Machine Learning Part-01
Linear Regression Example
Implement Linear Regression for Boston House Price Problem
1
2
3
4
5
6
7
8
9import random
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.datasets import load_boston
from matplotlib.animation import FuncAnimation
import re
Part-01: Linear Regression
1 | |
decision boundary
Linear Regression: Regression is implemented, including the definition of linear functions, why use linear functions, the meaning of loss, the meaning of gradient descent, stochastic gradient descent Use Boston house price dataset. The data set of Beijing housing prices in 2020, why didn’t I use the data set of Beijing housing prices? Boston: room size, subway, highway, crime rate have a more obvious relationship, so it is easier to observe the relationship Beijing's housing prices:! Far and near! Room Condition ==》 School District! ! ! ! => Very expensive Haidian District
1 | |
Logstic Regression
Linear Regression: Regression is implemented, including the definition of linear functions, why use linear functions, the meaning of loss, the meaning of gradient descent, stochastic gradient descent Use Boston house price dataset. The data set of Beijing housing prices in 2020, why didn’t I use the data set of Beijing housing prices? Boston: room size, subway, highway, crime rate have a more obvious relationship, so it is easier to observe the relationship Beijing's housing prices:! Far and near! Room Condition ==》 School District! ! ! ! => Very expensive Haidian District Harder than deep learning:
1. compiler
2. programming language & automata
3. computer graphic
4. complexity system
5. computing complexity
6. operating system1 | |
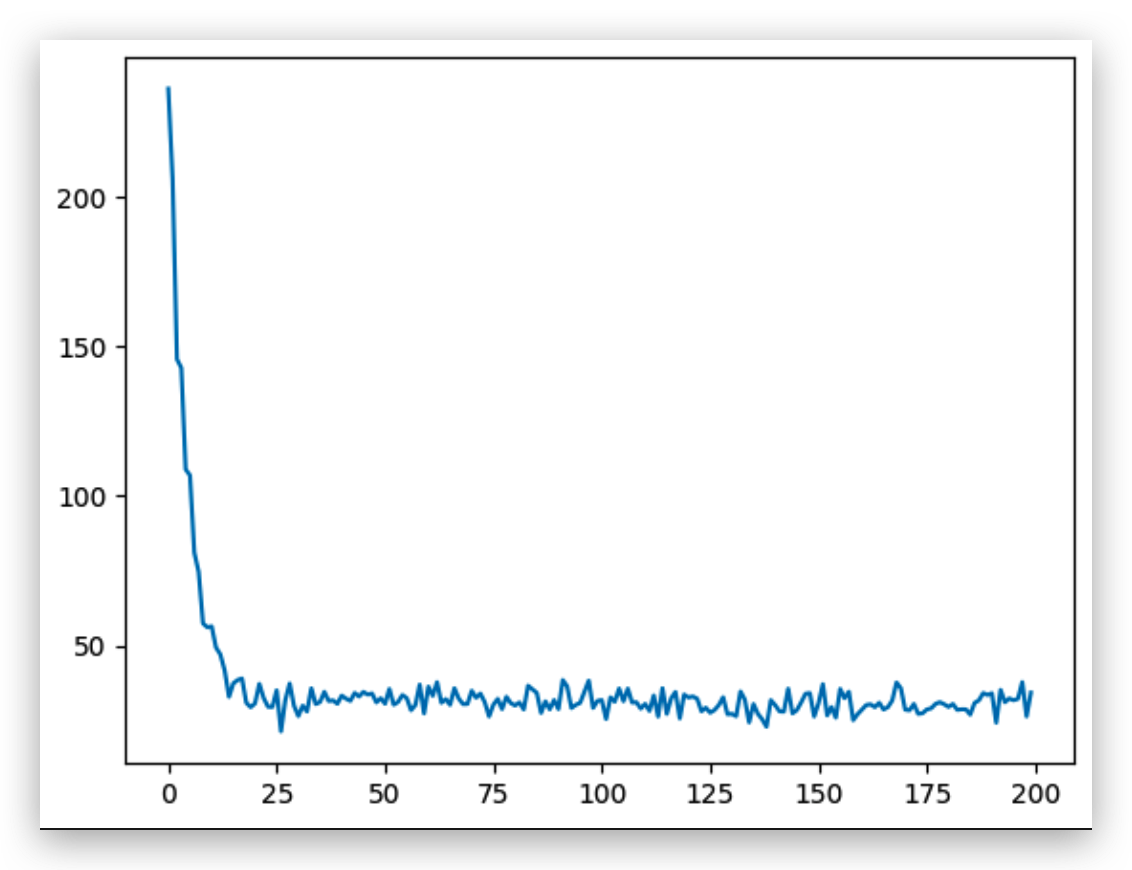
One thing left is to check the accuracy of our model! !
How to measure the quality of the model: 1. accuracy
precision
recall
f1, f2 score
AUC-ROC curve
Introduce a very very important concept: -> over-fitting and under-fitting (over-fitting and under-fitting) The entire machine learning process is constantly adjusting over-fitting and under-fitting!
Machine Learning Part-01

