31. 深度学习进阶 - 全连接层及网络结构

Hi,你好。我是茶桁。
之前的课程咱们学习了卷积以及池化,那到底卷积是如何构成卷积神经网络的呢?我们这节课来好好讲一下。
全连接层
整个卷积的运算就是经过卷积,再经过 pooling,再经过卷积。会把这个图形变的很小。然后再经过 pooling,又会一直把我们的特征变得越来越小,之后有一个很重要的层,这个层叫做全连接层。
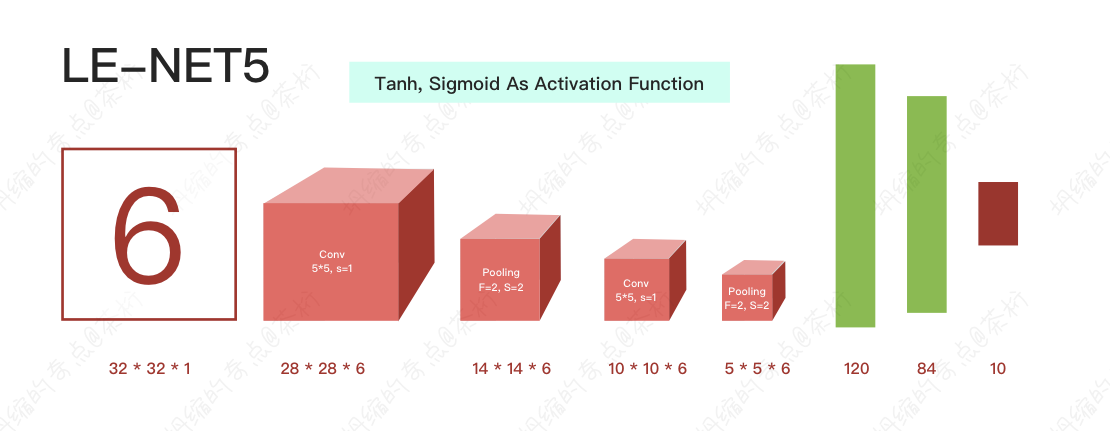
后面的几个柱状图就是它的线性变化,就是它的全连接层。
先是将图片卷积、池化变小,变成很小的高级特征,然后拉平之后进入全连接层进行线性变化。 这就是卷积操作的整个工作流,也是为什么卷积操作需要的参数少的原因。
我们在这里重点说一下全连接层。
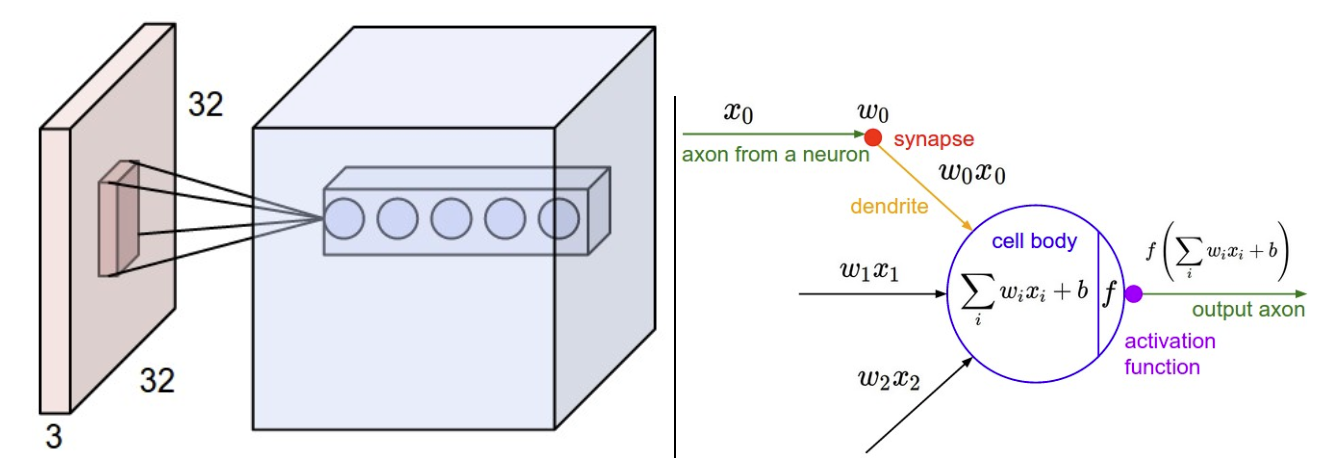
我们做了很多 pooling,
很多卷积之后,我们会生成一个很厚的一个值。把很厚的这个值给他拉平,在
PyTorch 里面直接就 flatten, 或者用 reshape 直接进行,把它拉平成一个 1
乘以 n 的一个向量。然后给这个 1 乘以 n 进行熟悉的wx+b。
我们对它进行线性变化,第一是对它的维度进行了变化。假如要给它变成一个 10 分类,纬度进行的变化。
另外一点,我们每一层都会有不同的特征点,这些特征点代表这图像不同的位置把它抽象成的值。然后一层一层的,又是不同的 filter 的结果,提取出来的不同的特征。比如横向,竖向之类的。机器可能还会自动提取一些颜色,形状等等。
那么现在我们要把这些东西进行一个综合考量,要把这些信息全部拿起来综合做个判断。比如我们有三个 filter, 也就是有三层,这三层里面拿出四个位置。 那么拉平的画,就变成 3 乘以 4,这里面有 12 个数值。这 12 个数值提取出来通过不同的方式了,关注点不同,提出来的 12 高级特征。
现在要把这 12
个高级特征全盘考虑、综合考虑。我们要给这些数据加一个不同的权重。就要给它做一个wi * xi,就给它这些全盘综合做了一个权重的这个赋值。
