查找并可视化非线性关系
使用部分依赖图 (PDP)、互信息和特征重要性分析非线性关系
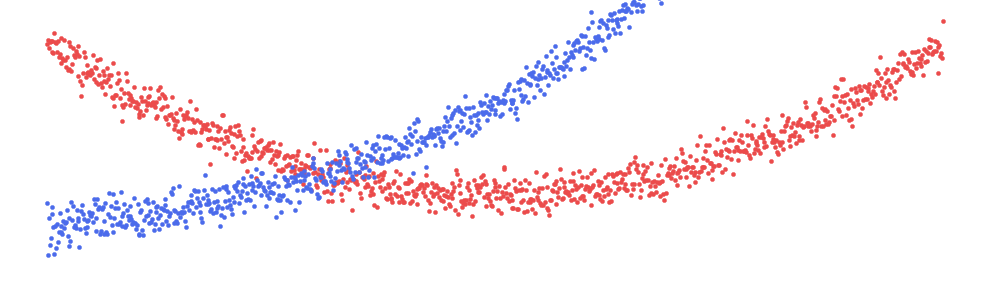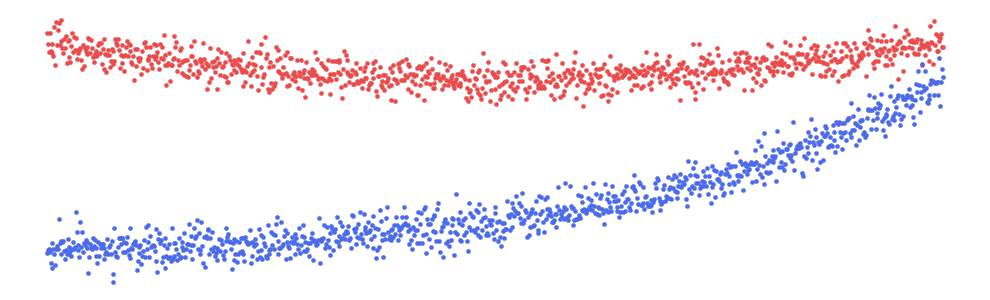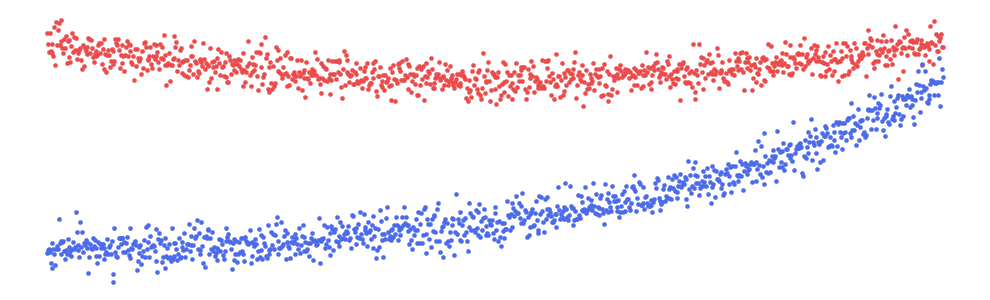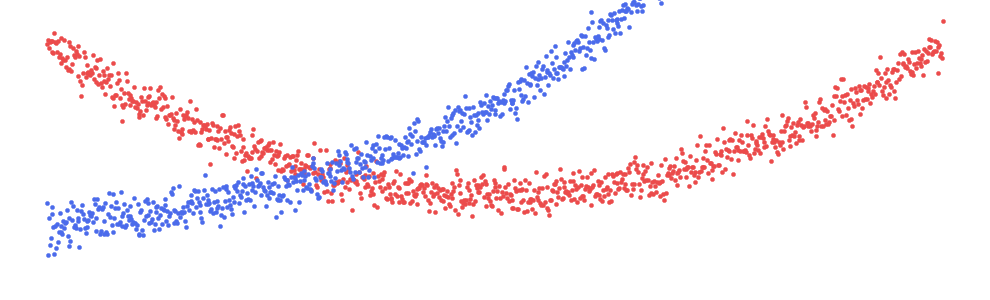
刚开始开车时,你的经验较少,有时还会比较鲁莽。随着年龄的增长,你会获得更多的经验(和意识),发生事故的可能性也会降低。然而,这种趋势不会永远持续下去。当你年老时,你的视力可能会下降,反应可能会变慢。现在,随着年龄的增长,你发生事故的可能性会更大。这意味着发生事故的概率与年龄呈非线性关系。找到并整合此类关系可以提高模型的准确性和解释性。
在本文中,我们将深入探讨非线性关系。我们将探索如何使用散点图和部分依赖图 (PDP) 来可视化它们。然后,我们将继续介绍如何突出显示数据中的潜在非线性关系。这些包括特征重要性和相互信息等指标。您可以在 GitHub1 上找到用于此分析的 R 代码。在开始之前,有必要准确解释一下我们所说的非线性关系。
什么是非线性关系?
