不公平的预测:机器学习中的 5 种常见偏见来源
历史偏见、代理变量、不平衡数据集、算法选择和用户反馈循环如何导致不公平的模型
「AI秘籍」系列课程:

从表面上看,机器学习似乎是公正的。算法没有种族、民族、性别或宗教等敏感特征的概念。因此,它们不可能对某些群体做出有偏见的决定。然而,如果不加以控制,它们就会这样做。要纠正有偏见的决策,我们首先需要了解偏见来自何处。
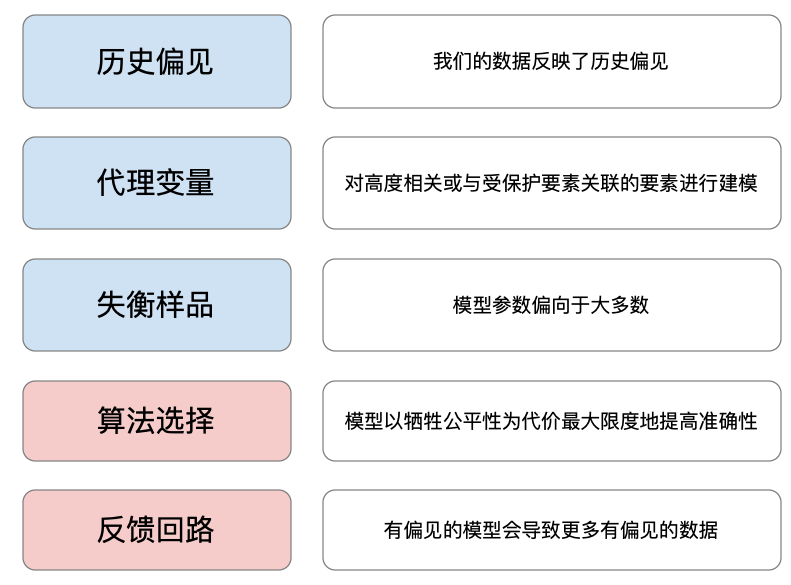
我们将讨论图 1 中给出的 5 个不公平原因。前三个原因涉及用于训练模型的数据。后两个原因涉及算法选择以及用户如何与模型交互。
之前写了一篇实际的教程《分析机器学习中的公平性》,如果您想要更实际的教程,请参阅这篇文章。它包含一项探索性分析,旨在量化我们在本文中讨论的一些原因。
进行探索性公平性分析,并利用平等机会、均等几率和不同的因素来衡量公平性……
偏见与公平
首先,让我们澄清一下偏见的含义。这是一个令人困惑的术语,在许多领域用于指代一系列问题。在机器学习中,偏见是模型开发过程中出现的任何系统性错误。这些错误可能是由于错误的假设或代码错误造成的。它们可能是在数据收集、特征工程或训练过程中引入的。甚至你部署模型的方式也可能导致偏见。
偏差 — 任何系统性错误
在日常生活中,偏见也有不同的定义。偏见是基于一个人或一个群体的特征而对其产生的偏见。同样,公平是对个人或群体没有任何偏见。
偏见(外行人)——对某个人或某个群体的偏见
在算法公平性方面,偏见还有另一种定义。它实际上是上述两者的结合。偏见是导致模型对某个人或某个群体产生偏见的任何错误。我们也可以把这种偏见称为不公平。
偏见(算法公平性)——导致模型不公平的系统性错误
接下来,我们将讨论不公平的根源与机器学习中更普遍的偏见形式之间的关系。这些包括测量偏见、表征偏见和聚合偏见。
不公平的根源
基于上述情况,似乎所有模型都是不公平的。机器学习的重点不就是根据群体特征进行区分吗?
