寻找并可视化交互
使用特征重要性、弗里德曼 H 统计量和 ICE 图分析相互作用
本文中的代码需要安装 R 语言包
「AI秘籍」系列课程:
药物的副作用可能取决于你的性别。吸入石棉会使吸烟者患肺癌的几率高于不吸烟者。如果你比较温和/自由,那么随着受教育程度的提高,你对气候变化的接受程度往往会提高。对于最保守的人来说,情况正好相反。这些都是数据交互的例子。识别和整合这些可以大大提高准确性并改变模型的解释。
在本文中,我们将探讨分析数据集中交互作用的不同方法。我们讨论如何使用散点图和 ICE 图来可视化它们。然后,我们讨论查找/突出显示潜在交互作用的方法。这些方法包括特征重要性和 Friedman 的 H 统计量。你可以在GitHub1上找到用于此分析的 R 代码。在开始之前,有必要准确解释一下交互作用的含义。
什么是交互?
当特征与目标变量有某种关系时,我们称该特征具有预测性。例如,汽车的价格可能会随着汽车的老化而下降。年龄(feature)可用于模型中以预测汽车价格(target variable)。在某些情况下,目标变量和特征之间的关系取决于另一个特征的值。这称为特征之间的相互作用。
以图 1 中的车龄与汽车价格的关系为例。这里我们有第二个特征 — 汽车类型。汽车可以是经典汽车(classic =1),也可以是普通汽车(classic =0)。对于普通汽车,价格会随着车龄的增加而下降,但对于经典汽车,车龄实际上会增加其价值。价格与车龄之间的关系取决于汽车类型。换句话说,车龄与汽车类型之间存在相互作用。