所以说,全连接不仅对维度进行了变化,它还对之前提取出来的局部信息进行了综合,这个就是全连接层的作用。既进行了变化又进行了维度信息的综合。
所以说,大家看一下
这些不同的著名的网络结构,都是进行完之后要进行线性变化,线性变化之后把它变到我们期望的 target 上,就是最前面的这些东西进行综合。
算出来这个数值之后,然后用全连接层进行分类。但是全连接层不一定是只能进行分类,其实还进行特征的一个变化。
进行线性变化完了之后,通过 Softmax,然后再给它进行 cross-entropy,就可以求出它的 loss 值了。
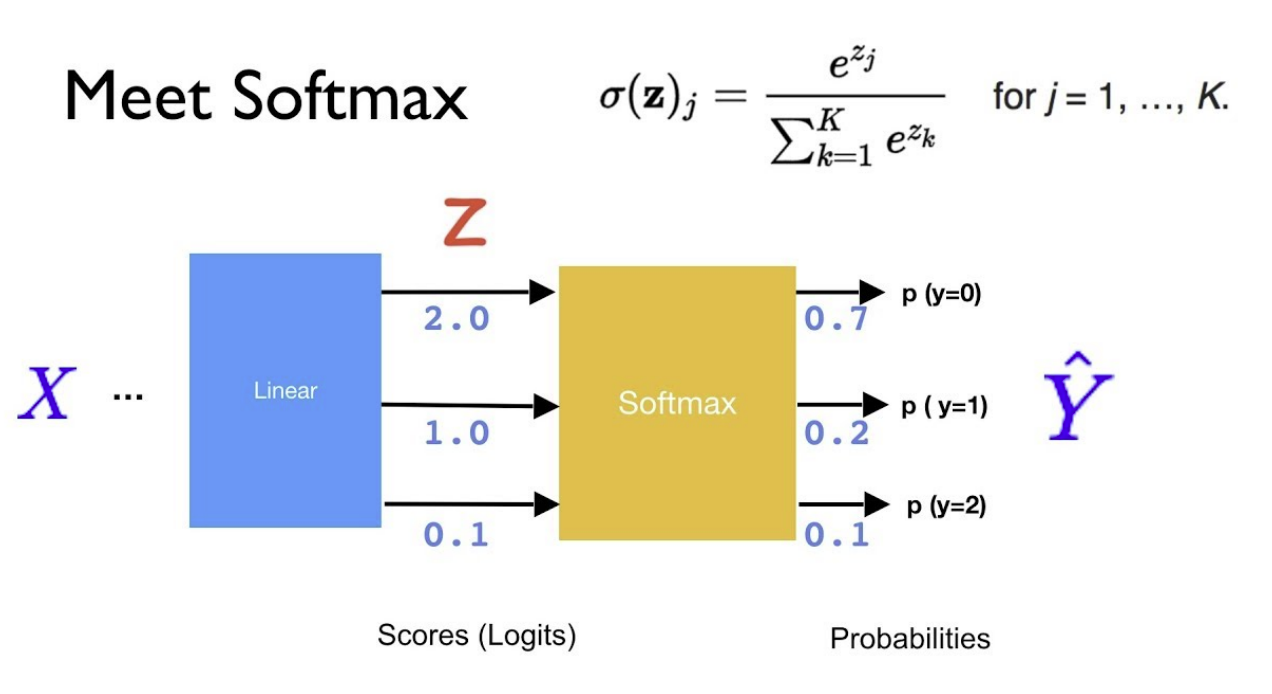
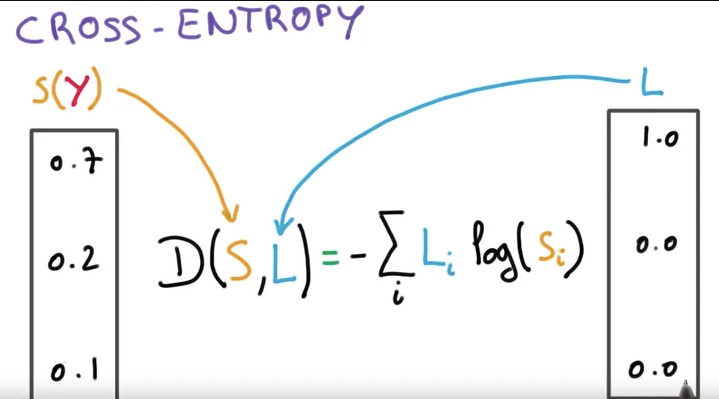
其实最近几年,就从 2019 年左右开始呢,其实大家慢慢的不用 Softmax 和 cross entropy 了,当然用这个也可以。为什么不用了呢?
比方我现在有三个图片,IMAGE1、IMAGE2 和 IMAGE3,对应的 label
分别是3、5、6。那么要做 cross-entropy 的时候,就要把 3
变成[0,0,1,0,0,0,0,0],然后 5 和 6 都要进行变化。然后才能跟
Softmax 预测出来这个 probability 做
cross-entropy。也就是说,在这里要进行一次 one-hot
编码。结果后来就发现可以做一个简化操作,进行了 Softmax 之后给它前面加个
log。
假如说,Softmax 之后是0.1, 0.3, 0.3, 0.2, 0.1, 给它加个
log,就会是一个负的比较大的数字,越接近于 1,比方 0.99,越接近于 1
结果会越接近于 0,越远离 1,这个负的值会越大。
所以现在大家会有一个非线性变化,叫做 log
Softmax,出来的结果就是负的。然后还有一个 loss 叫做NLLloss,
negative log likelihood loss,这个在 PyTorch 里边也有。