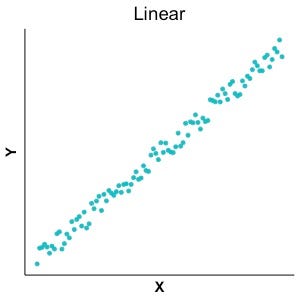
如果两个变量具有线性关系,我们可以用直线来概括这种关系。直线的斜率可以是正斜率也可以是负斜率,但斜率始终保持不变。您可以在图 1 中看到一个示例。在这种情况下,我们有一个正线性关系。另一种看待这个问题的方式是,无论 X 的起始值是多少,变量 X 的增加都会导致 Y 的相同增加。
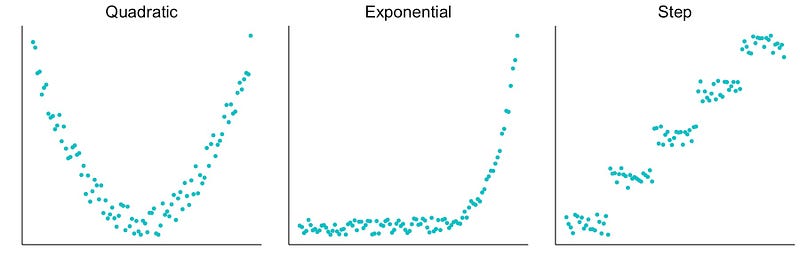
另一方面,对于非线性关系,变量 X 的变化导致变量 Y 的变化将取决于 X 的起始值。您可以在图 2 中看到一些这样的示例。上面给出的年龄-事故关系可能是二次的。也就是说,事故发生的概率会随着年龄的增长而降低,然后增加。最终,任何不能用直线概括的关系都是非线性关系。准确地说,这些关系还包括相互作用,但我们在另一篇文章中重点讨论这些类型的关系。
非线性模型,如随机森林和神经网络,可以自动对上述非线性关系进行建模。如果我们想使用线性模型,如线性回归,我们首先必须进行一些特征工程。例如,我们可以将 \(age^2\) 添加到我们的数据集中以捕获二次关系。为了进行更有效的特征工程,首先在我们的数据中找到这些关系会有所帮助。
数据集
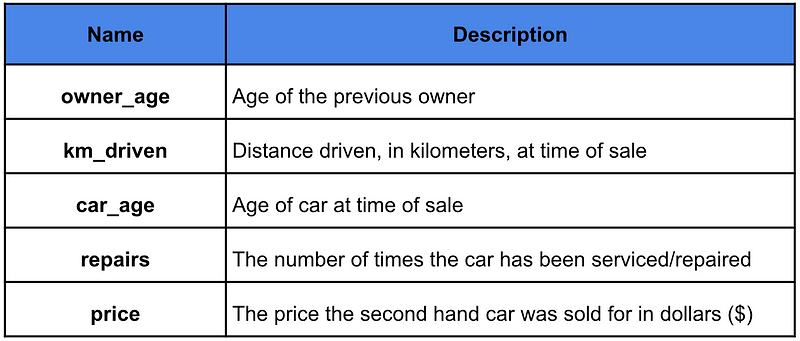
为了帮助解释如何找到这些关系,我们将使用随机生成的数据集。您可以在表
1
中看到特征列表,其中price是我们的目标变量。我们将尝试使用这
4 个特征来预测二手车的价格。数据集的设计使得 car_age、
repairs 与 price
具有非线性关系。而km_driven