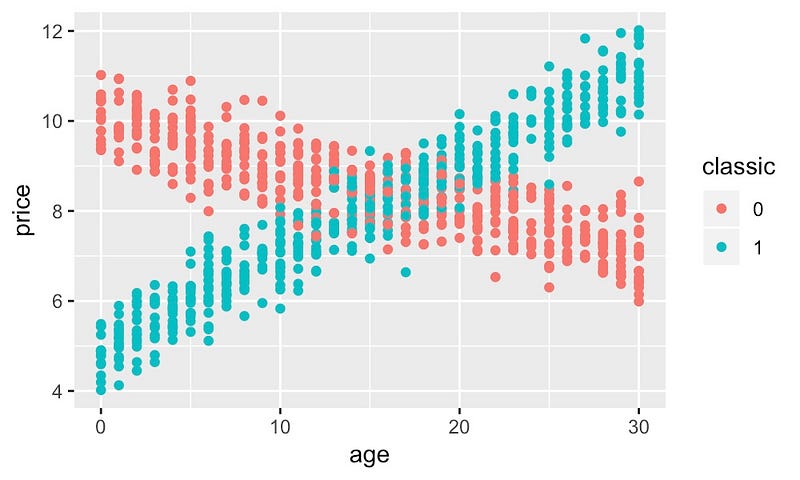
结合这些交互可以提高我们模型的准确性。非线性模型(如随机森林)可以自动对交互进行建模。我们可以简单地将年龄和汽车类型作为特征,模型就会将交互纳入其预测中。对于线性模型(如线性回归),我们必须添加显式交互项2。为此,我们首先需要知道我们的数据中存在哪些交互。
数据集
为了解释这些技术,我们随机生成了一个包含 1000
行的数据集。该数据集包括表 1 中列出的 5
个特征。这些特征用于预测员工的年终奖金。我们设计了数据集,因此经验和学位之间以及绩效和销售额之间存在相互作用。days_late
不与任何其他特征交互。
由于相关特征的性质,这两个交互作用是不同的。学位是分类的,而经验是连续的。因此,我们有一个分类特征和连续特征之间的交互作用。对于另一个交互作用,我们有两个连续特征。我们将看到,我们仍然以相同的方式分析这些交互作用。
可视化交互
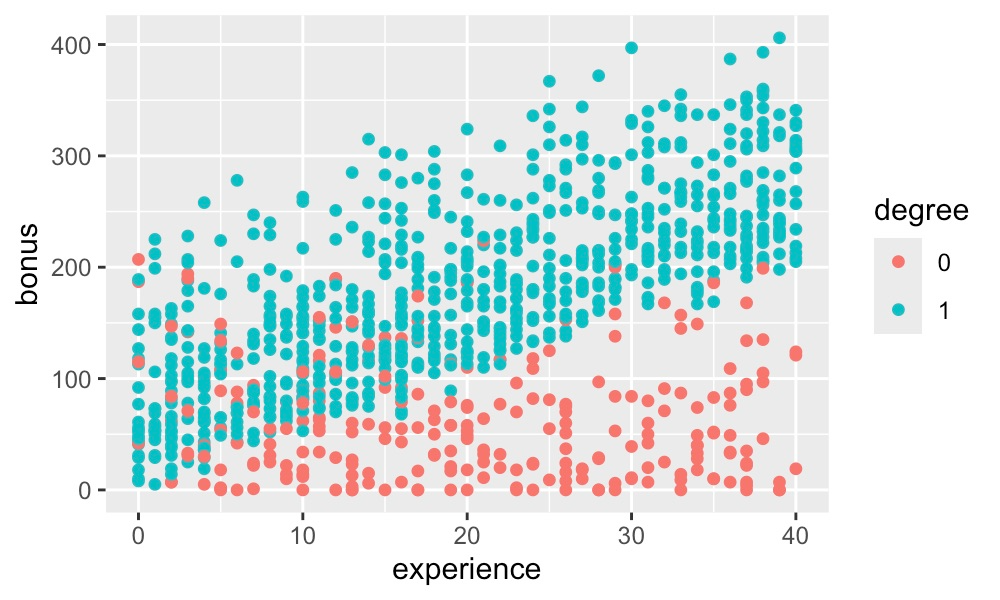
我们首先可以使用简单的散点图来可视化这些相互作用。在图 2 中,我们可以看到经验和学位之间的相互作用。如果员工有学位,他们的奖金往往会随着经验的增加而增加。相比之下,当员工没有学位时,这些特征之间就没有关系。如果这是一个真实的数据集,我们希望对此有一个直观的解释。例如,受过教育的员工可能会承担更看重经验的职位。
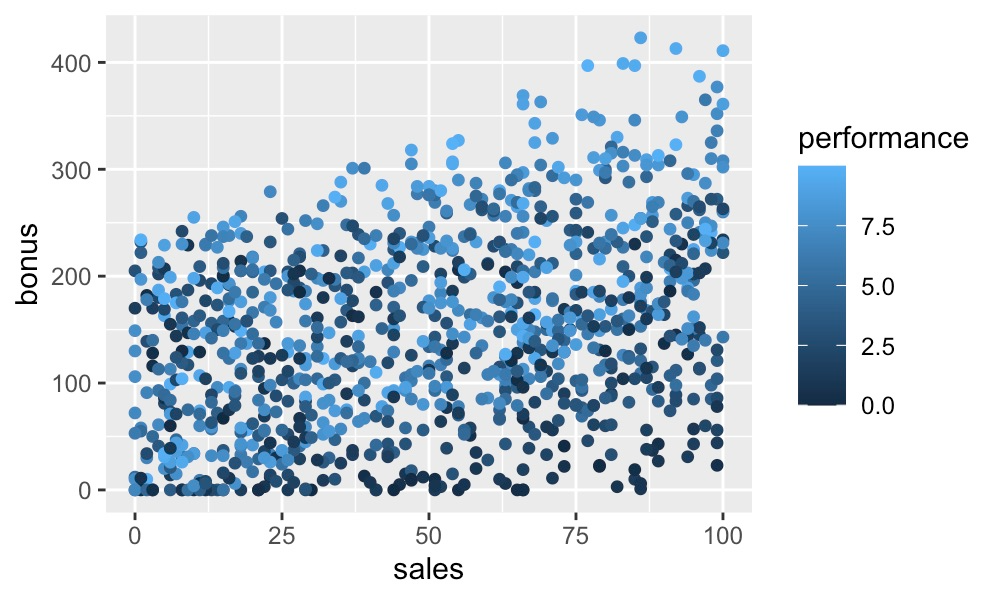
