机器学习中的可解释性
为什么我们需要了解模型如何进行预测
「AI秘籍」系列课程:
我们是否应该始终信任表现良好的模型?模型可能会拒绝你的抵押贷款申请或诊断你患有癌症。这些决定的后果是严重的,即使它们是正确的,我们也希望得到解释。人类可以告诉你,你的收入太低,无法获得抵押贷款,或者特定的细胞群可能是恶性的。提供类似解释的模型比仅提供预测的模型更有用。

通过获得这些解释,我们说我们正在解释一个机器学习模型。在本文的其余部分,我们将更详细地解释可解释性的含义。然后,我们将继续讨论能够解释模型的重要性和好处。然而,仍然存在一些缺点。最后,我们将讨论这些问题,以及为什么在某些情况下,你可能更喜欢不太可解释的模型。
我们所说的可解释性是什么意思?
在之前的一篇文章中,我讨论了模型可解释性的概念以及它与 interpretable 和 explainable 的机器学习的关系。大部分时候,我们可以将 interpretable 理解为可解释模型,将 explainable 理解为解释性模型。其区别就在于前者通常比较简单、透明,人类可以很容易理解模型是如何得出结论的,而后者则需要通过后处理技术和工具来解释复杂和黑箱模型的决策过程,通过解释工具和方法,揭示模型的内部工作机制和决策依据。
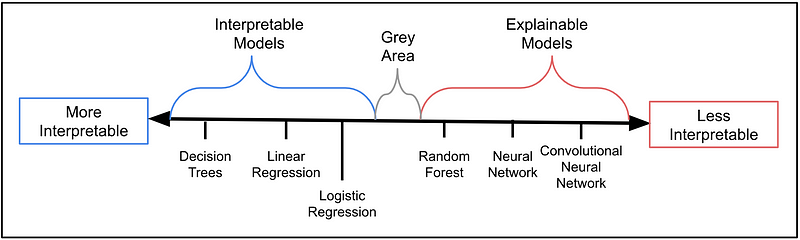
总而言之,可解释性是指模型在人类眼中可以被理解的程度。如果人类更容易理解模型 A 如何进行预测,则模型 A 比模型 B 更具可解释性。例如,卷积神经网络的可解释性不如随机森林,而随机森林的可解释性又不如决策树。
考虑到这一点,如果一个模型无需任何其他辅助/技术就能被理解,我们就说它是一个可解释的模型。Interpretable 的模型具有高度可解释性。相比之下,Explainable 的模型太复杂了,如果没有其他技术的帮助就无法理解。我们说这些模型的可解释性很低。我们可以在图 1 中看到这些概念是如何关联的。一般来说,模型可以分为 interpretable 或者 explainable,但也存在人们意见不一致的灰色地带。
为什么可解释性很重要?
如上所述,我们需要额外的技术,例如特征重要性1或LIME: https://github.com/marcotcr/lime,来了解 explainable 模型的工作原理。实现这些技术可能需要付出很多努力,而且重要的是,它们只能提供模型工作原理的近似值。因此,我们不能完全确定我们理解了 explainable 模型。在比较 interpretable 模型时,我们可能会遇到类似的情况。

例如,逻辑回归和决策树。这些都不需要额外的技术,但逻辑回归可能仍需要更多努力来解释。我们需要了解 S 型函数以及系数与几率/概率的关系。这种复杂性也可能导致我们的解释错误。一般来说,模型越容易解释,它就越容易理解,我们就越能确定我们的理解是正确的。可解释性很重要,因为它有很多好处。
更容易解释
我们的第一个好处是 interpretable 模型更容易向其他人解释。对于任何主题,我们理解得越好,解释起来就越容易。我们还应该能够用简单的术语来解释它(即不提及技术细节)。在行业中,许多人可能希望对你的模型的工作原理进行简单的解释。这些人不一定具有技术背景或机器学习经验。
例如,假设我们创建了一个模型,可以预测某人是否会提出人寿保险索赔。我们希望使用此模型来自动化公司的人寿保险承保。为了批准该模型,我们的老板需要详细解释其工作原理。不满的客户可能会要求解释为什么他们没有获得人寿保险批准。监管机构甚至可以依法要求提供这样的解释。

试图向这些人解释神经网络如何进行预测可能会引起很多困惑。由于不确定性,他们甚至可能不会接受这种解释。相比之下,像逻辑回归这样的可解释模型可以用人类的术语来理解。这意味着它们可以用人类的术语来解释。例如,我们可以精确地解释顾客的吸烟习惯在多大程度上增加了他们的死亡概率。
更容易感知、检查和修复错误
上面描述的关系是因果关系(即吸烟导致癌症/死亡)。一般来说,机器学习模型只关心关联。例如,模型可以使用某人的原籍国来预测他们是否患有皮肤癌。但是,就像吸烟一样,我们能说某人的国家导致癌症吗?原因是皮肤癌是由阳光引起的,而有些国家比其他国家阳光更充足。所以我们只能说皮肤癌与某些国家有关。