这个有趣的地方就来了,如果我们它的 label 是 3,直接来看一下 log
之后的值是不是-3, 给它再取个负号,那么就直接说这个的 loss
是3。如果它的 label 是 5,那么 log
之后是另外一个值,假如说是-0.7,那么它取
5,我们发现结果是-0.7,加个负号,它的 loss
直接就是0.7。
这样就不需要进行 one-hot 编码了,而且也能达到一个效果,就是我们期望的地方越接近于 1,loss 越接近于 0。
所以,现在在工作中,我们看大量代码都开始这么做了,相当于是一个简化板的 Softmax。
那这个呢就是我们整个卷积神经网络的工作流程,全连接层的作用大家一定要知道。
好,我们做一个总结。第一节课,给大家讲解卷积的原理。那么什么是卷积神经网络呢?只要用了卷积(Conv)这个操作的网络, 它就叫卷积神经网络。所以理论上,你可以让一个图形先经过卷积,再经过 RNN,再经过卷积,再经过 RNN,都可以。这个你既可以叫它卷积网络,也可以叫它循环神经网络。
然后呢跟大家说了 CNN 可以用在很多地方,比方说分类,探测,还有分割,其实背后都是卷积神经网络在做。
还有给大家讲了 filters, padding, stride 和 channel,它的作用。除此之外,我们讲了 Parameters sharing 和 Location Invariant。
在整个过程中,我们哪一层做卷积,哪一层做 pooling,线性变化做几层,是不是纯靠经验?说白了这个确实还是纯靠经验,所以有一个很重要的特点就是我们需要去借鉴,我们需要去借鉴前人的经验。
几种神经网络结构
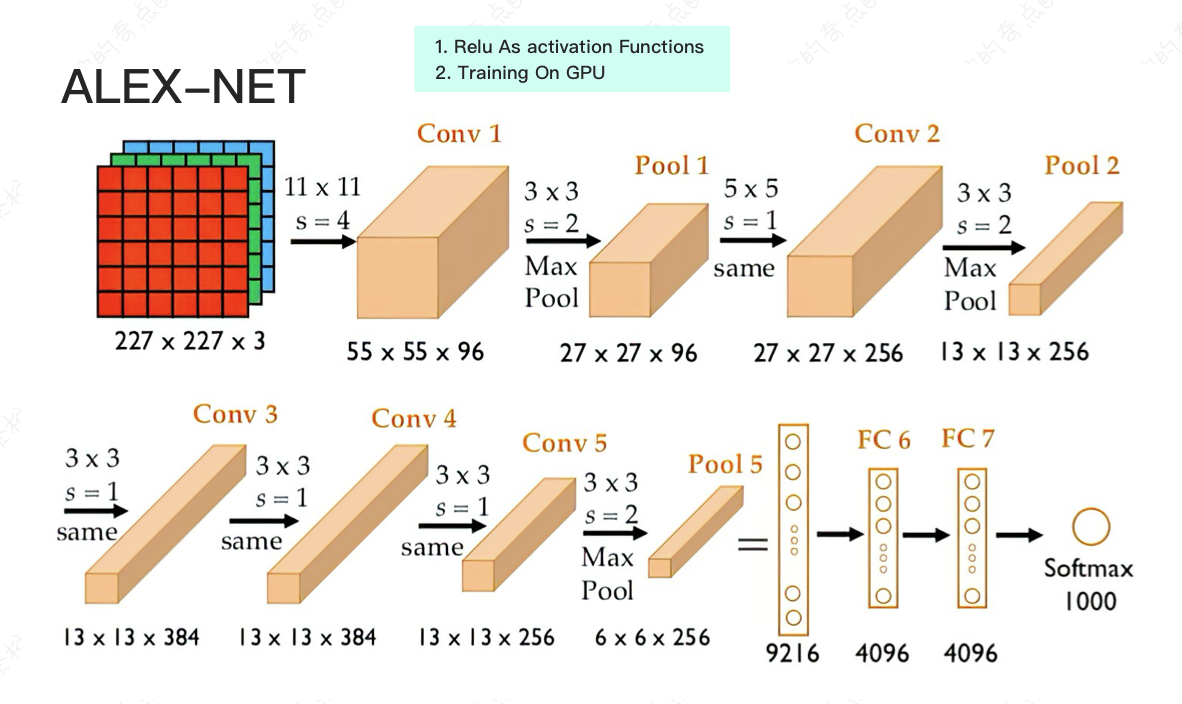
我们需要看前人的网络结构是怎么搭的,有几种比较重要的结构,LE-NET5,ALEX-NET。Alex 那个 net 结构就是 2012 年 ImageNet 取得第一名的,上面有图。
它的特点就是第一次用 Relu 去做了非线性变化, 作用就会进行的比较快,它还在 GPU 上进行运算。
