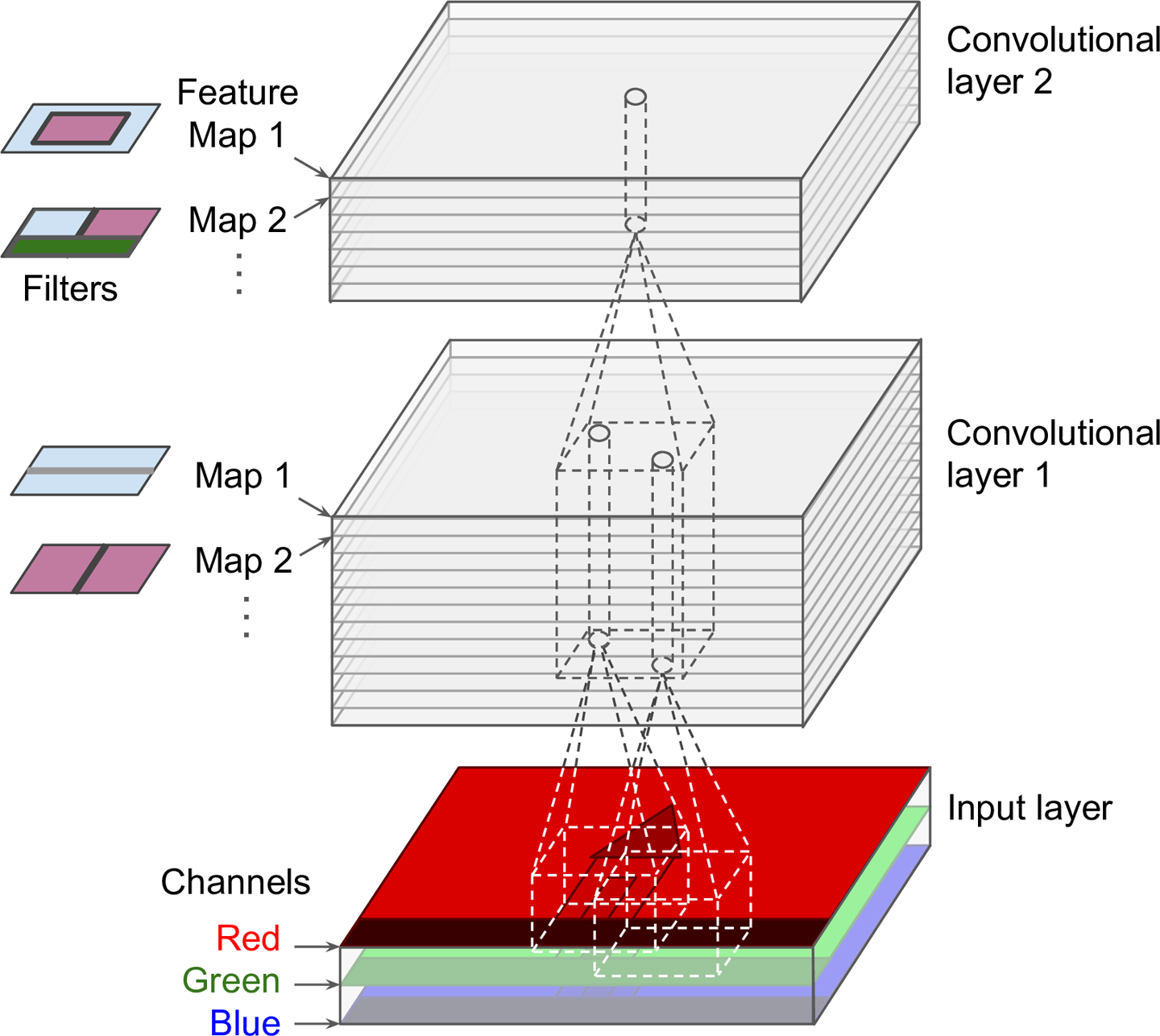
途中最底下是我们的图片的 RGB 分层,再经过和 filter 相乘之后向上会卷积成一个点,那向上之后的 Map1, Map2,... 原因是每一层都是一个不同的 filter 计算的结果,这里存在很多个 filter, 然后分别计算产生了这样一个叠加层。
再做下一次运算的时候也是一样,这些 Map 的纵向上经过和 filter 运算依然会被卷积成一个点。
就着上面那个简单的图形,咱们来做个演示:
1 | |
输入一个图片的数据, 拿到 filter 的高宽,然后让 filter 沿着图片从上到下,从左到右移动。
我们打印结果能看到,运行到中间的时候会出现一串的[[-3], [-3], [-3]]。因为 i 会一直运行边上,那么如果要做卷积的话,大小要和 filter 一直一样,所以咱们在这里需要给他减去一个 filter。就是不要运行后边这几个。
1 | |
这样就可以了。
我们每一次其实就是从左到右,从上到下裁剪出来一个一个的 window。
我们让这个 window 和 filter 相乘后再相加,我们可以得到什么结果?