具有线性关系,owner_age 没有关系。
您可以在图 3 中的散点图中看到我们的意思。在这里我们可以看到具有非线性关系的两个特征。如果这是一个真实的数据集,我们会期待一些直观的原因。例如,汽车的价格随着年龄的增长而下降是有道理的,但为什么它随后开始上涨?也许大多数老爷车都是经典,因此价格会随着年龄的增长而上涨。
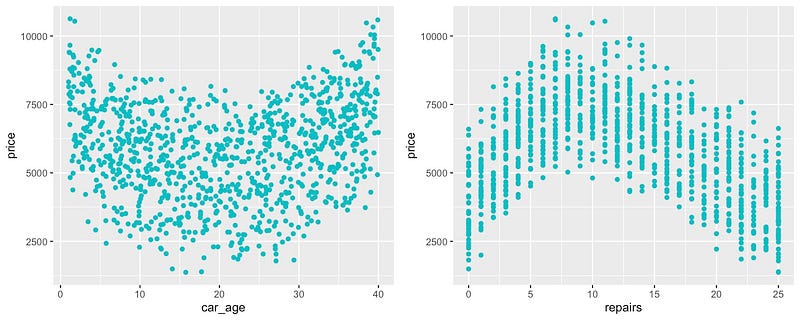
我们可以对维修功能做出类似的描述。这是汽车接受保养或维修的次数。在汽车的整个使用寿命中,对汽车进行例行保养是正常的。因此,此功能的值较小可能表示汽车已被忽视。另一方面,值较大可能表示汽车在这些标准服务之外还需要额外的维修。这些汽车将来可能会给新车主带来更多问题。
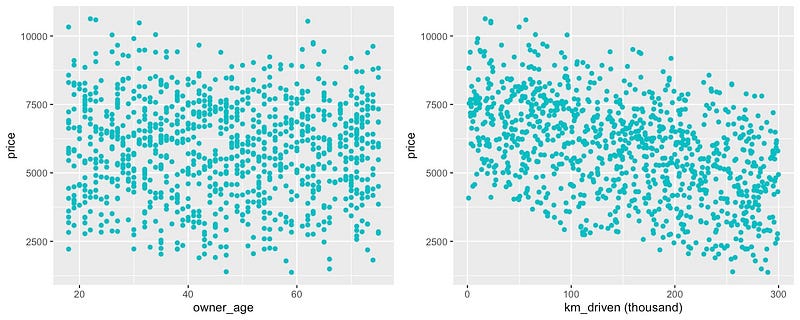
您可以在图 4
中看到其余的关系。如前所述,owner_age与price没有关系。我们可以在图表中看到这一点,因为这些点是随机分散的。我们还可以看到
km_driven与price
呈负线性关系。我们之所以包括这些,是因为将这些关系的分析与非线性关系的分析进行比较会很有用。
散点图是一种可视化非线性关系的简单方法,但并不总是有效。对于每个图表,我们可视化的是目标变量与一个特征之间的关系。实际上,目标变量将与许多特征有关系。这和统计变化的存在意味着这些点将围绕潜在趋势展开。我们已经可以在上面的图表中看到这一点,而在真实的数据集中,情况会更糟。最终,为了清楚地看到关系,我们需要剔除其他特征和统计变化的影响。
部分依赖图 (PDP)