同样,我们可以在图 3 中看到销售额和绩效之间的相互作用。在这种情况下,可能不太清楚。我们现在有一个渐变配色方案,其中较暗的点表示较低的绩效评级。一般来说,奖金往往会随着销售额的增加而增加。仔细观察,你会发现较浅的点有更陡的斜率。对于更高的绩效评级,销售额的增加将带来更大的奖金增长。
以这种方式可视化交互作用可能很直观,但并不总是有效。我们正在可视化目标变量与仅两个特征之间的关系。实际上,目标变量可能与许多特征有关系。这和统计变化的存在意味着散点图点将分散在潜在趋势周围。我们已经可以在上面的图表中看到这一点,而在真实的数据集中,情况会更糟。最终,为了清楚地看到交互作用,我们需要剔除其他特征和统计变化的影响。
ICE 图
这将我们带到了个体条件期望 (ICE) 图。要创建 ICE 图,我们首先要将模型拟合到我们的数据中。在我们的例子中,我们使用了一个有 100 棵树的随机森林。在表 2 中,我们的数据集中有两行用于训练模型。在最后一列中,我们可以看到每个员工的预测奖金。这是随机森林根据特征值做出的预测。要创建 ICE 图,我们改变一个特征的值,同时保持其他特征不变,并绘制结果预测。

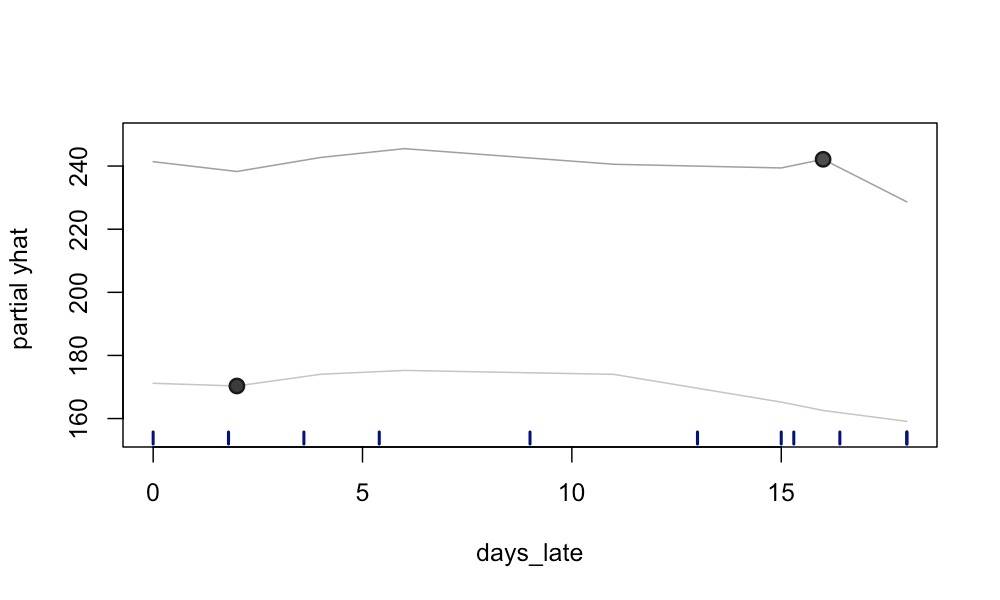
看看图 4,这可能更有意义。这里我们选取了表 2 中的两名员工。我们绘制了
days_late
每个可能值的预测奖金,同时保留了其他特征的原始值。(即,第一和第二名员工的经验将分别保持在
31 年和 35 年)。两个黑点对应于表 2 中的实际预测(即他们的真实