Relu 就是一个非线性变化,如果把它做了卷积操作之后,给它再加个 Relu,可以把它值再进行一个非线性变化就可以了,就是把它卷积出来的结果做了一个非线性变化。
GPU 运算的作用是什么呢?GPU 为什么重要?
假设现在有一张 1 万 * 1 万的一张图,有 3 * 3 的卷积核,如果说原始的状态我们得先从左到右再从上到下的做。我们得进行 998 乘以 998 次移动。
有 GPU 的话,我们可以让其中一部分在 GPU 的某个地方进行计算,另外一部分同时在 GPU 的另外一个地方计算,就可以分布式的。因为 GPU 所做的事情就是把矩阵运算可以分布式的在不同的地方并行运算。
这就是为什么有 GPU 玩游戏不卡,因为加载图片的时候它一部分图片在 GPU 某个地方加载,另外一部分图片在 GPU 另外一个地方加载,这是同时一起加载的。
如果年龄在 30 岁以上的小伙伴应该知道,以前看网页的时候那个大的图片会一行一行显示出来,就 90 年代末那会儿,图片是一行一行一行显示出来的。而对于 GPU 的话,显示图片是一块一块一起去渲染的。
那么对于卷积神经网络来说,这一块一块的 filters,也是一起渲染一起计算的。所以说在做一层的计算的时候它就快了。而且如果你的 GPU 足够多,你还可以让它每一层的 filters 也并行计算。每一层的 filters 在每一块上又可以快速计算。
所以有了 GPU 的运行速度可以快十几倍,二十几倍,甚至上百倍都可以。
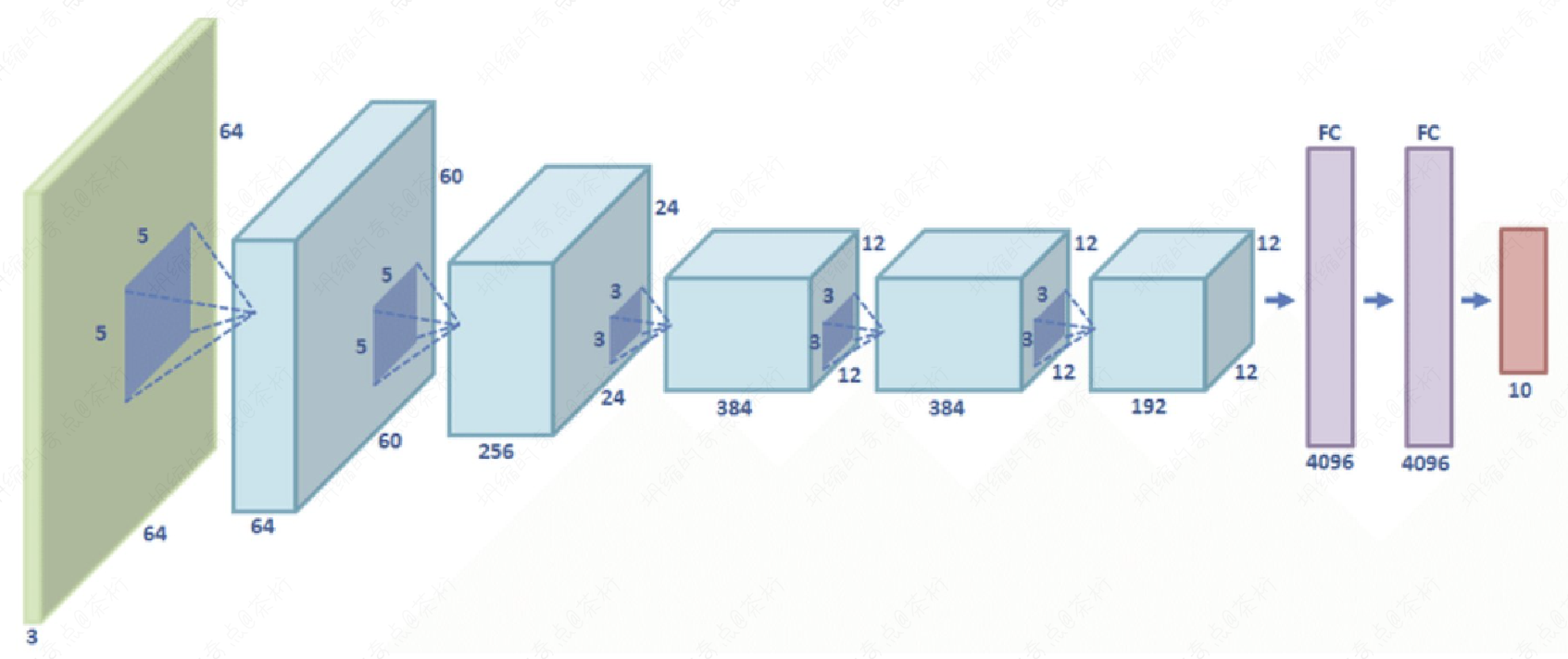
然后是 VGG-NET。
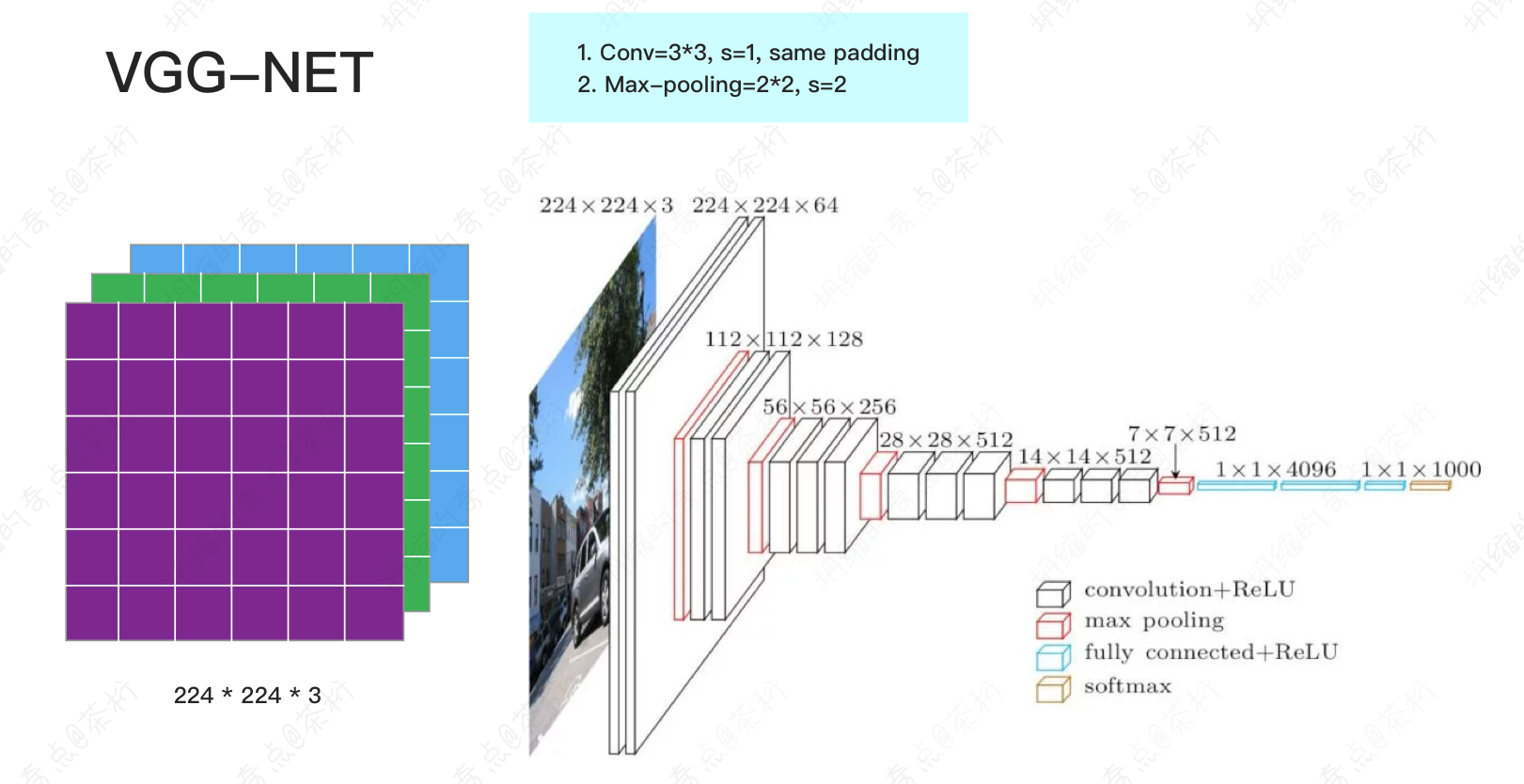
VGG-NET 是第一个真正意义上的深度神经网络,我们看这张图,它门一层都向下做了一个下采样。不断的下采样的结果是可以获得一些非常深的 feature,或者一些非常高层次的 feature。
VGG 当时取得的效果也非常的好,也学的非常好。但是随着 VGG 正式的把我们带到深度神经网络这个过程中,我们就发现当网络特别深的时候会产生一个问题。
我们回忆一下,之前的课程中有讲过,当网络特别深的时候会产生什么问题?