这让我们想到了 PDP。要创建 PDP,我们首先必须将模型拟合到我们的数据中。具体来说,我们使用一个有 100 棵树的随机森林。在表 2 中,我们的数据集中有两行用于训练模型。在最后一列中,我们可以看到二手车的预测价格。这些是随机森林根据特征值做出的预测。
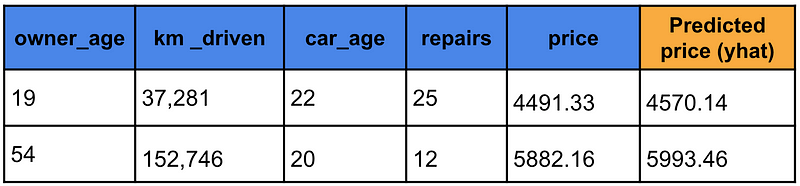
要创建
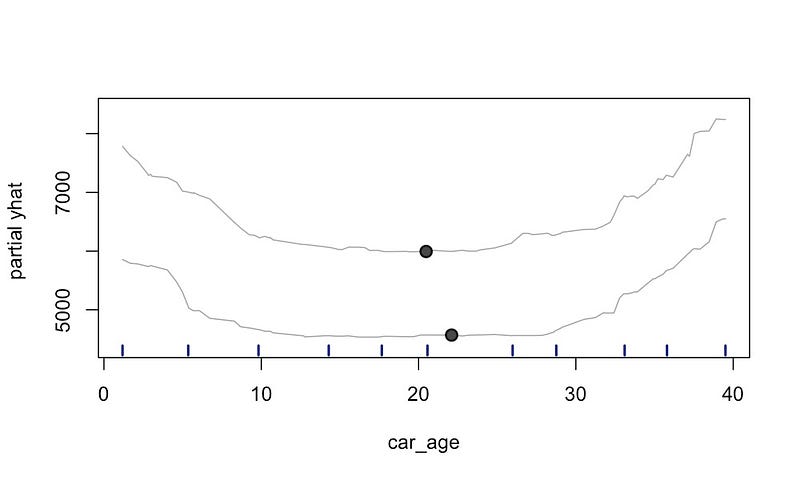
PDP,我们首先要改变一个特征的值,同时保持其他特征不变。然后,我们绘制每个特征值的结果预测。查看图
5,这可能更有意义。这里我们取了表 2
中的两辆车。我们绘制了car_age的每个可能值的预测价格(部分
yhat) ,同时保持其他特征的原始值。(例如,repairs
费用将保持在 25 和 12)。两个黑点对应于表 2
中的实际预测(即它们的真实car_age)。
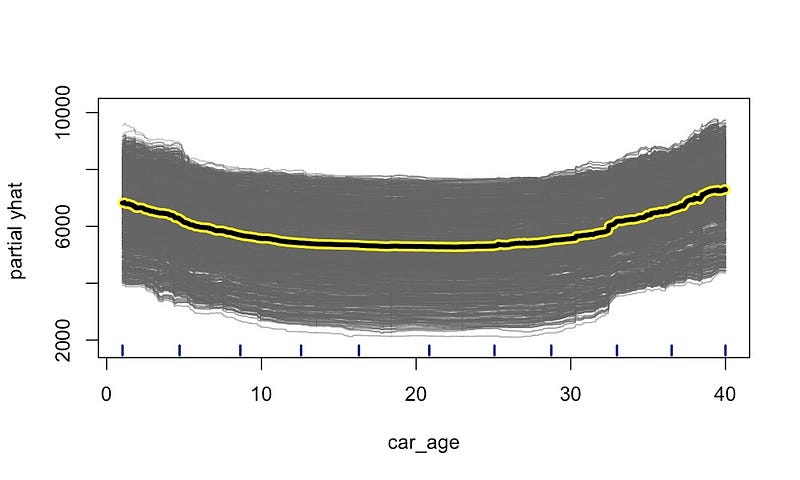
我们对数据集中的每一行都遵循此过程。您可以在图 6
中看到所有这些单独的预测线。最后,为了创建
PDP,我们计算car_age
每个值的平均预测值。这由粗黄线显示。您现在可以清楚地看到非线性关系。也就是说,预测价格最初下降,但后来上升。同样,我们可以在图
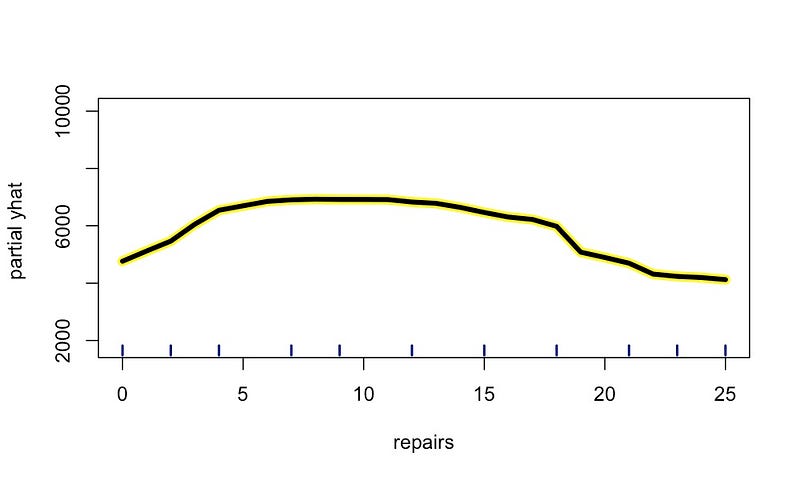
7 中看到 repairs 的非线性关系。
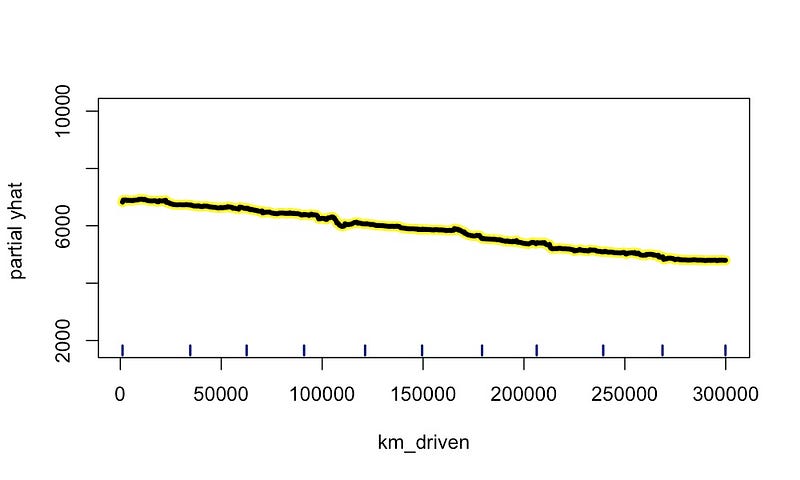
相比之下,我们可以在图 8 中看到 km_driven 的 PDP,在图 9