days_late 值)。
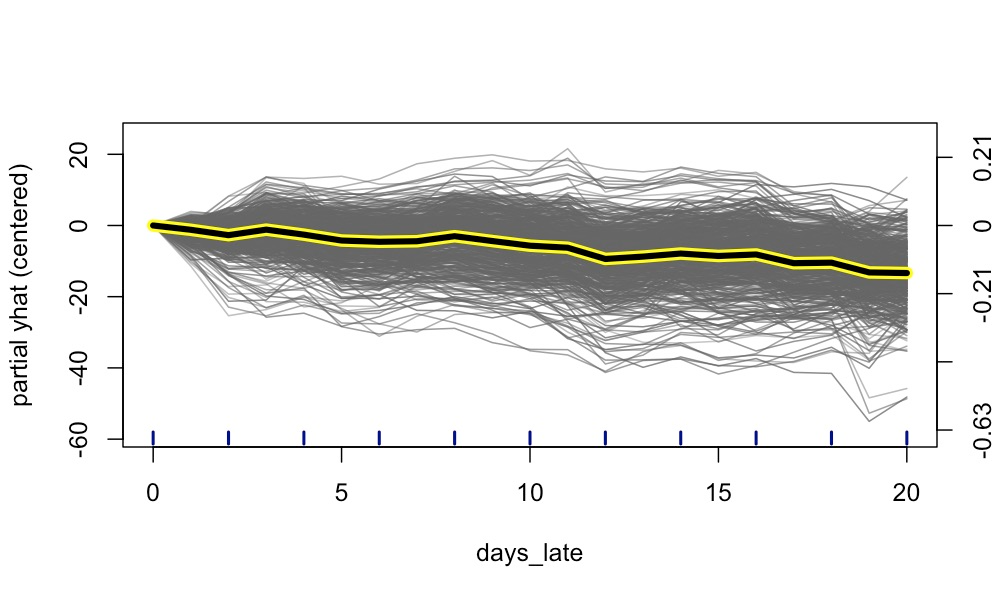
最后,为了获得 ICE
图,我们对数据集中的每一行都遵循此过程。我们还将每条线居中,使它们在 y
轴上从 0 开始。粗线给出了所谓的部分依赖图(PDP)3。这是每个 days_late
值的平均部分 yhat(居中)值。查看 PDP,随着
days_late
的增加,预测奖金趋于减少。我们还可以看到大多数单个预测都遵循这一趋势。如果
days_late
与另一个特征相互作用,我们就不会期望这一点。我们将有遵循不同趋势的预测组。
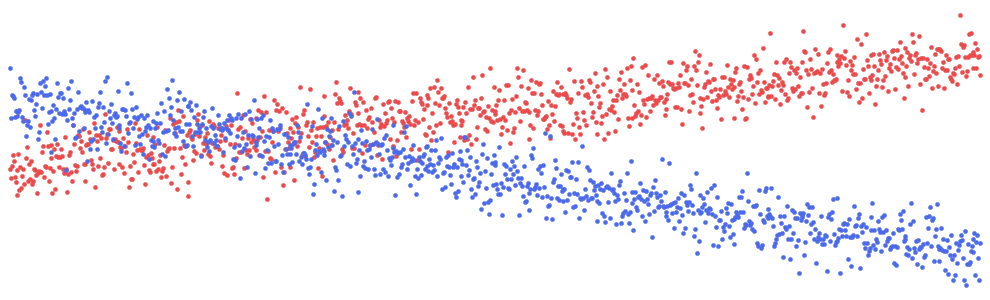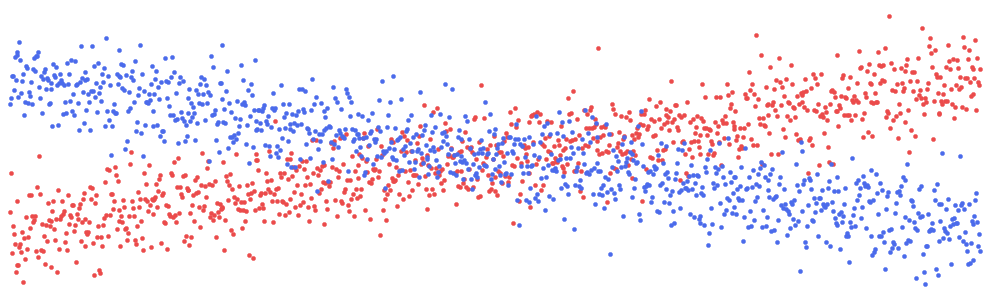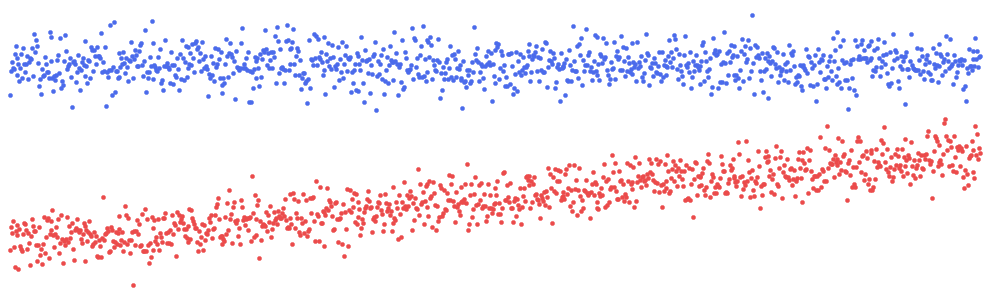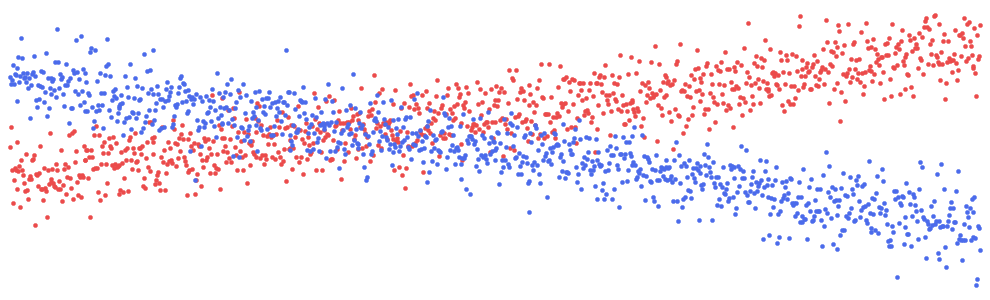
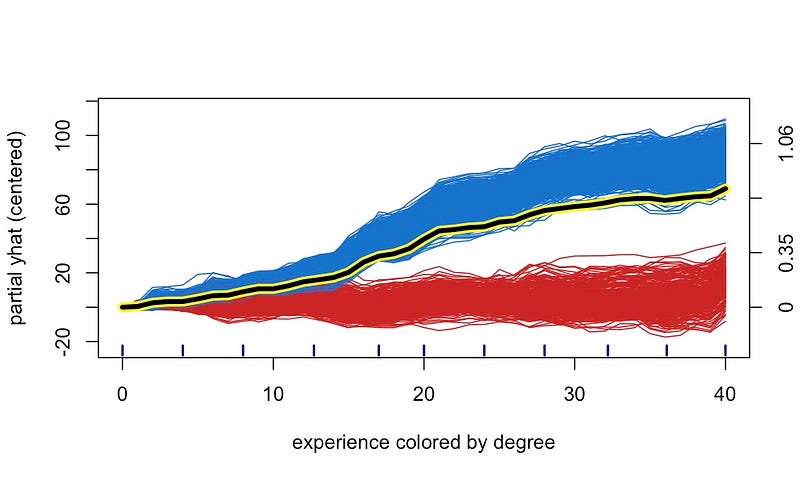
通过查看图 6 中的经验 ICE 图,你可以了解我们的意思。这里有两种不同的趋势。对于某些员工,预测奖金会随着经验的增加而增加;而对于某些员工,预测奖金不会随着经验的增加而增加。通过按学历对图表进行着色(即,学历为蓝色,否则为红色),你可以清楚地看到这是由于经验和学历之间的相互作用造成的。
