如何创建自己的人工智能书签搜索助手?
「基于 GPT 的书签自动搜索 pipeline 分步指南」
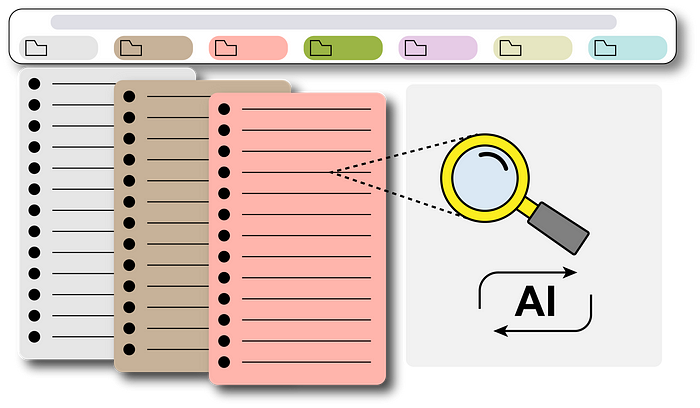
您是否遇到过这样的情况:在 Chrome 浏览器中搜索特定书签时,却发现书签数量太多,让您应接不暇?在大量书签中进行筛选变得相当枯燥乏味。

其实,我们可以把它交给 ChatGPT,它是目前最流行的人工智能模型,基本上可以回答我们提出的所有问题。试想一下,如果它能获取我们的书签,那就太好了!问题就解决了!然后,我们就可以要求它从整个书签存储中给出我们想要的特定链接,就像下面的 GIF 一样:
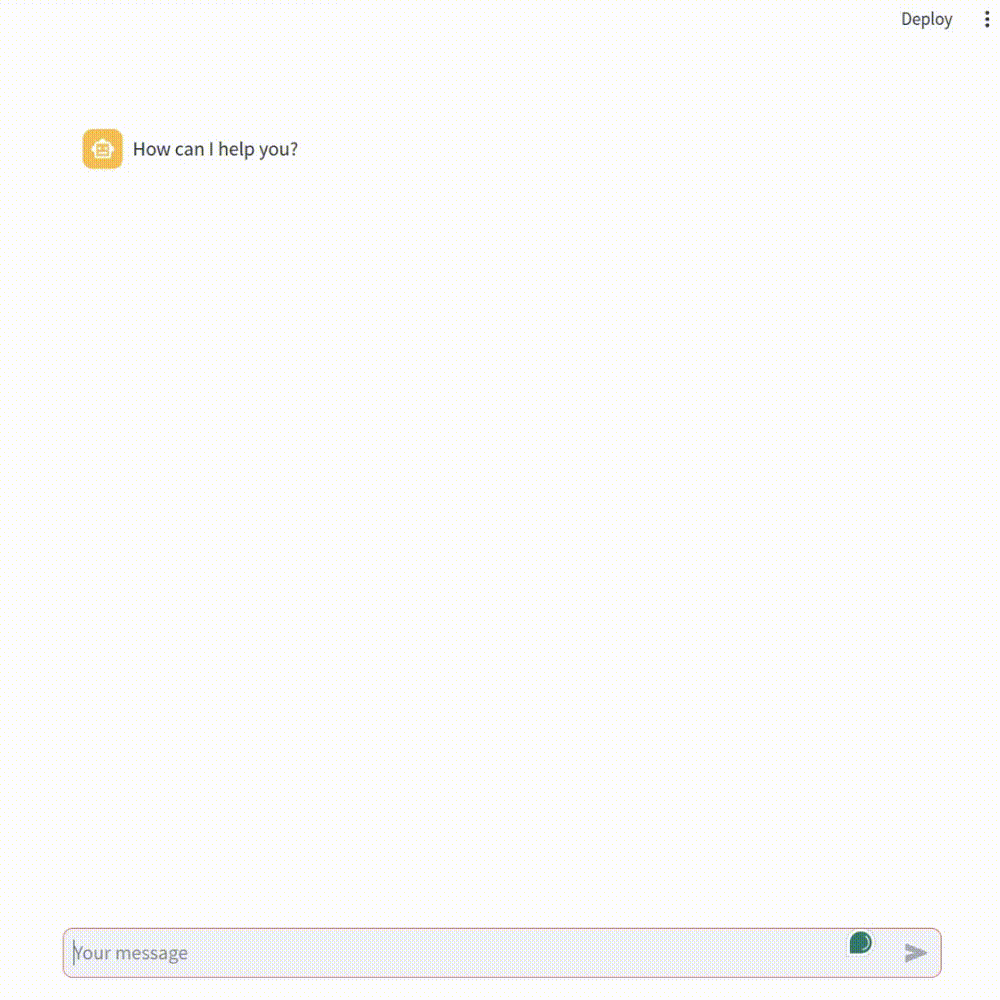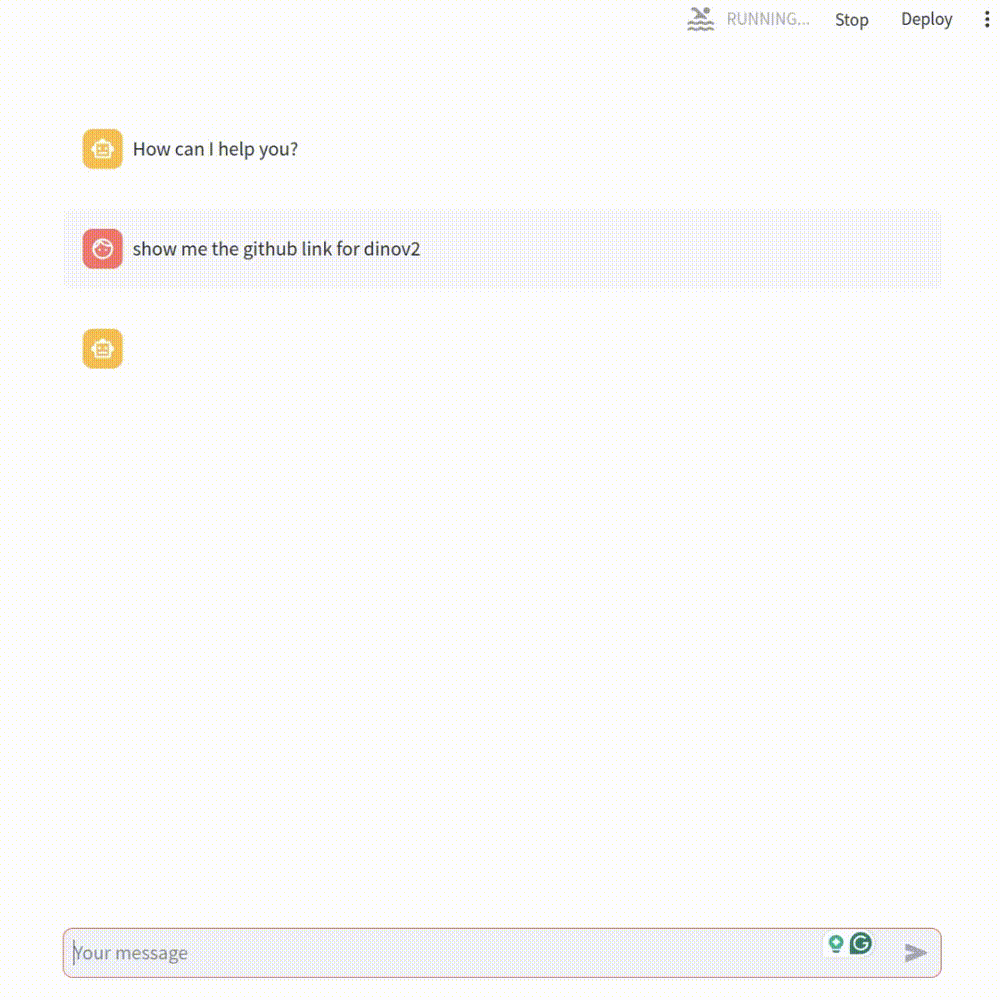