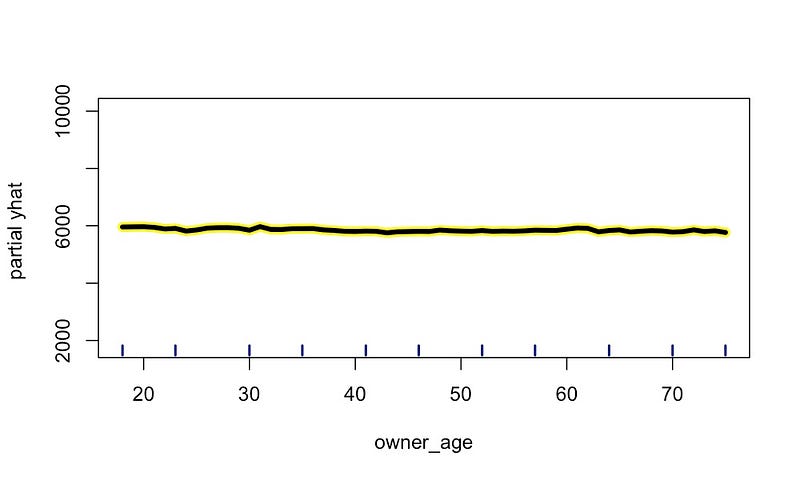
中看到 own_age 的 PDP。如前所述,km_driven 与
price 呈线性关系。我们可以在 PDP
中看到这一点,其中平均预测值呈线性下降。同样,它与 own_age
没有关系。这里平均预测值保持相当稳定。
这些图表提供了更清晰的趋势可视化,原因有二。首先,通过保持其他特征值不变,我们可以专注于一个特征的趋势。这就是预测如何由于该特征的变化而变化。其次,随机森林将模拟数据中的潜在趋势并使用这些趋势进行预测。因此,在绘制预测时,我们能够消除统计变化的影响。
充分利用您的 PDP
查看图 10,您可以了解用于创建这些 PDP 的随机森林的准确性。该模型并不完美,但它在预测汽车价格方面做得相当好。事实上,模型的准确性并不那么重要。目标是可视化非线性关系,而不是做出准确的预测。但是,您的模型越好,您的分析就越可靠。欠拟合模型可能无法捕捉到关系,而过度拟合模型可能会显示实际上不存在的关系。
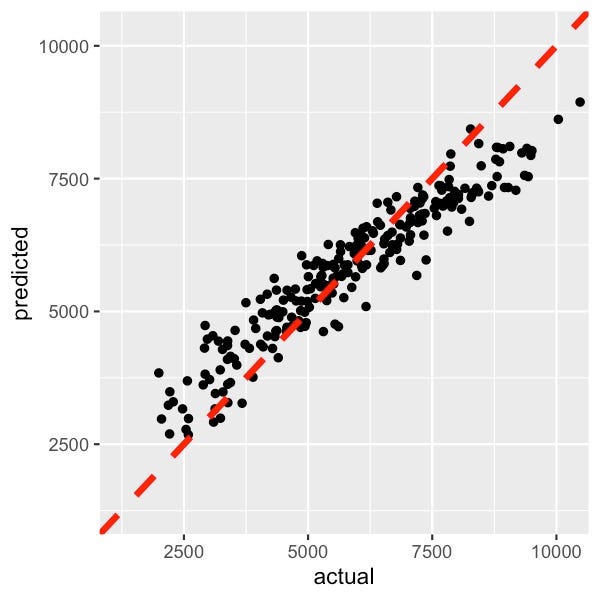
模型的选择也不是那么重要。这是因为 PDP 是一种模型无关的技术。在这个分析中,我们使用了随机森林,但您可以使用任何非线性模型,例如 XGBoost 或神经网络。根据您的数据集,不同的模型可能更擅长捕捉底层的非线性关系。
寻找非线性关系
仅使用 PDP 可能不足以找到非线性关系。这是因为您的数据中可能有许多特征,而尝试分析所有 PDP 将非常耗时。我们需要一种缩小搜索范围的方法。也就是说,我们需要一个指标来告诉我们我们的特征和目标变量之间是否存在显著关系。然后我们可以专注于这些特征。在本文的其余部分,我们将探讨如何使用特征重要性或相互信息来做到这一点。