我们可以为销售绩效交互创建一个类似的图表。如果员工的绩效评级高于 5,则线条为蓝色,如果低于 5,则线条为红色。所有员工的预测奖金都会增加,但绩效评级较低的员工的奖金增加速度较慢。对于这两个 ICE 图,交互作用比使用其相应的散点图时更清晰。
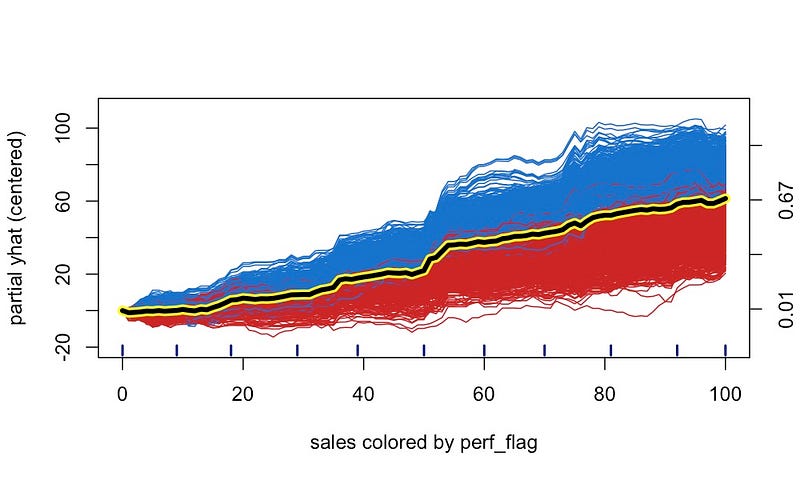
这些图非常有用,因为通过保持其他特征值不变,我们可以专注于一个特征的趋势。这就是预测如何由于该特征的变化而变化。此外,随机森林将模拟数据中的潜在趋势并使用这些趋势进行预测。因此,在绘制预测时,我们能够消除统计变化的影响。
充分利用 ICE 地块
我们使用了随机森林,但 ICE 图实际上是一种模型无关技术。这意味着我们在创建它们时可以使用任何模型。但是,模型应该是非线性的(即 XGBoost、神经网络)。线性模型无法以创建这些图所需的方式对交互进行建模。模型的选择并不重要,但根据你的数据集,不同的模型可能更擅长捕捉底层交互。
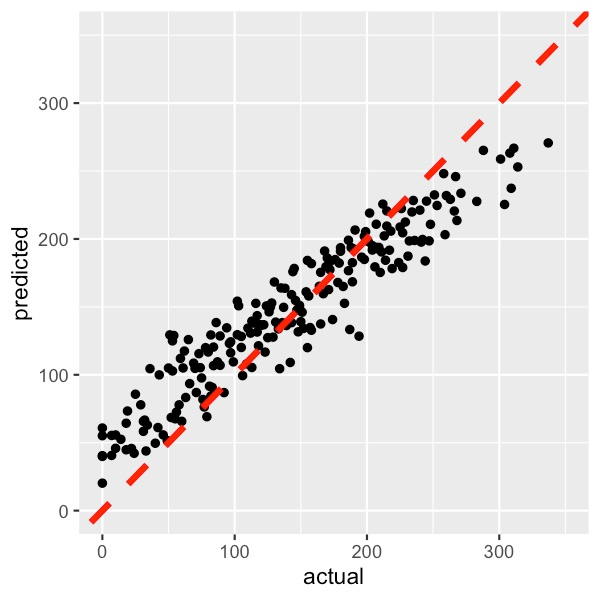
你使用的模型的准确性也不是那么重要。目标是可视化交互,而不是做出准确的预测。但是,你的模型越好,你的分析就越可靠。欠拟合的模型可能无法捕获交互,而过度拟合的模型可能会呈现实际上不存在的交互。最终,使用 k 折交叉验证或测试集测试你的模型非常重要。例如,你可以在图 8 中看到我们的随机森林的预测奖金值与实际奖金值的图。该模型并不完美,但我们能够捕捉到潜在的趋势。