华盛顿大学研究人员进行的一项实验很好地说明了关联可能出错的地方。研究人员训练了一个图像识别模型,将动物分类为哈士奇或狼。他们使用 LIME 试图了解他们的模型如何做出预测。在图 2 中,我们可以看到该模型的预测是基于图像背景。如果背景有雪,动物总是被归类为狼。他们基本上建立了一个检测雪的模型。
问题在于狼与雪有关。狼通常会在雪地里出现,而哈士奇则不会。这个例子告诉我们,模型不仅可以做出错误的预测,还可以以错误的方式做出正确的预测。作为数据科学家,我们需要检查我们的模型,以确保它们不会以这种方式进行预测。你的模型越容易解释,就越容易做到这一点。

更容易确定未来表现
随着时间的推移,模型的预测能力可能会下降。这是因为模型特征和目标变量之间的关系可能会发生变化。例如,由于工资差距,收入目前可能是性别的良好预测指标。随着社会变得更加平等,收入将失去其预测能力。我们需要意识到这些潜在的变化及其对我们模型的影响。对于 explainable 模型来说,这一点更难做到。由于特征的使用方式不太清楚,即使我们知道对单个特征的影响,我们也可能无法判断对整个模型的影响。
更容易从模型中学习
试图在未知事物中寻找意义是人类的天性。机器学习可以帮助我们发现数据中未知的模式。但是,我们无法仅通过查看模型的预测来识别这些模式。如果我们无法解释我们的模型,那么任何教训都会丢失。最终,模型的可解释性越差,从中学习就越困难。

算法公平性
重要的是,你的模型必须做出公正的决策,这样它们才不会延续任何历史不公正。识别偏见的来源可能很困难。它通常来自模型特征与受保护变量(例如种族或性别)之间的关联。例如,由于南非有强制隔离的历史,种族与某人的所在地。位置可以作为种族的代理。使用位置的模型可能会偏向某一种族。
使用 interpretable 模型并不一定意味着你将拥有一个无偏见的模型。这也不意味着更容易确定模型是否公平。这是因为大多数公平性衡量标准(例如假阳性率、不同影响)与模型无关。对于任何模型,它们都很容易计算。使用 interpretable 模型确实可以更轻松地识别和纠正偏见来源。我们知道正在使用哪些特征,并且可以检查其中哪些与受保护的变量相关。

可解释性的缺点
好的,我们明白了…… interpretable 模型很棒。它们更容易理解、解释和学习。它们还使我们能够更好地感知当前性能、未来性能和模型公平性。然而,可解释性也存在缺点,在某些情况下我们更喜欢 explainable 模型。
容易被操纵
基于机器学习的系统容易受到操纵或欺诈。例如,假设我们有一个自动发放汽车贷款的系统。一个重要特征可能是信用卡数量。客户拥有的卡越多,风险就越大。如果客户知道这一点,他们可以暂时取消所有卡,申请汽车贷款,然后重新申请所有信用卡。

客户取消信用卡时偿还贷款的概率不会改变。客户操纵模型做出了错误的预测。模型越容易解释,就越透明,越容易操纵。即使模型的内部工作原理是保密的,情况也是如此。特征和目标变量之间的关系通常更简单,因此更容易猜测。
学习内容更少
我们提到,interpretable 模型更容易学习。但另一方面,它们不太可能教会我们新东西。像神经网络这样的 explainable 模型可以自动模拟数据中的交互和非线性关系。通过解释这些模型,我们可以发现这些我们从未知道存在的关系。
相比之下,线性回归等算法只能对线性关系进行建模。要对非线性关系进行建模,我们必须使用特征工程将任何相关变量纳入我们的数据集。这将需要事先了解这些关系,从而违背了解释模型的目的。
领域知识/专业知识要求
构建 interpretable 模型需要大量的领域知识和专业知识。通常,interpretable 模型(如回归)只能对数据中的线性关系进行建模。要对非线性关系进行建模,我们必须执行特征工程。例如,对于医学诊断模型,我们可能希望使用身高和体重来计算 BMI。了解哪些特征具有预测性以及创建哪些特征需要特定领域的领域知识。
你的团队可能不具备这些知识。或者,你可以使用 explainable 模型,该模型将自动对数据中的非线性关系进行建模。这样就无需创建任何新特征;本质上将思考留给了计算机。正如我们上面详细讨论的那样,缺点是,对如何使用这些特征进行预测的理解较差。

复杂性与准确性之间的权衡
从上面我们可以看出,一般来说,模型越简单,可解释性就越强。因此,为了获得更高的可解释性,可能会以较低的准确度为代价。这是因为,在某些情况下,较简单的模型可能会做出不太准确的预测。这实际上取决于你要解决的问题。例如,使用逻辑回归进行图像识别会得到较差的结果。
对于许多问题,interpretable 模型的表现与 explainable 模型一样好。在之前的文章「特征工程的力量」中,我们将 interpretable 模型 Logistic 回归与 explainable 模型神经网络进行了比较。我们证明,通过对我们的问题进行一些思考并创建新特征,我们可以用 interpretable 模型实现类似的准确性。这是对我们在本文中讨论的一些概念的一个很好的实践。
特征工程的力量
为什么你应该使用逻辑回归来建模非线性决策边界(使用 Python 代码)
参考
How to Calculate Feature Importance With Python, https://machinelearningmastery.com/calculate-feature-importance-with-python/#:~:text=Feature%20importance%20refers%20to%20techniques,at%20predicting%20a%20target%20variable.↩︎
机器学习中的可解释性