定义“特征”的含义非常重要。在分析公平性时,这些是敏感特征,例如种族、民族、原籍国、性别或宗教。在数据集中,我们称这些为受保护变量。有 5 个主要原因导致模型对受保护变量中包含的群体不公平。
原因 1:历史偏见
过去,某些群体受到歧视。这种情况可能是故意通过法律发生的,也可能是无意中通过无意识的偏见发生的。无论出于何种原因,这种历史偏见都可以反映在我们的数据中。模型旨在拟合数据。这意味着数据中的任何历史偏见都可以反映在模型本身中。
历史偏见可以以不同的方式表现出来。少数群体的数据可能更容易丢失或记录错误。目标变量可能反映不公平的决策。当目标变量基于主观的人为决策时,这种情况更有可能发生。
有一个例子来自亚马逊开发的一个用于帮助实现招聘自动化的模型。历史申请人的简历被用来训练他们的模型。目标变量基于接受或拒绝工作申请的决定。

问题在于,由于招聘人员的偏见,大多数成功的申请者都是男性。女性被拒绝是因为她们的性别,而不是她们的资格。这种偏见最终反映在目标变量中。该模型学会了将女性简历的特征与不成功的候选人联系起来。它甚至惩罚了“女性”这个词(例如女子足球队队长)。
测量偏差
数据中的历史偏差与测量偏差的概念有关。在机器学习中,我们需要定义特征或标签。它们充当其他更复杂或不可测量构造的代理。首先,当代理无法很好地替代构造时,就会出现测量偏差。如果代理不是在不同组中统一创建的,也会发生这种情况。
对于招聘模型来说,历史决策就是标签。它充当着候选人能力的代理。问题是这些决策并不是统一的。男性和女性候选人受到的待遇不同。换句话说,不同群体的代理并不统一。在这种情况下,历史偏见导致了测量偏差。
原因 2:代理变量
我们上面提到了受保护变量。这些是代表种族或性别等敏感特征的模型特征。使用这些特征可能会导致不公平的模型。通常,正常特征可以与受保护特征相关或关联。我们称这些为代理变量。使用代理变量的模型可以有效地使用受保护变量来做出决策。
代理变量——与受保护特征关联的模型特征
例如,在南非,你居住的地方可以很好地预测你的种族。这是由于该国种族隔离的历史。你可以在图 2 中看到我们的意思。开普敦市仍然按种族划分。这意味着在模型中使用某人的邮政编码可能会导致种族歧视。
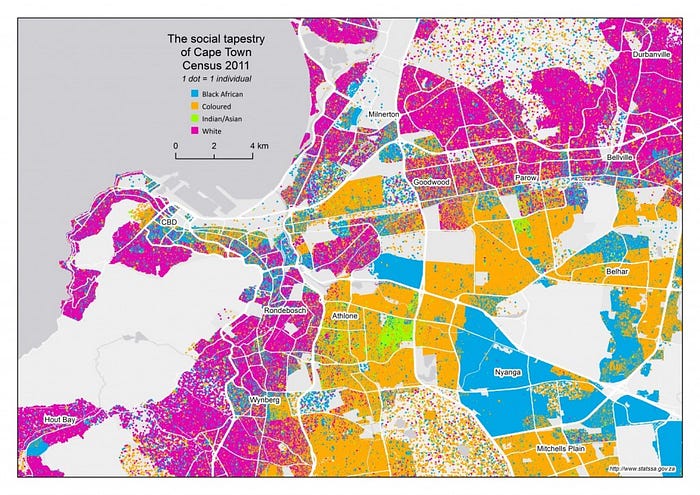
在理解代理变量时,关联和因果之间的区别很重要。假设我们正在建立一个模型来预测客户是否会拖欠贷款。一个理性的人会同意,一个人的种族不会导致他们的风险发生变化。事实上,改变他们风险的甚至不是他们的位置。而是他们的经济地位。然而,模型只关心关联。不幸的是,在南非,种族、位置和经济地位都是相关的。
原因 3:样本不均衡
假设我们计算一个人口的平均结婚年龄。我们得到的值为 33 岁。查看图 3,我们可以看到这个值并不代表人口的所有子群体。宗教群体的平均年龄 28 岁要低得多。由于非宗教群体的规模,平均值有所偏差。换句话说,人口平均值更接近非宗教群体的平均值。
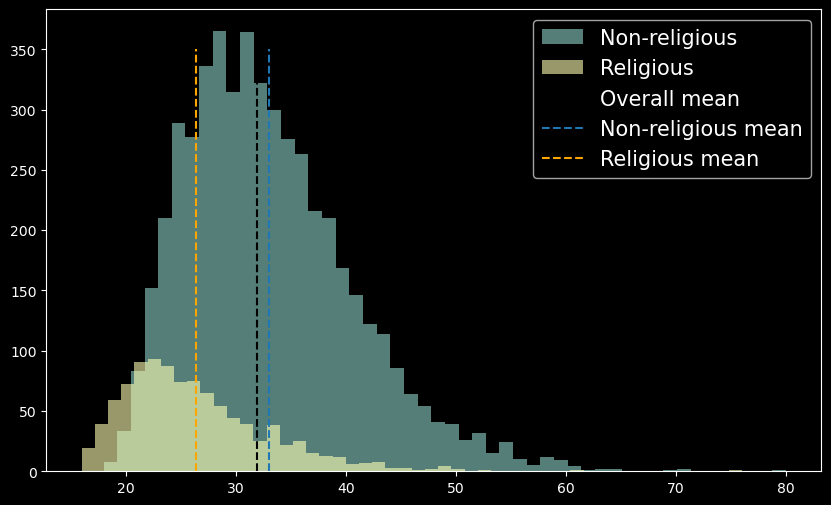
模型参数也可能以类似的方式出现偏差。模型试图捕捉整个训练群体的趋势。然而,在不同的子群体中,模型特征可能具有不同的趋势。如果一个群体占人口的大多数,则模型可能会偏向该群体内的趋势。因此,模型在少数群体中的表现可能会更差。