我们之前课程里有说,当网络特别深的时候就会产生梯度消失。
首先做这个变化的时候它的体现倒不是说就是会梯度消失,而是和梯度消失很类似。就是这个图片在前面运行的特别长,如果这个 filter 有几个值比较小,那么值经过 filter 值会变得很小,再经过一个 filter 又会变得很小。
到最后,原来的图像区别还挺大的,经过几次卷积之后呢,就都变成了很小的一些数字,展示出来就近乎一张纯色的图片。
这个其实在哲学上也可以理解一下,当你的抽象层次特别特别高的时候,全世界的东西都一样。对吧,就很佛系,科学尽头是神学。当你的抽象层次极高的时候,你看全世界所有东西都一样,在 CNN 里也一样,当你的这个东西足够长的时候,最后得到的东西它都差不多。
所以为了解决这个问题,就提出来一个重要的神经网络叫做 RES-NET。
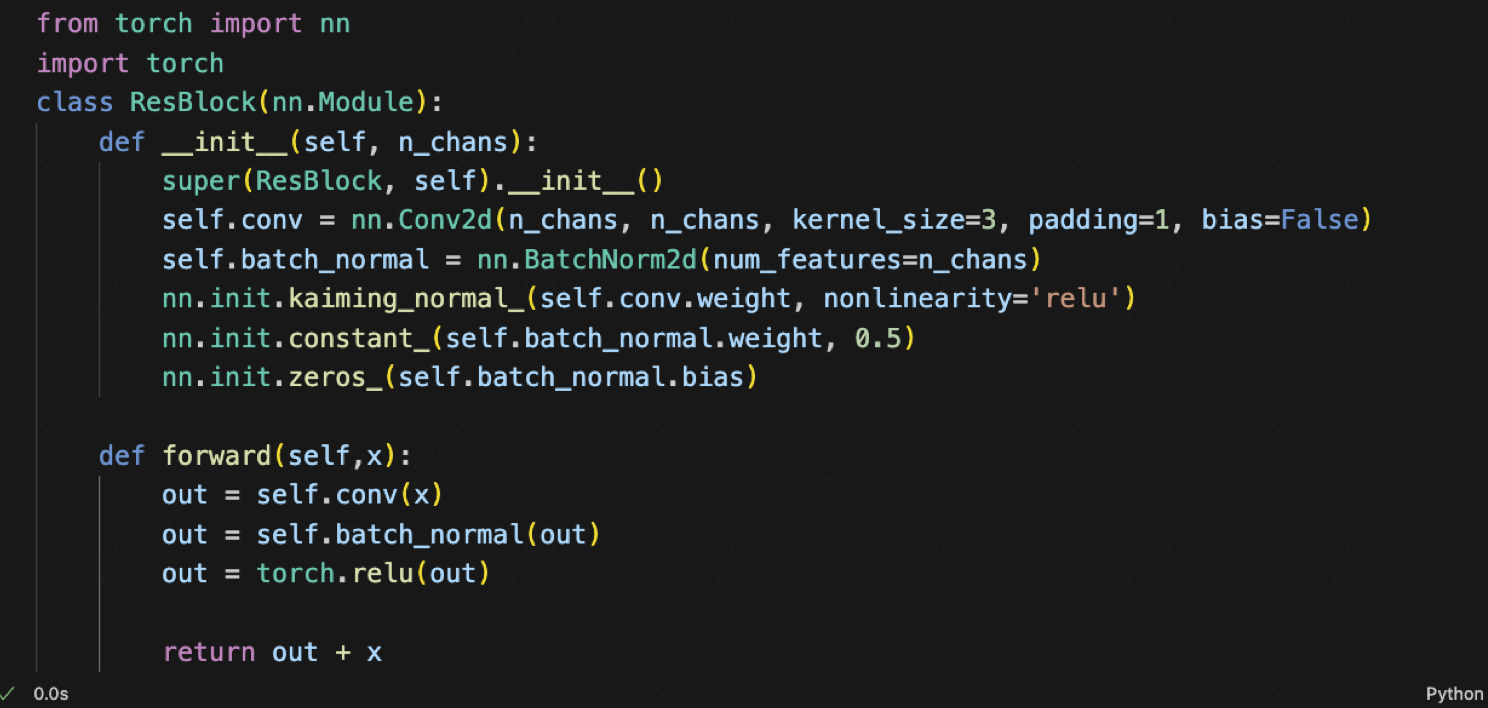
这个叫做残差网络,这个残差网络是非常重要的,是微软亚研当年提出来的。
2015 年用了 RES-NET 造成了计算机视觉的识别率超过了人类眼睛的识别率,所以 2016 年是 AI 在产业中开始落地的第一年。
当然它的原理并不难,但是经过这样的一个修改,使得我们计算机识别网络的准确度超过了人类,然后开始了这个产业落地。
截图中是 RES-NET 的一个 Block。
1 | |
向前运算的时候输入 x,经过了卷积,之后再给它进行一个 Batch normalization ,它的那个值就把小的变大,大的变小。然后再进行一个 Relu 非线性变化,输出的是 out 加了个 x。
这句话就是我们所谓的 Residual 的意思,就是理论上我们只要输出 out 就行了,但是为啥要加 x 呢?因为当经过很多层之后,out 可能会变成 0,变成一个纯色图片。所以把 x 加上,就是它还是保留了它的主要的图片信息,但是它在 out 上又有一些小的变化。这就是 RES-NET 的原理。
如果我们现在想做一个深的 RES-NET 的话怎么办?你给它输入一个三维的图片,比方说 32 个 filters。
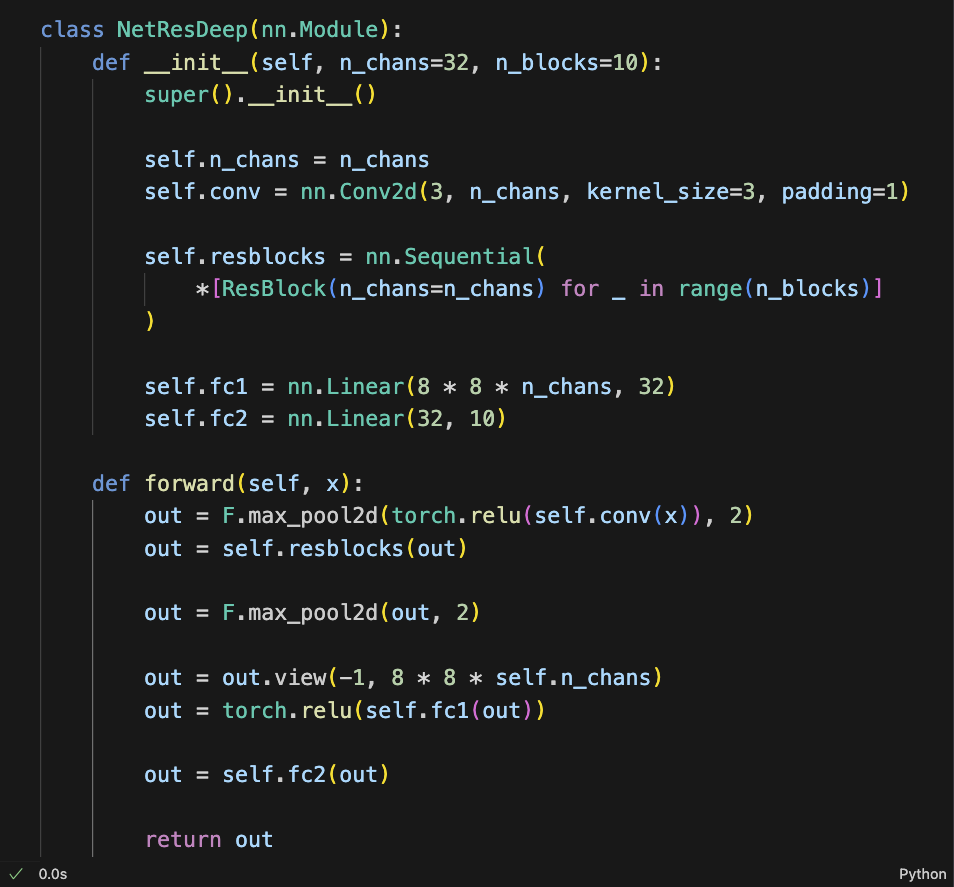
然后我们进行了一个 ResBlock:
1 | |
这个地方其实相当于是 ResBlock