仅使用 ICE 图可能不足以找到相互作用。根据数据集的大小,可能的相互作用数量可能很大。例如,如果你有 20 个特征,则将有 174 个可能的成对相互作用。可视化并尝试分析所有这些 ICE 图将非常繁琐。因此,我们需要一种突出显示/缩小搜索范围的方法。在本文的其余部分,我们将讨论如何使用特征重要性、Friedman 的 H 统计量和领域知识来做到这一点。
寻找相互作用
特征重要性
特征重要性是一个基于特定特征对模型准确性的提升程度的分数。如果我们在数据集中包含交互项,我们可以计算这些项的特征重要性。我们通过将每个特征的成对乘积相加(即经验 \(\times\) 学位)来实现这一点。然后,我们使用所有交互特征训练模型并计算最终的特征重要性。
在图 9 中,你可以看到 10 个交互特征和 5 个原始特征的特征重要性。在这里,我们使用随机森林作为模型,并使用 MSE 的百分比增加作为特征重要性得分。我们可以看到,经验度和销售业绩交互项都具有最高重要性。这表明这些术语之间存在相互作用。
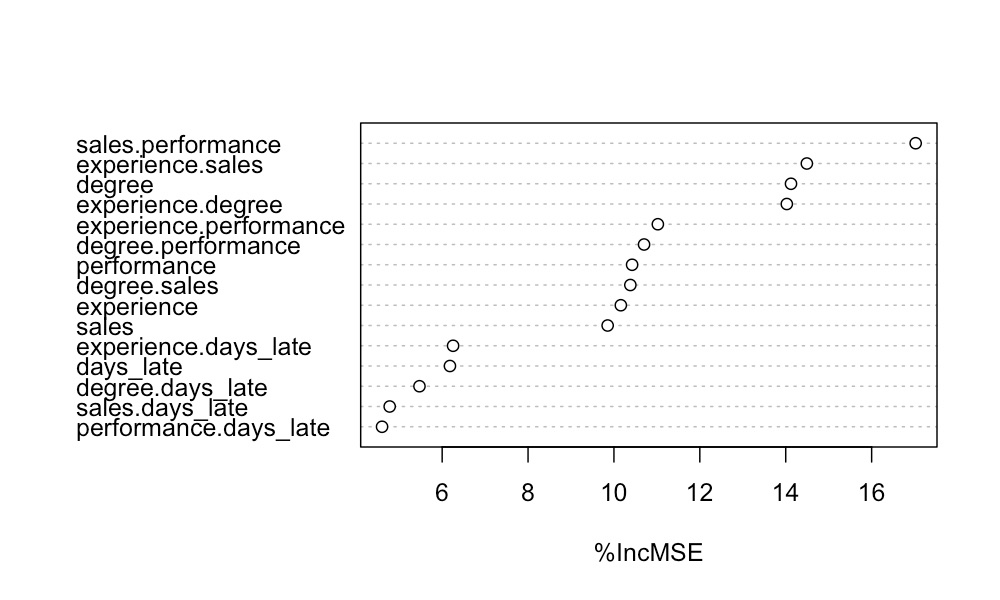
你可能还会注意到,其他一些交互项也很重要(例如,经验.销售额)。我们没想到这一点,因为在生成数据集时,我们没有包括这两个特征之间的交互。下面的图 10 有助于解释我们为什么会得到这个结果。请注意,经验和销售额都与奖金呈正相关。这意味着这些特征的乘积具有正相关关系。
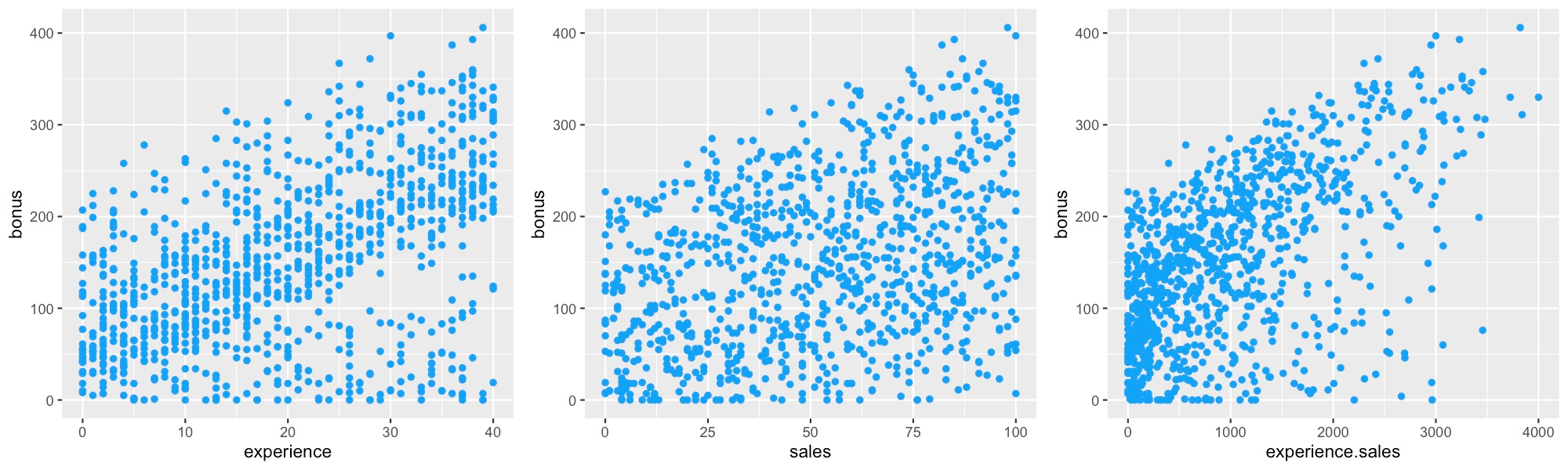
这凸显了该方法的一个缺点。特征对预测的影响可以分为两部分。第一部分是它直接对预测产生的影响(即主效应)。第二部分是它通过与其他特征的交互产生的影响(即交互效应)。experience.sales