为什么我们不能使用相关性
在深入研究这些指标之前,有必要讨论一下为什么相关性不合适。皮尔逊相关系数2是用于寻找显著关系的常用指标。然而,它是线性相关性的度量,这意味着它只能用于寻找线性关系。我们可以在图
11 中看到这一点,其中 km_driven 和 price
之间存在很大的负相关性。相比之下, car_age
的相关性要低得多。
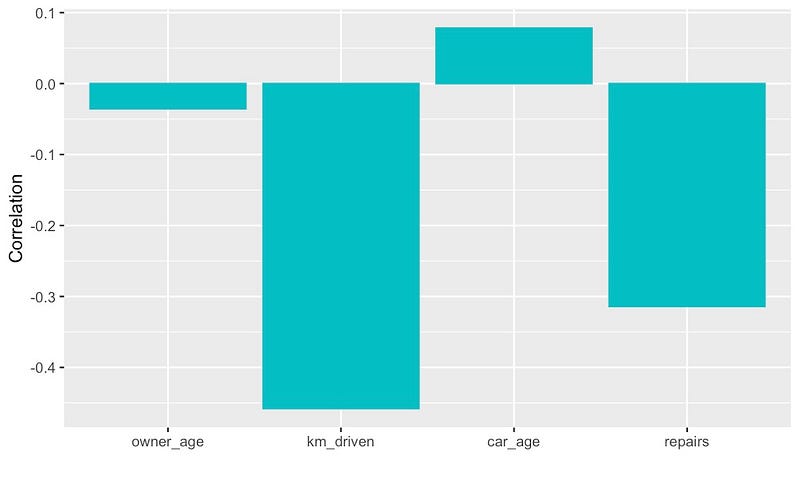
在某些情况下,线性趋势可能能够很好地近似非线性趋势。因此,即使对于非线性关系,我们仍可能会看到一些高相关值。我们可以在特征
repairs
中看到这一点,其中仍然存在相当大的负相关性。一般来说,这个指标不会帮助我们识别非线性关系。
相互信息
互信息3量度了一个变量的不确定性通过观察另一个变量而减少的程度。它通过将变量的联合分布与边际分布的乘积进行比较来实现这一点。如下所示,独立变量的联合分布将等于它们的边际分布的乘积。因此,如果联合分布不同,则表明存在依赖关系,我们将计算更高的互信息值。最终,依赖关系意味着两个变量之间存在关系。
对于独立变量:\(f(x,y) = f(x)f(y)\)
两个变量之间存在依赖关系,关系不一定是线性的。这意味着可以使用该指标来突出显示非线性关系。请参见图 13 中的价格与我们的 4 个特征之间的相互信息值。与相关性相比,我们现在可以看到与目标变量有关系的所有特征的值都更高。
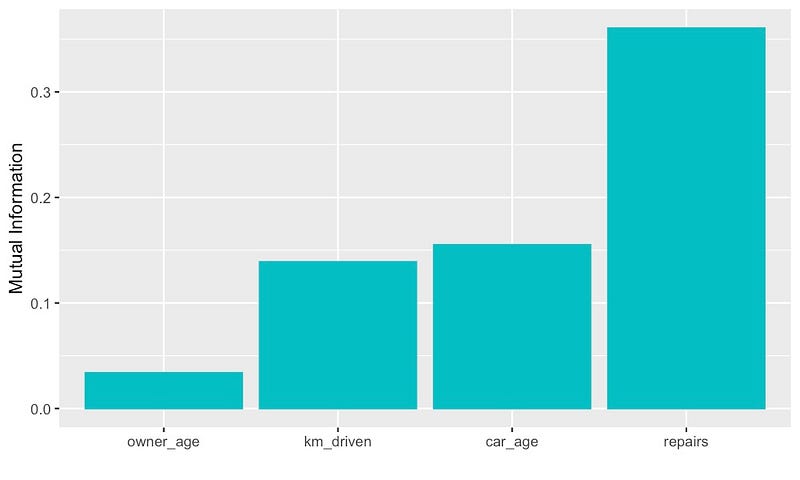