之后,输出的x+out又给它输入到了一个
ResBlock,又是一个x+out。
我们这里Sequential的意思就是做完了这个,它的输出直接给下一个做输出。
在这个过程中,先让 x 进来做卷积、做非线性变化、做 pooling。然后把它送到一串 ResBlock:
1 | |
这一串 ResBlock, 它有很多个 ResBlock,一层一层运行下来。之后,做了一个 pooling, 之后做拉平,拉平之后在做一个全连接,就是对个权重进行线性变化,变化完了之后再加了非线性变化,最后再做一个线性变化。
这里的fc2,我们定义的维度是 10,意思就是把它要变成一个
10 分类的任务。
然后我们再给它做个 log Softmax,或者说 cross-entropy,或者是 NLL,就可以给它进行反向传播了。
这整个过程就是咱们的 RES-NET。
只要这个网络有 ResBlock,或者类似于 ResBlock 的,它都叫 RES-NET。就像只要有卷积这个单元的网络都叫卷积网络一样。
这句话的意思是说,RES-NET 其实有很多种。比方下面这张图,就是一个非常著名的 RES-NET。
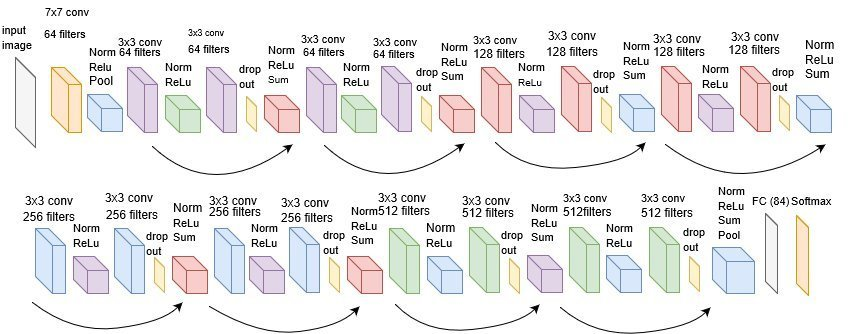
咱们刚才写的那个 ResBlock 是最简单化的 ResBlock, 这个 ResBlock 是 x 进来之后,首先有一个卷积,卷积之后又给它进行了一个 Batch normalization,normalization 之后又进行了一个 Relu,然后又进行了一个 drop out,再之后再给它进行一个 Relu,然后再 sum,加上 x。
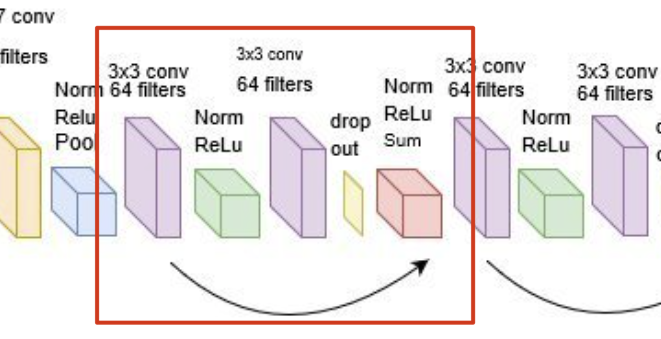
这个是刚才我们写的 ResBlock 的一个更复杂的版本。这个网络结构是 RES-NET 的一个经典结构。
RES-NET 的经典结构一共有这么几种:ResNet-18、ResNet-34、ResNet-50、ResNet-101、ResNet-152 几种。ResNet-18 和 ResNet-34 的基本结构相同,属于相对浅层的网络,后面 3 种的基本结构不同于 ResNet-18 和 ResNet-34,属于更深层的网络。