交互项具有较高的特征重要性,因为这两个单独特征的主效应。因此,我们需要一种方法来将交互效应与主效应隔离开来。
弗里德曼的 H 统计量
Friedman的 H 统计量4就是这样做的。为了概述如何计算它,我们首先要拟合一个模型。在我们的例子中,我们使用与创建 ICE 图相同的随机森林。然后,我们在假设没有相互作用的情况下将观察到的部分依赖函数与部分依赖函数进行比较。两个函数之间的巨大差异表明存在相互作用。
该统计数据有两个版本。第一个版本通过与所有其他特征的交互来衡量特征的效果。你可以在图 11 中看到此统计数据的值。值为 1 表示特征仅通过交互对预测产生影响(即没有主效应)。值为 0 表示没有交互(即只有主效应)。对于经验,我们的 H 统计量为 0.28。我们可以将其解释为 28% 的经验效果来自此特征与其他特征的交互。
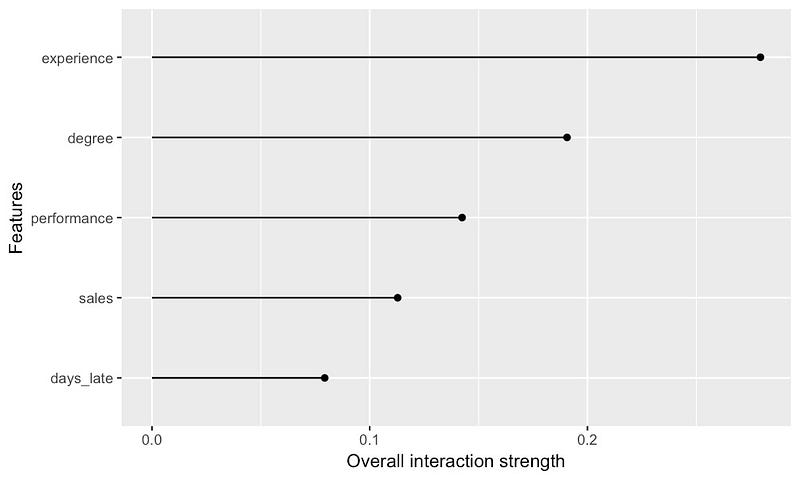
H 统计量的第二个版本衡量了两个特征之间的相互作用。图 12 中的第一个图表给出了经验和其他特征的 H 统计量。我们可以看到学位和经验之间的相互作用最为显著。同样,第二个图表给出了销售额的 H 统计量。同样,正如预期的那样,我们可以看到与绩效的相互作用最为显著。
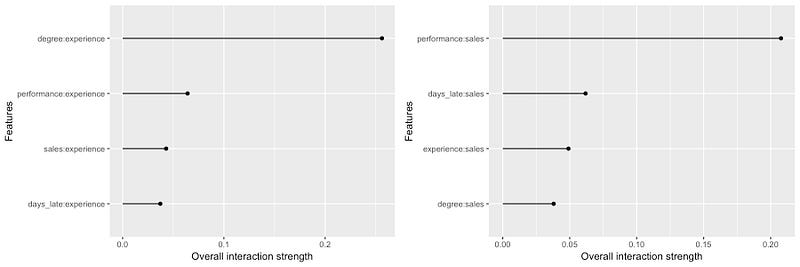
这个想法是首先使用总体 H
统计量来了解哪些特征具有交互作用。然后,我们可以使用第二个 H
统计量的图表来识别它们与之交互的其他特征。没有完美的统计数据,并且此过程可能并不总是有效。你可以看到,销售的总体
H 统计量相当低。它只有 0.11。这接近没有交互作用的 days_late
的 H
统计量。因此,按照此过程,我们可能决定不再进一步分析销售,从而错过了交互作用。
领域知识
正如我们上面所看到的,仅仅依靠这些方法,我们可能会错过一些交互或识别出实际上不存在的交互。这就是为什么将你对该领域的任何领域知识融入到这个过程中很重要的原因。你可能已经知道一些可以使用这些技术确认的交互。你还应该对发现的任何新交互进行感知检查。他们应该对它们存在的原因有一个直观的解释。希望通过结合使用领域知识和这些统计技术,你能够找到一些有用的交互。

参考
茶桁的公开文章代码仓库, https://github.com/conorosully/medium-articles↩︎
显式交互项, https://stattrek.com/multiple-regression/interaction.aspx↩︎
部分依赖图(PDP), https://christophm.github.io/interpretable-ml-book/pdp.html↩︎
Friedman的 H 统计量, https://christophm.github.io/interpretable-ml-book/interaction.html#theory-friedmans-h-statistic↩︎
寻找并可视化交互