在本分析中,我们仅研究了连续变量。互信息也可用于离散变量。即当一个变量是离散的而另一个变量是连续的,或者当两个变量都是离散的时。这是相关性的另一个优势,因为相关性只能用于连续变量。
特征重要性
另一种方法是先训练一个模型,然后使用该模型的特征重要性分数。特征重要性衡量了某个特定特征对模型准确性的提高程度。在图 12 中,您可以看到从我们用于创建 PDP 的同一随机森林中获得的分数。具体来说,我们使用 MSE 的百分比增加作为特征重要性的衡量标准。
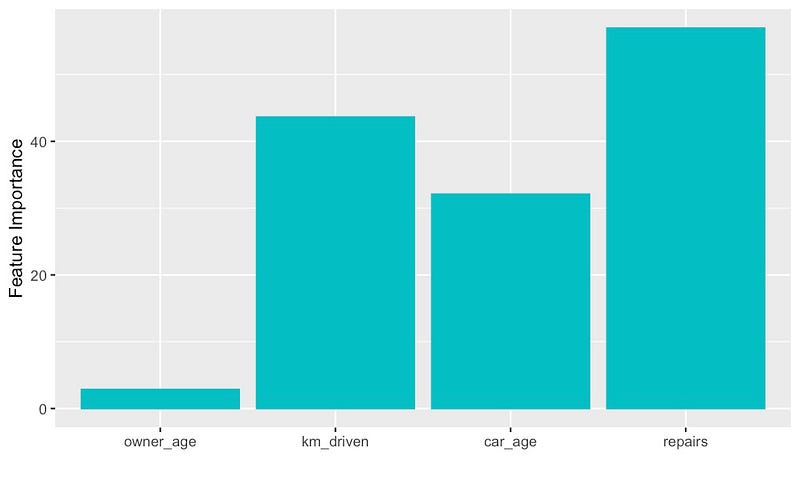
与 PDP 一样,只要是非线性的,我们就可以对此方法使用任何模型。我们不能使用线性模型(如线性回归),因为它们无法对非线性关系进行建模。换句话说,具有非线性关系的特征可能无法提高准确率,从而导致特征重要性得分较低。
最后,我们可以使用互信息和特征重要性来强调非线性(和线性)关系。但是,这些指标并没有告诉我们这些关系的性质。即关系是二次的、指数的、逐步的等等……因此,一旦我们强调了这些潜在关系,我们就必须回到 PDP 来确定它们的性质。
如上所述,交互作用是一种特殊类型的非线性关系。当目标变量和特征之间的关系取决于另一个特征的值时,就会发生这种情况。我们在文章《寻找并可视化交互》中以类似的方式分析这些类型的关系。
AI 进阶:企业项目实战4
参考
C. Molnar, Interpretable Machine Learning(2021) https://christophm.github.io/interpretable-ml-book/interaction.html
「AI秘籍」系列课程:
查找并可视化非线性关系