我们可以在图 4 中看到一个倾斜数据集的示例。ImageNet 是一个用于训练图像识别模型的大型数据集。我们可以将不同的国家视为子组。数据集中表示了出租车、餐馆和婚礼等概念。这些概念的外观在不同国家/地区可能有很大差异。问题是大多数图像来自北美和欧洲。
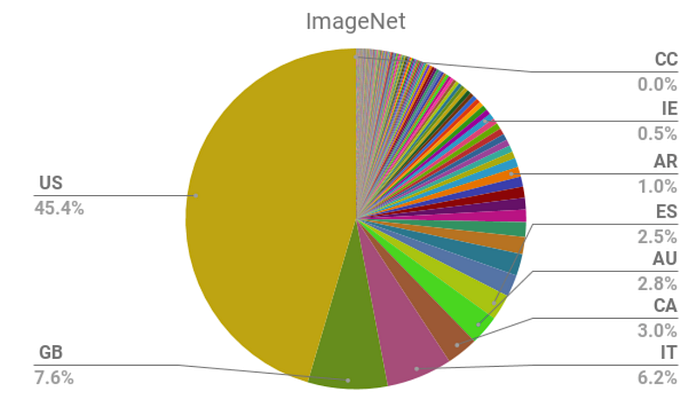
代表性偏见
这种不公平的根源与代表性偏见有关——当发展人群无法很好地推广到所有子群体时。与 ImageNet 一样,如果对某些子群体的关注较少,就会发生这种情况。一些数据集甚至可能反映出故意排除少数群体的决定。在这种情况下,发展人群不能很好地代表目标人群。
即使发展人口完全代表目标人口,问题仍然可能发生。根据定义,少数群体在总人口中所占比例较小。这意味着他们在发展人口中所占比例也会较小。这可能导致我们上面讨论的模型偏差问题。
原因 4:算法选择
前 3 个偏见来源都与数据问题有关。我们对所用算法的选择也会导致公平性问题。首先,一些算法的可解释性比其他算法低。这会使识别偏见来源和纠正偏见变得更加困难1。另一个主要因素是模型的目标。

以社交媒体推荐算法为例。它们只有一个任务 —— 让你留在平台上2。不幸的是,愤怒,尤其是对不属于你的群体的愤怒,可以有效地推动参与3。难怪仇恨和暴力内容在这些平台上如此盛行。
一般来说,模型是使用成本函数进行训练的。成本函数通常旨在最大化某种准确度。最大化准确度并不一定会导致不公平的决策。但是,除非我们调整成本函数以考虑公平性,否则我们无法保证公平的决策。
聚合偏差
成本函数还有另一个问题——它们旨在最大限度地提高整个开发群体的准确性。这可能会导致聚合偏差——整体表现良好,但其中一个子组的表现不佳。这类似于代表性偏差,只是现在我们谈论的是模型而不是数据。
在讨论人工智能对跨性别群体的负面影响时,我们已经看到了这样的例子。图 5 中对 4 个 AGR 系统进行的一项研究4表明,它们对跨性别女性的误判率平均为 12.7%,对跨性别男性的误判率平均为 29.5%。相比之下,对顺性别女性和男性的误判率分别为 1.7% 和 2.4%。
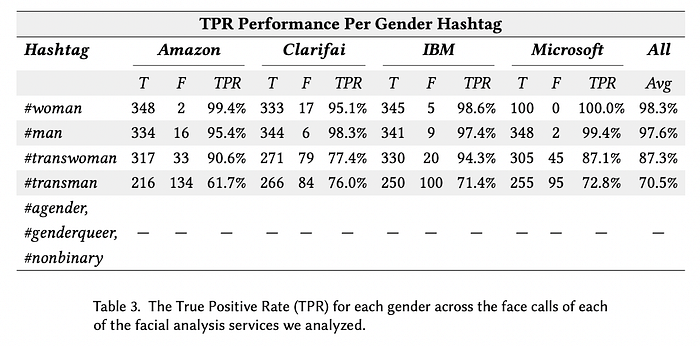
实际上,算法选择与我们之前提到的三个数据问题有关。数据集中的表示偏差可能导致模型中的聚合偏差。我们可以选择最大化有偏差的目标变量的准确性。算法还可以使用代理变量来最大化准确性。它并不关心这是否会导致不公平的决策。
原因 5:用户反馈循环
最后一个偏见来源与我们与模型的交互方式有关。模型一旦训练完成,就会被部署。随着用户与模型的交互,我们将收集更多数据来训练模型的未来版本。基础模型可能会导致数据出现偏差,从而导致未来模型出现进一步的偏差。
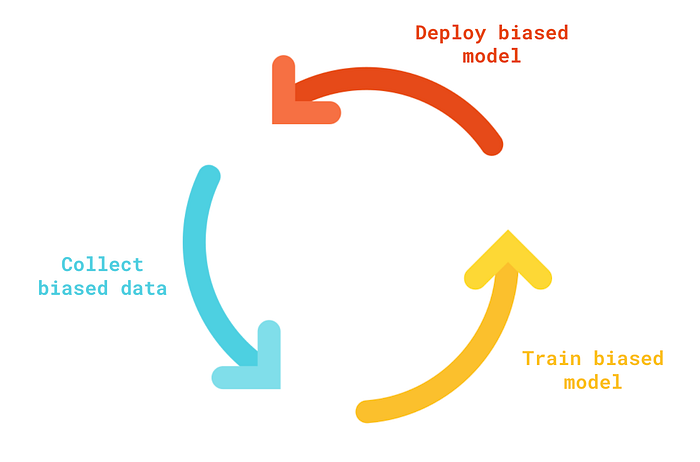
例如,假设我们开发了一个用于预测某人是否患有皮肤癌的模型。由于表征偏差,当人皮肤白皙时,该模型表现更好。可以理解的是,有色人种可能会避免使用我们的模型。因此,我们只会收集针对较白皮肤的诊断数据。这将放大表征偏差,并导致未来出现更多有偏差的模型。
因此,在部署模型之前,我们需要测量偏差,确定其来源并纠正它。在本文中,我们重点关注了偏差的来源。在之后,我会写一篇关于测量偏差的文章,用于《解决机器学习中的不公平现象》。
希望这篇文章对您有所帮助!您也可以选择购买进阶的文章用于学习更符合企业实战的技能,也能顺便支持我。
