什么是算法公平性?
旨在理解和防止机器学习中不公平现象的领域的介绍
「AI秘籍」系列课程:
可直接在橱窗里购买,或者到文末领取优惠后购买:
乍一看,不公平的机器学习模型这一概念似乎有些矛盾。机器没有种族、民族、性别或宗教观念,怎么会主动歧视某些群体呢?但算法却会歧视,如果不加以制止,它们将继续做出延续历史不公正的决策。这就是算法公平性领域的用武之地。
我们探索算法公平性领域及其目标。为了强调这一领域的重要性,我们讨论了不公平模型的例子及其后果。我们还简要介绍了不公平的原因、如何衡量以及如何防止不公平。最后,我们讨论了公平性和可解释性之间的联系。在此过程中,我们链接到了有关这些主题的更深入的文章。
什么是算法公平性?
在机器学习中,算法和模型这两个术语可以互换使用。确切地说,算法是数学函数,如线性回归、随机森林或神经网络。模型是经过数据训练的算法。经过训练后,模型可用于进行预测,从而帮助实现决策自动化。这些决策可能包括从诊断癌症患者到接受抵押贷款申请等任何事情。
没有一个模型是完美的,这意味着它们可能会做出错误的预测。如果这些错误系统性地使一群人处于不利地位,我们就说这个模型是有偏见/不公平的。例如,一个不公平的模型可能会拒绝女性的抵押贷款申请,而不是男性。同样,我们最终可能会得到一个医疗系统,它不太可能为黑人患者检测出皮肤癌,而不是白人患者。
算法公平性是旨在理解和纠正此类偏见的研究领域。它处于机器学习和伦理学的交叉点。具体来说,该领域包括:
- 研究数据和算法偏见的原因
- 定义和应用公平衡量标准
- 开发旨在创建公平算法的数据收集和建模方法
- 向政府/企业提供如何规范机器学习的建议
理解公平的方法不仅仅是量化的,这一点也很重要。这是因为不公平的原因不仅限于数据和算法。研究还将涉及理解和解决不公平的根本原因。

为什么算法公平性很重要?
如上所述,机器学习模型被用于做出重要决策。错误预测的后果可能对个人造成毁灭性的影响。如果错误预测是系统性的,那么整个群体都可能受到影响。要理解我们的意思,回顾几个例子会有所帮助。
苹果最近推出了一张信用卡——Apple Card。您可以在线申请该卡,并自动获得信用额度。随着人们开始使用该产品,我们发现女性获得的信用额度明显低于男性。即使女性的财务状况(和信用风险)相似,情况也是如此。例如,苹果联合创始人史蒂夫·沃兹尼亚克 (Steve Wozniak) 表示,他获得的信用额度是妻子的 10 倍。

另一个例子是亚马逊用来帮助实现招聘自动化的系统。机器学习被用来对新候选人的简历进行评级。为了训练模型,亚马逊使用了历史上成功候选人的信息。问题是,由于科技行业男性占主导地位,这些候选人大多是男性。结果就是模型没有以性别中立的方式对简历进行评级。它甚至对“女性”一词进行了惩罚(例如女子足球队队长)。
这些例子表明,模型可以做出基于性别歧视的预测。与男性平等的女性面临着截然不同的结果。在这种情况下,后果是信用额度降低或工作申请被拒绝。这两种结果都可能产生严重的财务影响。总的来说,这样的模型会加剧男女之间的经济不平等。