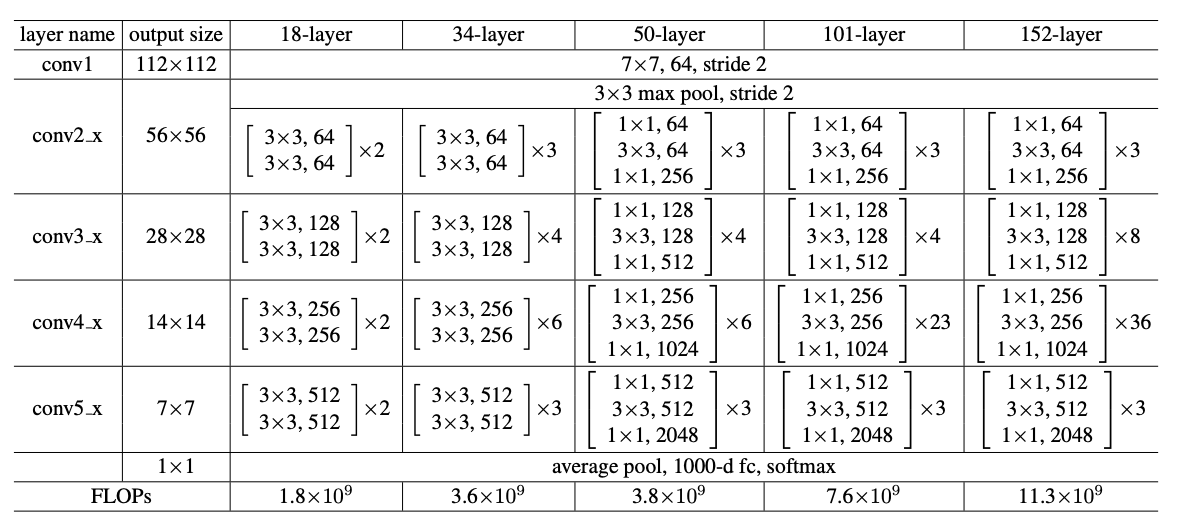
感兴趣的可以去看看这篇论文:https://arxiv.org/pdf/1512.03385.pdf。
这五种结构都可以实现,但是它们的具体实现方法不一样。
RES-NET 内理论上全部是卷积,没有全链接。全连接的部分其实是放在外边的。
RES-NET 它的实现过程含有一点工程上的东西,如果是想要做计算机视觉的小伙伴,就需要想起的去学习一下这个部分。之后我会有专门讲 CV 的部分,会更详细的讲解。
然后我们再来了解一个 Inception model, 直译的话称之为「初创模型」,一般大家都把它叫做 inception。它是 Google 在 RES-NET 提出来之后提出来的一个神经网络。
Google 的神经网络提出来的这个 Inception
机制有一个很很奇怪的点,就是它提出来了一个操作叫做1*1 convolutional,
意思就是我们把之前的卷积操作的那个kernel_size变成了
1*1,就是变成一个点点。变成一个点点之后再加了一个非线性变化。
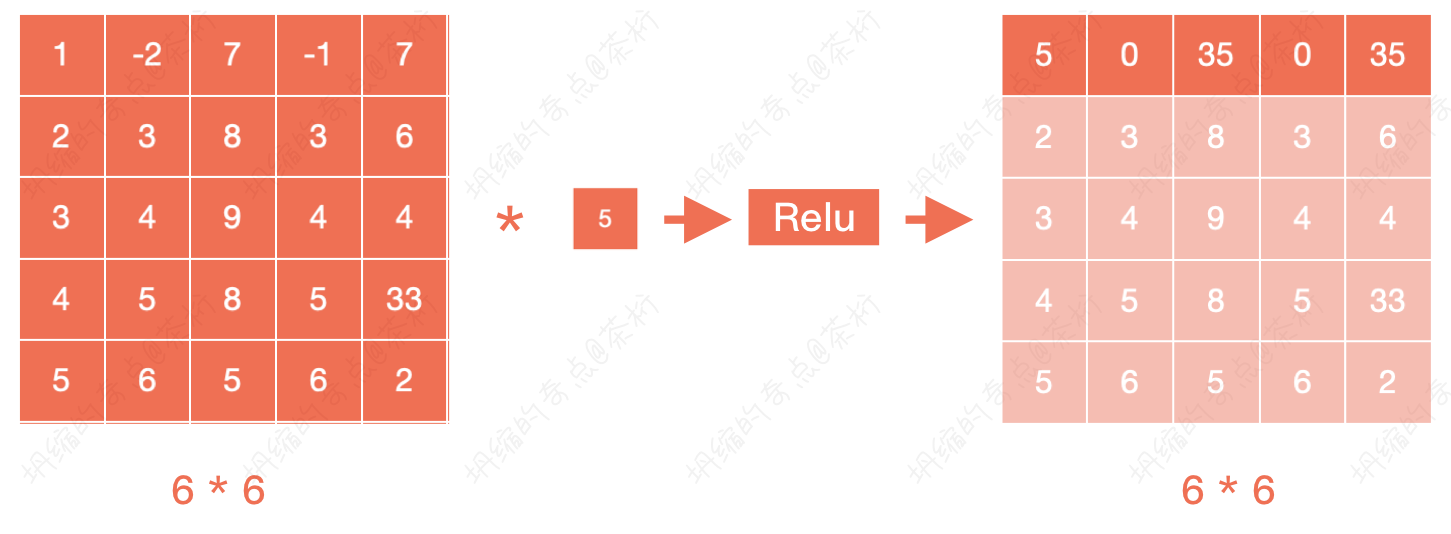
这个权重也是刚开始随机的,后来是学习出来的。
它相当于是把整个前面的图形,整体每个数字乘了一个数,然后再给它进行了一个非线性变化。
也就是说,如图 1 * 1的位置是
5,相当于把前面矩阵内所有的数字都乘了个
5,然后再进行了一个非线性变化。
假如现在有一个8 * 8的照片, 包含 RGB
就是8 * 8 * 3,现在有 5
个1 * 1的卷积核,那么得出的结果应该是多少?
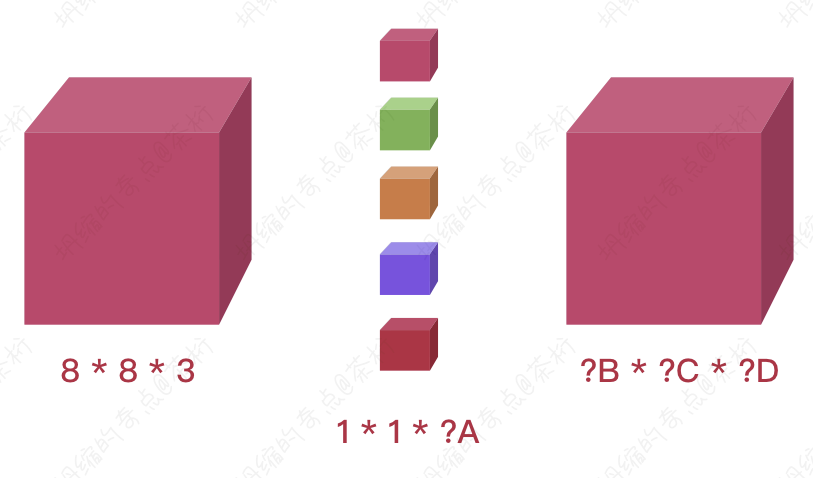
如图,也就是说,如果 A 为 5, 那么 B、C、D
应该等于多少?分别应该是8 * 8 * 5。
所以它其实起到了什么作用?首先我们知道了第一个功能就是改变通道数。
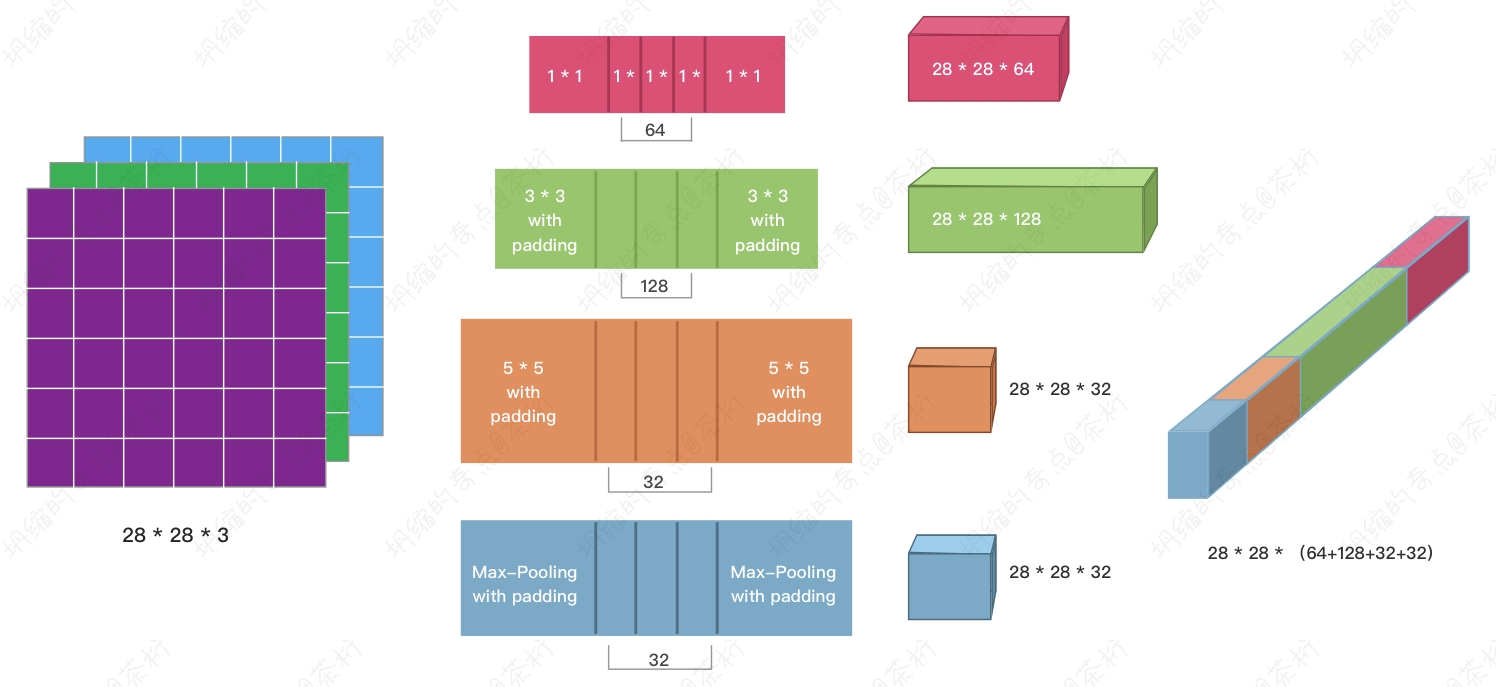
改变了通道数之后,如果是28 * 28 * 3,这个 Inception
的机制是对每一层的输入要用多个不同的 kernel size
的卷积做操作,做完之后把这些值拼起来,把它再作为下一层的输出。
这个时候 padding
就很有用了,保证了值都是28 * 28,就可以连起来了,否则还要做各种