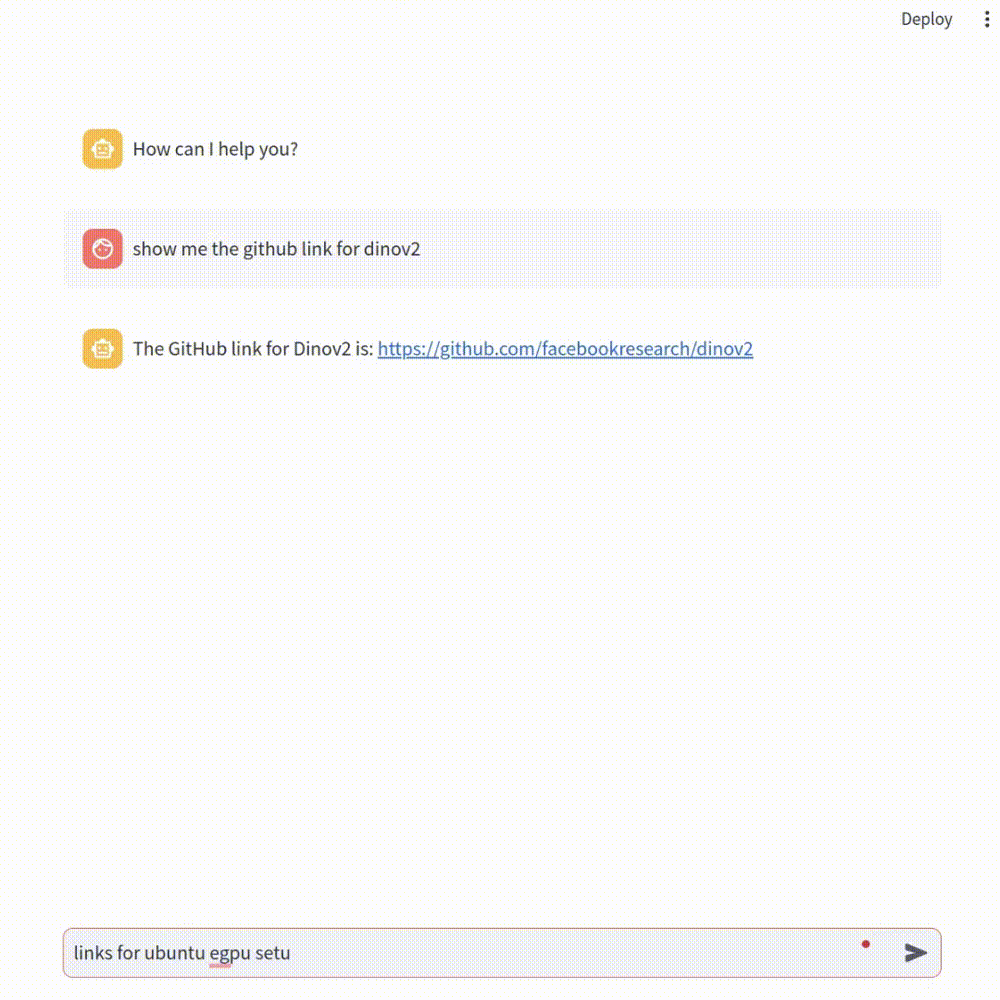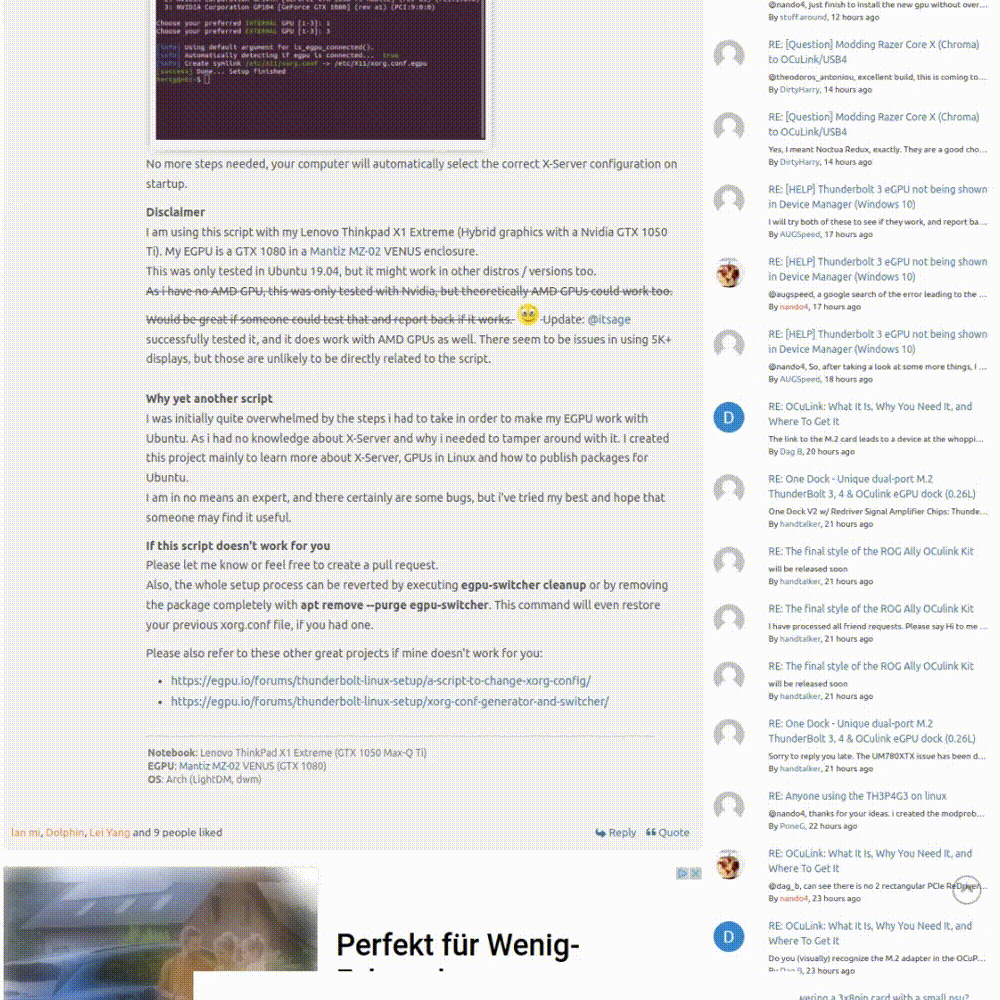
为此,我建立了一个 pipeline,将 Chrome 浏览器书签更新到矢量数据库中,ChatGPT 将使用该数据库作为我们提问的上下文。我将在本文中逐步解释如何构建这样一个 pipeline,最终你也会拥有自己的 pipeline !
特点
在开始之前,我们先来数数它的优点:
与传统搜索引擎(如 Chrome 浏览器书签管理器中的搜索引擎)不同,人工智能模型可以很好地理解每个标题的语义。如果你在搜索书签时忘记了准确的关键词,你只需画出一个大概的轮廓,ChatGPT 就能得到它!它甚至能理解不同语言的标题,是不是很厉害?