模型还可能基于种族进行歧视。COMPAS 是美国刑事司法系统用来预测被告是否有可能再次犯罪的算法。错误的预测(即假阳性)可能导致被告被错误监禁或面临更长的监禁刑期。研究发现,黑人罪犯的假阳性率是白人罪犯的两倍。也就是说,黑人罪犯被错误地标记为潜在再犯罪者的可能性是白人罪犯的两倍。
这些例子表明,我们可以发现许多行业都在使用有偏见的算法来解决不同的问题。这些算法做出决策的规模也令人担忧。有偏见的人能够承销的贷款数量或能够定罪的人数是有限的。算法可以扩展并用于做出所有决策。最终,有偏见的算法的后果可能是负面的,也可能是广泛的。
不公平的原因
显然,这些算法很糟糕,但我们怎么会得到不公平的算法呢?算法公平性实际上是一个有点误导性的术语。算法本身并不是天生就有偏见的。它们只是数学函数。通过在数据上训练这些算法之一,我们得到了一个机器学习模型。引入有偏见的数据会导致模型有偏见。话虽如此,我们对算法的选择仍然会放大这些偏见。
数据可能因各种原因而产生偏差。我们收集的数据将反映历史不公正,而这些不公正可以通过模型捕捉到(历史偏差)。与亚马逊的招聘模式一样,这可能是由于少数族裔代表性不足(数据集不平衡)。也可能是由于与种族/性别相关的模型特征(代理变量)。我们将在《不公平的预测:机器学习中的 5 种常见偏见来源》中更深入地探讨这些原因。
常见的偏见来源——历史偏见、代理变量、不平衡数据集、算法选择和用户交互
分析和衡量不公平现象
算法公平性研究的很多目的是开发分析和衡量不公平性的方法。这可能涉及分析数据以找出上述不公平性的潜在原因。它还涉及衡量模型预测中的不公平性。
公平的定义
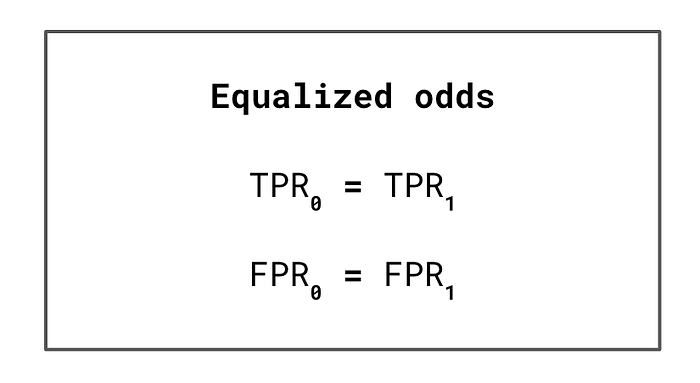
我们可以通过应用不同的公平定义来衡量预测的公平性。大多数定义都涉及将人群分为特权群体(例如男性)和非特权群体(例如女性)。然后,我们使用评估指标比较这些群体。例如,在均等几率定义下,我们要求两组的真阳性率和假阳性率相等。具有显著不同比率的模型被认为是不公平的。其他定义包括平等机会和不同影响。
探索性公平性分析
评估公平性并不是在您拥有最终模型时开始的。它也应该是您探索性分析的一部分。一般来说,我们这样做是为了围绕我们的数据集建立一些直觉。因此,在建模时,您会对预期的结果有一个很好的了解。具体来说,为了公平起见,您需要了解数据的哪些方面可能导致不公平的模型。
在文章《分析机器学习的公平性》中,我们将引导您了解如何进行这种探索性公平性分析。我们还将更深入地讨论公平性的定义并向您展示如何应用它们。
进行探索性公平性分析,并利用平等机会、均等几率和不同的因素来衡量公平性……
纠正和防止不公平现象
如果我们发现我们的模型不公平,我们自然会想要纠正它。已经开发了各种量化方法。我们可以将它们分为预处理、处理中和处理后。这取决于它们在模型开发的哪个阶段应用。例如,我们可以调整回归模型的成本函数以考虑公平性。这将被视为一种处理中方法。
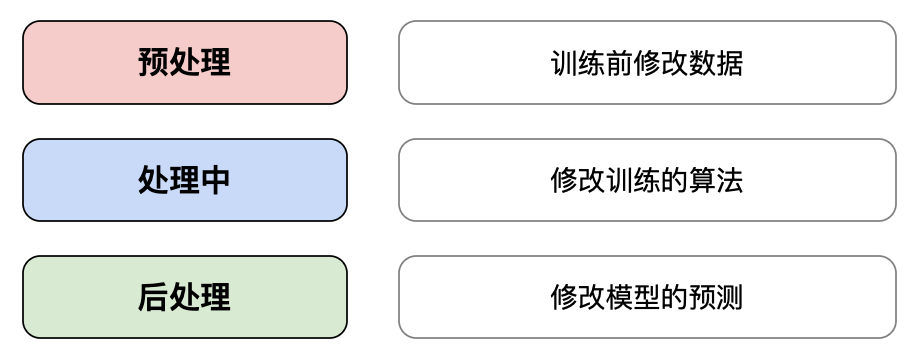
定量方法有其局限性。这是因为公平是一个复杂的问题。我们需要将其视为超越数据和模型的东西。最终,我们还需要非定量方法来全面解决不公平问题。这些方法包括解决根本原因、意识到问题和团队多样性。
我们将在《纠正和防止机器学习中的不公平现象》中讨论更多定量和非定量方法。这些方法包括预处理、处理中和后处理方法的示例。我们还尝试更深入地了解这些方法的局限性。
预处理、处理中和处理后定量方法。以及非定量方法……
可解释性和公平性
我喜欢写关于算法公平性的文章,很大一部分文章都是关于可解释的机器学习的。可解释性涉及理解模型如何进行预测。公平性和可解释性实际上是相关的。主要原因是它们都是为了建立对 ML 系统的信任。我们将在文章《可解释性与公平性的关系》1中讨论这一点和其他两个原因。
希望这篇文章对您有所帮助!除了我的公众号上的免费文章,您还可尝试阅读一些收费文章,获得更多更深的内容。如果想要针对企业项目实战,可以购买我的系列视频教程《人工智能企业项目实战》
扫描下方二维码可获取优惠
参考
Birhane, A., (2021) Algorithmic injustice: a relational ethics approach. https://www.sciencedirect.com/science/article/pii/S2666389921000155
D. Pessach & E. Shmueli, Algorithmic Fairness (2020), https://arxiv.org/abs/2001.09784
Gal Yona, A Gentle Introduction to the Discussion on Algorithmic Fairness (2017), https://towardsdatascience.com/a-gentle-introduction-to-the-discussion-on-algorithmic-fairness-740bbb469b6
J, Vincent, Apple’s credit card is being investigated for discriminating against women (2019), https://www.theverge.com/2019/11/11/20958953/apple-credit-card-gender-discrimination-algorithms-black-box-investigation
S. Wachter-Boettcher, Technically Wrong: Sexist Apps, Biased Algorithms, and Other Threats of Toxic Tech (2017), https://www.goodreads.com/book/show/38212110-technically-wrong
The Guardian, Amazon ditched AI recruiting tool that favored men for technical jobs (2018), https://www.theguardian.com/technology/2018/oct/10/amazon-hiring-ai-gender-bias-recruiting-engine
Wikipedia, Algorithmic bias (2021), https://en.wikipedia.org/wiki/Algorithmic_bias
将在后面发表相关文章↩︎
什么是算法公平性?