参考
Pessach, D. and Shmueli, E., (2020), Algorithmic fairness. https://arxiv.org/abs/2001.09784
Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K. and Galstyan, A., (2021), A survey on bias and fairness in machine learning. https://arxiv.org/abs/1908.09635
Chouldechova, A. and Roth, A., (2018), The frontiers of fairness in machine learning https://arxiv.org/abs/1810.08810
Wickramasinghe, S. (2021), Bias & Variance in Machine Learning https://www.bmc.com/blogs/bias-variance-machine-learning
Suresh, H. and Guttag, J., (2021), A framework for understanding sources of harm throughout the machine learning life cycle https://arxiv.org/abs/1901.10002
The Guardian, Amazon ditched AI recruiting tool that favored men for technical jobs (2018), https://www.theguardian.com/technology/2018/oct/10/amazon-hiring-ai-gender-bias-recruiting-engine
Rathje, S., Van Bavel, J.J. and Van Der Linden, S., 2021. Out-group animosity drives engagement on social media. Proceedings of the National Academy of Sciences, 118(26), p.e2024292118. https://www.pnas.org/doi/abs/10.1073/pnas.2024292118
Scheuerman, M.K., Paul, J.M. and Brubaker, J.R., 2019. How computers see gender: An evaluation of gender classification in commercial facial analysis services. Proceedings of the ACM on Human-Computer Interaction, 3(CSCW), pp.1–33 https://docs.wixstatic.com/ugd/eb2cd9_963fbde2284f4a72b33ea2ad295fa6d3.pdf
不公平的预测:机器学习中的 5 种常见偏见来源