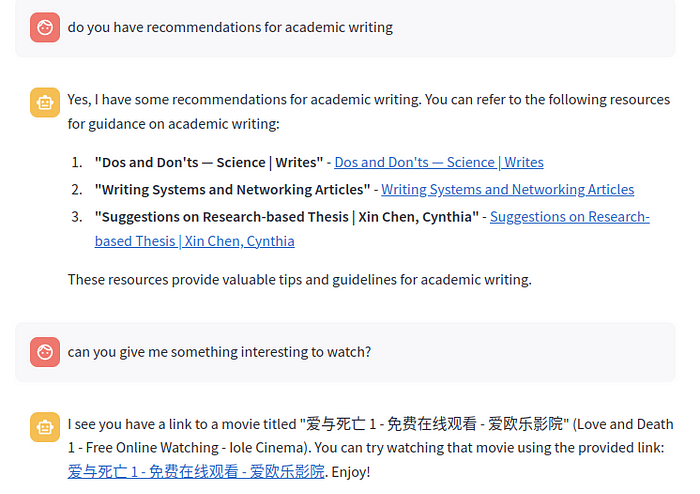
一切都会自动更新。每个新添加的书签都会在几分钟内自动反映到人工智能知识数据库中。
pipeline 概览
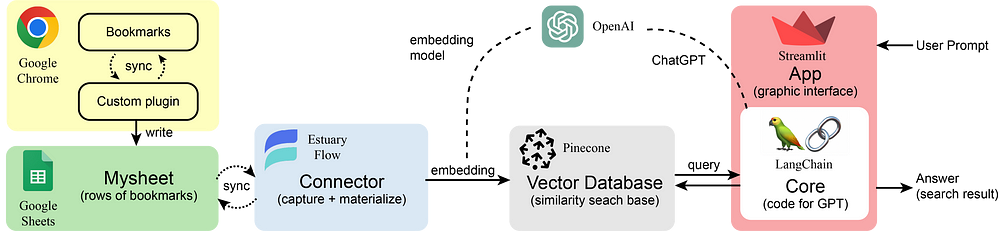
在这里,您可以看到每个组件在我们的流程中的作用。我们使用定制的 Chrome 浏览器插件将 Chrome 浏览器书签提取到谷歌工作表的行中。Estuary Flow 获取(或捕捉)所有工作表数据,然后通过使用 OpenAI API 的嵌入模型将其矢量化(或实体化)。所有嵌入(每个向量对应工作表的每一行,即每个书签)将被检索并存储到 Pinecone 向量数据库中。之后,用户可以使用 Streamlit 和 LangChain 向内置应用程序发出提示(例如,"有 dinov2 的链接吗?)它首先会从 Pinecone 中检索一些类似的嵌入(获取上下文/多个潜在书签选项),然后将它们与用户的问题结合起来,作为 ChatGPT 的输入。然后,ChatGPT 会考虑所有可能的书签,并给出最终答案。这个过程也被称为 RAG:检索增强生成(Retrieval Augmented Generation)。
在下文中,我们将逐步了解如何构建这样一个 pipeline。
用于书签检索的 Chrome 浏览器插件
Code: https://github.com/swsychen/Boomark2Sheet_Chromeplugin
要将书签传输到 Google Sheet 中进行进一步处理,我们需要先创建一个定制的 Chrome 浏览器插件(或扩展)。
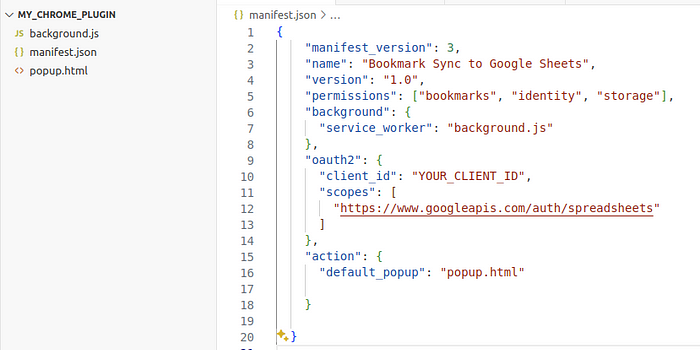
对于 Chrome 浏览器扩展来说,最重要的文件是 manifest.json,它定义了插件的高级结构和行为。在这里,我们添加了使用 Google Chrome 浏览器书签 API 和跟踪书签更改所需的权限。我们还为 oauth2 身份验证设置了一个字段,因为我们将使用 Google Sheet API。您需要在该字段中输入您自己的 client_id。你可以根据此链接(https://developers.google.com/sheets/api/quickstart/js)中的 "设置环境 "部分获取 client_id 和 Google Sheet API Key(我们稍后会用到)。需要注意的是
- 在 OAuth 同意页面,你需要添加自己(Gmail 地址)作为测试用户。否则,你将无法使用 API。
- 在创建 OAuth 客户端 ID 中,应选择的应用程序类型是 Chrome 浏览器扩展(而不是快速入门链接中的 Web 应用程序)。需要指定的项目 ID 是插件 ID(我们在加载插件时会有它,你可以在扩展管理器中找到它)。