reshap 就很麻烦。
Inception 第一个操作是它有一个 1 * 1,什么都没干但它改变了通道数,第二个就是它使用了多个 kernel size 给一层做卷积,之后把它的结果全部连起来。
那么把所有连起来它会产生这样一个结果
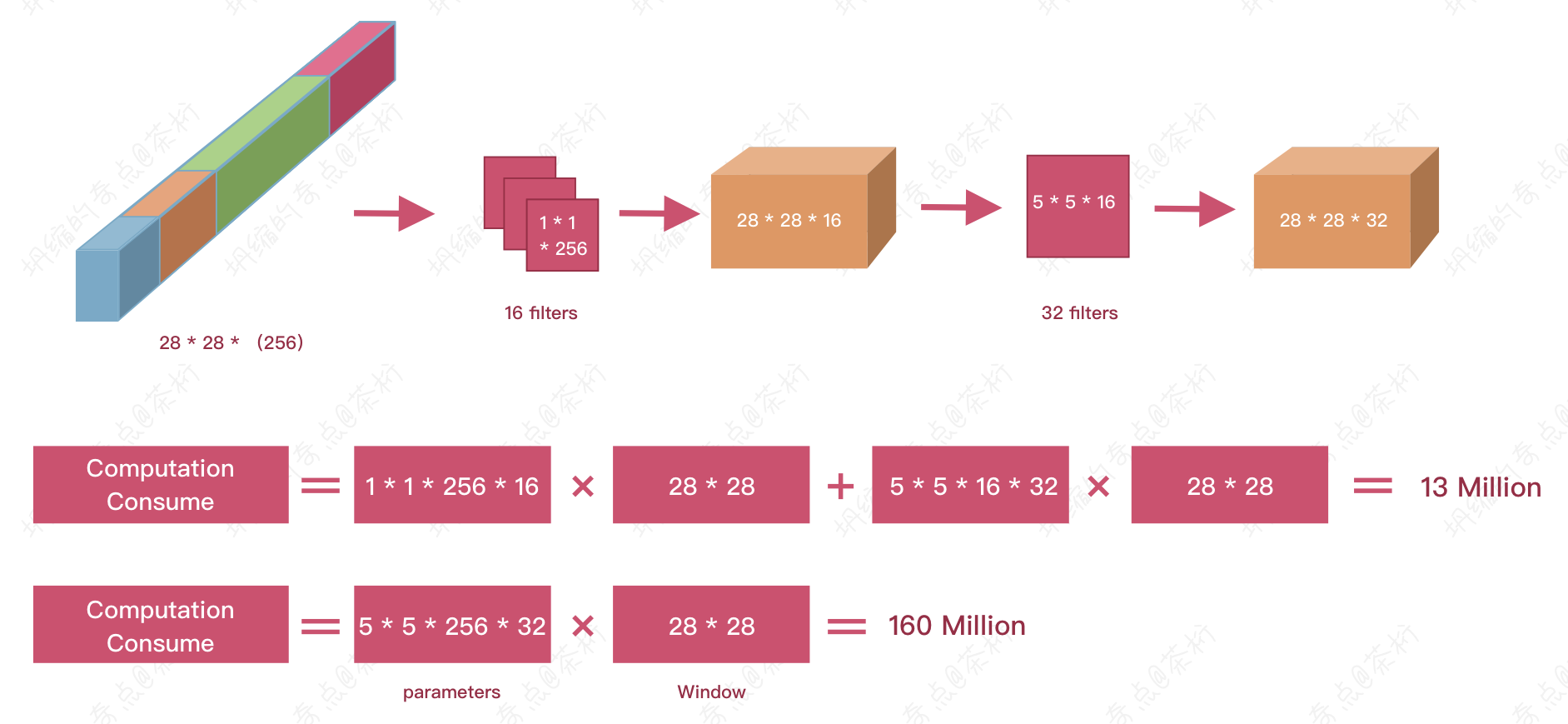
刚刚说了,inception 里面会把多个 kernel size
出来的结果连起来,因为有很多个 Kernel
size,这个结果就很长,我们希望把它变短,就可以用1 * 1的这个操作给它变短。
用了 16 个1 * 1的操作,就可以把这个 256 层的 channel
变成 16 层的 channel,变成 16
层之后再用5 * 5的卷积核去,得到了一个28 * 28 * 32的
channel。
而如果直接用5 * 5再 patting
的话也可以得到一个28 * 28的
channel,但是这两个是有区别的。如果直接用,就是28 * 28个
channel,有 32 个。那么所需要拟合的参数就是 160 million。
参数之所以大是因为连在一起的值特别大,特别的深。现在如果想把它变浅的话参数就少了。这个地方叫做 Bottleneck Network, 称为瓶颈网络。就是将之前连在一起而特别长的这个 channel 给它变得特别短,然后在这个短的 channel 上再做计算,所消耗的参数算下来就只有 13 million。
所以1 * 1的操作其实就是因为有了 inception
这种机制,所以会产生出特别长的结果。如果现在要对特别长的这个结果进行卷积的话,会需要的参数特别的多,而我们可以通过1 * 1的操作把它变短,之后再进行卷积操作,它的权重就少多了。这个就是这个
inseption 机制。
所以 Inseption 还是一样的道理,减少了参数的量,减少了 parameters 的数量,又降低了模型的复杂度,降低了过拟合,加快了计算速度。
那么我们卷积神经网络基本上到这里就给大家讲完了。关于更多卷积神经的应用后面会讲到专门的 CV 方面。
在这之前,接下来会用几节课分别讲解一下 CV、BI 和 NLP 的一些基础,给大家热热场子。
31. 深度学习进阶 - 全连接层及网络结构