1 | |
就是计算卷积的结果。
那我们可以将其改成矩阵的形式, 然后咱们打印出来看看是个啥:
1 | |
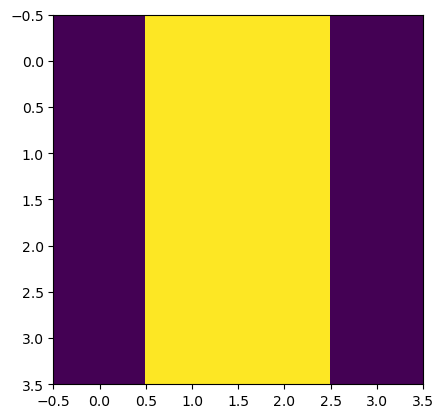
那变成这样的原因是因为原来的图像中间有一个边缘,现在这张图显示的是图片边缘的部分被高亮。
这样一张图片可能并不太能理解,我拿我的头像来做这个示例好了:

1 | |
为了更明显一点,我将图像改成灰度显示。
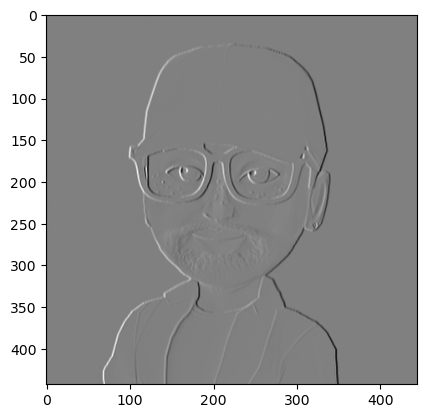
我们可以看到卷积之后的效果,明显边缘都被显示出来了。但是我们也注意到了,竖向的边缘都很明显,但是横向的边缘并不清楚。我们再来对横向进行一下卷积, 我们先要增加一个处理多个 filter 的方法,将原来的 conv 方法改为 single_conv, 表示处理单个:
1 | |
然后我们的调用需要改一下传递的参数:
1 | |
既然要传递两个 filter, 那我们就需要再定义一个横向的 filter,然后一起传进去:
1 | |
接着我们将原图,竖向的卷积结果和横向的卷积结果都打印出来:
1 | |
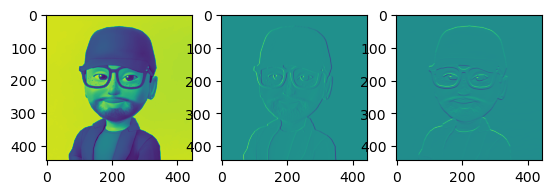
原图变成这个颜色的原因是我在 PIL 读取图像的时候,将其转为了灰度。我们可以看到第二张图片和第三张图明显在边缘上的区别,一个像是灯光从左边打过来的,一个像是灯光从上面打下来的。
中间和右边这个,其实都是把边缘提出来了。因为卷积核的不同,中间这个图把竖着的边缘明显提取的比较准确,右边的把横向的提取的比较准确。
这也是为什么我们之前看得那张图里会有那么多的 Map:
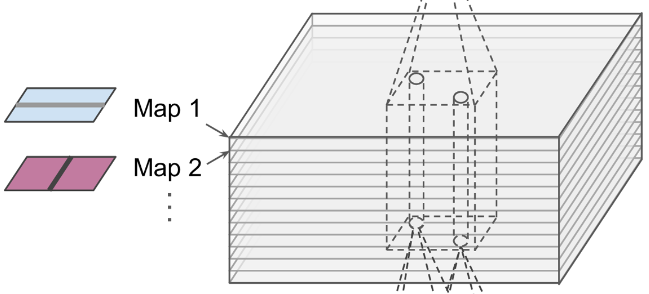
它的每一层都是一个不同的 filter 提取出来的,有这么多 filter 的原因则是每一个 filter 提取出来的特征都是不一样的。
我们来看我们刚才定义的方法:
1 | |
我们把输入卷积的时候的 image
这个参数叫做input channel。那在此时此刻,我们这个图像如果是
RGB 的,它就是三维的,那么input channel就等于 3。
filters的个数,就叫做output channel。原因就在于,有多少个filter,那我们的
results 就有多厚。比如说我们有 4 个filter, 那输出的 result
就有四层。 然后可以接着对 results
继续应用filter做卷积,那在这一轮的input channel就等于一次的output channel,
也就是 4。
这个,就是卷积的原理。
好,这节课就到这里了,下节课咱们继续学习卷积,来看看在神经网络里如何应用。
29. 深度学习进阶 - 卷积的原理