核心功能文件是 background.js,它可以在后台完成所有同步。我已经在 GitHub 链接中为你准备好了代码,你唯一需要修改的就是 javascript 文件开头的电子表格 ID。这个 id 可以在创建的 Google Sheet 的共享链接中找到(在 d/ 之后、/edit 之前,没错,你需要先手动创建一个 Google Sheet!):
https://docs.google.com/spreadsheets/d/{spreadsheetId}/edit#gid=0
代码的主要逻辑是监测书签的任何变化,并在触发插件时(例如添加新书签时)用所有书签刷新(clear + write)工作表文件。它会将每个书签的 id、标题和 URL 写入指定 Google Sheet 的单独一行中。

最后一个文件 popup.html 基本上没什么用,因为它只定义了在 Chrome 浏览器中点击插件按钮时弹出窗口中显示的内容。
确保所有文件都在一个文件夹中后,就可以上传插件了:
- 进入 Chrome 浏览器的 "扩展">"管理扩展",打开页面右上方的 "开发者模式"。
- 点击 "加载已解压 "并选择代码文件夹。然后你的插件就会上传并运行。点击超链接服务工作者,查看代码打印的日志信息。
上传后,只要 Chrome 浏览器打开,插件就会一直运行。重新打开浏览器时,它也会自动开始运行。
设置Estuary Flow和Pinecone
Estuary Flow 基本上是一个连接器,可以将数据库与你提供的数据源同步。在我们的例子中,当 Estuary Flow 将谷歌工作表中的数据同步到矢量数据库 Pinecone 中时,它还会调用嵌入模型,将数据转换为嵌入矢量,然后存储到 Pinecone 数据库中。
关于 Estuary Flow 和 Pinecone 的设置,YouTube 上已经有一个相当全面的视频教程:https://youtu.be/qyUmVW88L_A?si=xZ-atgJortObxDi-。
但请注意因为 Estuary Flow 和 Pinecone 正在快速开发中。视频中的某些内容现在已经有所改变,可能会引起混淆。在此,我列出了视频中的一些更新,以便您可以轻松复制所有内容:
1.(Estuary Flow>create Capture)在行批量大小中,您可以根据 Google Sheet 中书签的总行数设置一些较大的数字。(例如,如果你已经有 400 多行书签,则可将其设置为 600 行)
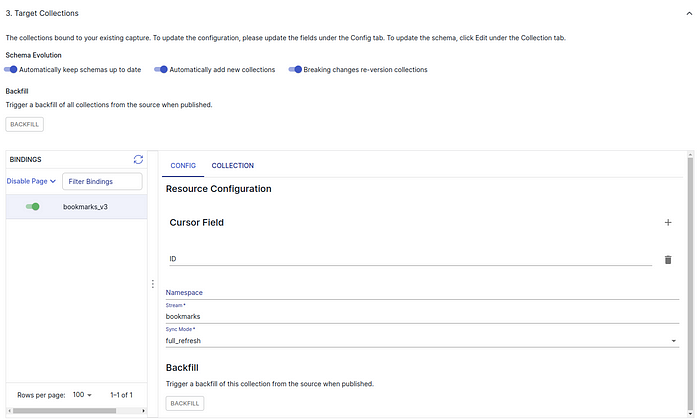
2.(Estuary Flow>create Capture)在设置目标收藏时,删除光标字段 "row_id "并添加新字段 "ID",如下截图所示。命名空间可以保持为空。
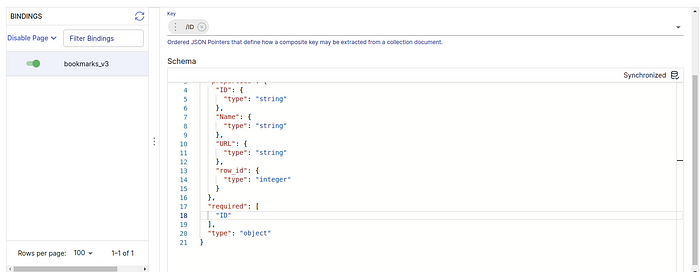
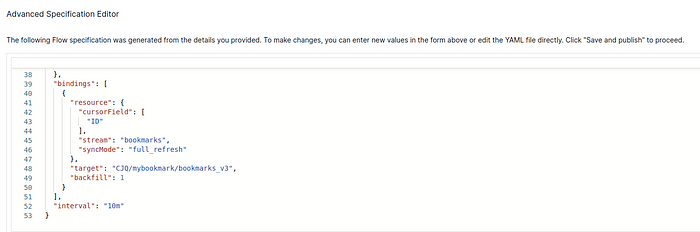
3.(Estuary Flow>create Capture)然后切换到 COLLECTION 子标签,按 EDIT 键将 Key 从 /row_id 改为 /ID。还应将模式代码中的 "必填 "字段改为 "ID",如下所示:
1 | |
SAVE AND PUBLISH "后,您可以看到 Collections>{your collection name}>Overview>Data Preview 将显示每个书签的正确 ID。
(Estuary Flow>create Capture)在最后一步,您可以看到高级规格编辑器(在页面底部)。在这里,您可以添加一个字段 "interval":10m "字段,将刷新率降至每 10 分钟一次(如果未指定,默认设置为每 5 分钟一次)。每次刷新都会调用 OpenAI 嵌入模型重做所有嵌入,这将花费一定的成本。降低刷新率可以节省一半的费用。您可以忽略 "backfill"字段。
1
2
3
4
5
6
7
8//...skipped
"syncMode": "full_refresh"
},
"target": "CJQ/mybookmark/bookmarks_v3"
}
],
"interval": "10m"
}5.(Estuary Flow>create Materialization)Pinecone 环境通常为 "gcp-starter",用于自由层的 Pinecone 索引,或者类似于 "us-east-1-aws",用于标准计划用户(我不在 Pinecone 中使用无服务器模式,因为 Estuary Flow 尚未为 Pinecone 无服务器模式提供连接器)。Pinecone 索引是在 Pinecone 中创建索引时的索引名称。
6.(Estuary Flow>create Materialization)下面是一些比较棘手的部分。
- 首先,应使用蓝色按钮 "SOURCE FROM CAPTURE"选择源捕获,然后将 "CONFIG"中的 Pinecone 命名空间留空(Pinecone 的免费层必须有一个空的命名空间)。
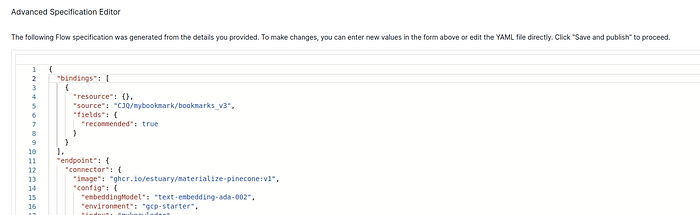
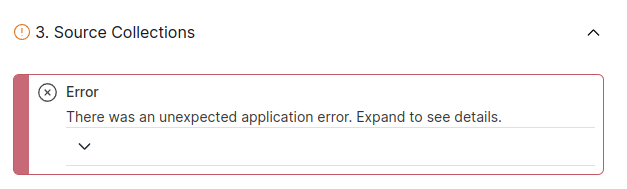
- 其次,按下 "NEXT "后,在出现的物化高级规范编辑器中,必须确保 "bindings"字段不是空的。如果是空的或字段不存在,请按下面的截图填写内容,否则不会向 Pinecone 发送任何内容。此外,你还需要使用自己的收藏路径(与上一张截图中的 "target"相同)更改 "source"字段。如果按下 "NEXT "键后,在看到编辑器之前出现了一些错误,请再按一次 "NEXT "键,然后就能看到高级规范编辑器了。然后就可以指定 "bindings",并按下 "SAVE AND PUBLISH"。完成这一步后,一切都应该没问题了。出现错误是因为我们之前没有指定 "bindings"。
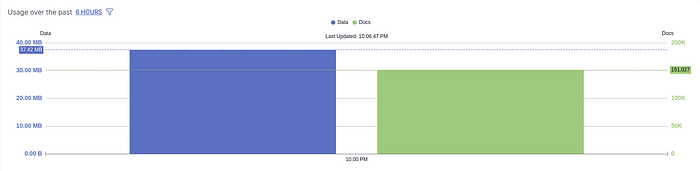
- 如果在发布所有内容并返回 "目的地 "页面后出现另一条错误信息,告诉你没有添加集合,只要你在概览直方图中看到使用量不为零(见下面的截图),就可以忽略它。直方图基本上表示向 Pinecone 发送了多少数据。
1 | |
7.(Pinecone>create index)Pinecone 推出了无服务器索引模式(免费,但 Estuary Flow 尚不支持),但我在本项目中没有使用它。在这里,我们仍然使用基于 pod 的选项(上次检查是在 2024 年 4 月 14 日,现在已不再免费),它足以满足我们的书签嵌入存储需求。创建索引时,只需设置索引名称和尺寸。
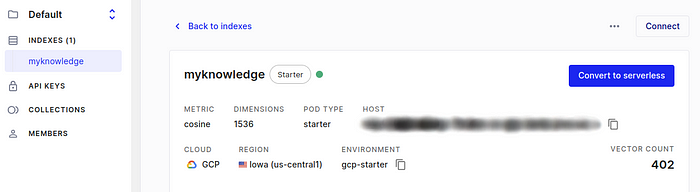
8.(Pinecone>Indexes>{Your index})完成 Pinecone 索引的创建,并确保在 Estuary Flow 的实体化中正确填写了索引名称和环境后,就大功告成了。在 Pincone 控制台中,转到 Indexes>{Your index},就能看到显示书签总数的矢量计数。可能需要几分钟时间,直到 Pinecone 收到 Estuary Flow 的信息并显示正确的矢量计数。
使用 Streamlit 和 Langchain 构建自己的应用程序
代码: https://github.com/swsychen/BookmarkAI_App
我们就快成功了!最后一步是创建一个漂亮的界面,就像最初的 ChatGPT 一样。在这里,我们使用了一个名为 Streamlit 的非常方便的框架,只需几行代码就能创建一个应用程序。Langchain 也是一个用户友好型框架,可以用最少的代码使用任何大型语言模型。
我还为你准备了本应用程序的代码。请按照 GitHub 链接中的安装和使用指南操作,尽情享受吧!
代码的主要逻辑如下
获取用户提示 → 使用 ChatGPT 和 Pinecone 创建一个检索链 → 向检索链输入提示并获取响应 → 将结果流式传输到用户界面

请注意,由于 Langchain 处于开发阶段,如果您使用的版本与 requirements.txt 中所述版本不同,代码可能会被弃用。如果您想深入研究 Langchain 并使用其他 LLM 进行书签搜索,请随时查阅 Langchain 的官方文档(https://python.langchain.com/docs/get_started/introduction/)。
如何创建自己的人工智能书签搜索助手?

