# read in full dataset data = pd.read_csv(data_path + '/public_articles/sentences.csv', sep='\t', encoding='utf8', index_col=0, names=['lang','text'])
# Filter by text length data = data[data['text'].str.len().between(20, 200)]
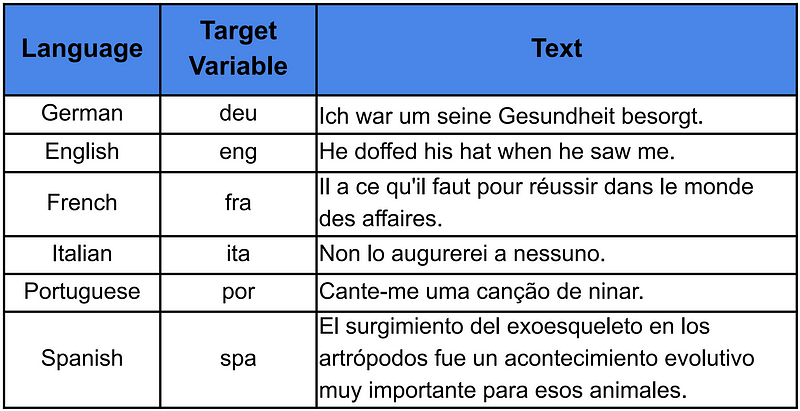
# Filter by text language lang = ['deu', 'eng', 'fra', 'ita', 'por', 'spa'] data = data[data['lang'].isin(lang)]
# Select 50000 rows for each language data_trim_list = [data[data['lang'] == l].sample(50000, random_state=100) for l in lang]
# Concatenate all the samples data_trim = pd.concat(data_trim_list)
# Create a random train, valid, test split data_shuffle = data_trim.sample(frac=1, random_state=100)
train = data_shuffle[:210000] valid = data_shuffle[210000:270000] test = data_shuffle[270000:300000]
# Check the shapes to ensure everything is correct print(f"Train set shape: {train.shape}") print(f"Validation set shape: {valid.shape}") print(f"Test set shape: {test.shape}")
from sklearn.feature_extraction.text import CountVectorizer
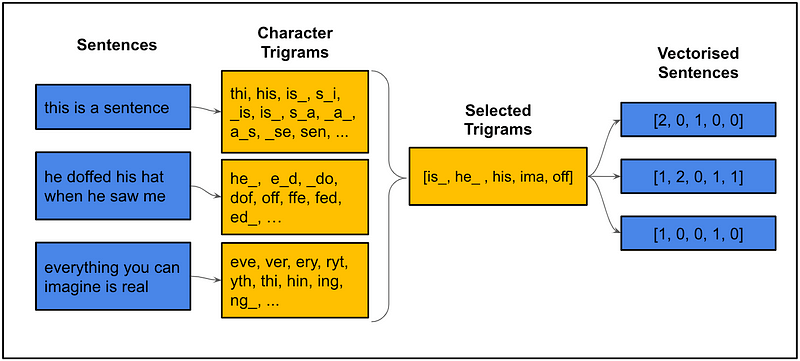
defget_trigrams(corpus, n_feat=200): """ Returns a list of the N most common character trigrams from a list of sentences params ------------ corpus: list of strings n_feat: integer """ # fit the n-gram model vectorizer = CountVectorizer(analyzer='char', ngram_range=(3, 3), max_features=n_feat)
X = vectorizer.fit_transform(corpus)
# Get model feature names feature_names = vectorizer.get_feature_names_out() return feature_names
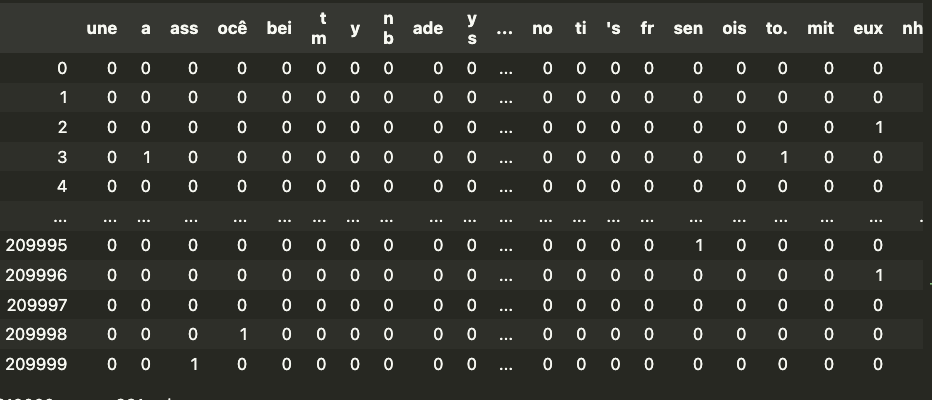
# create feature matrix for training set corpus = train['text'] X = vectorizer.fit_transform(corpus) feature_names = vectorizer.get_feature_names_out()
import matplotlib.pyplot as plt import seaborn as sns from sklearn.metrics import accuracy_score, confusion_matrix import numpy as np
# x_test 和 y_test 已经定义,并且 model 是一个已训练好的 Keras 模型 x_test = test_feat.drop('lang', axis=1) y_test = test_feat['lang']
# Use model.predict to get probabilities predictions_prob = model.predict(x_test) # Find the index of the highest probability for each sample labels = np.argmax(predictions_prob, axis=1) predictions = encoder.inverse_transform(labels)
# Ensure y_test is a 1D array if y_test.ndim > 1: y_test = np.argmax(y_test, axis=1)
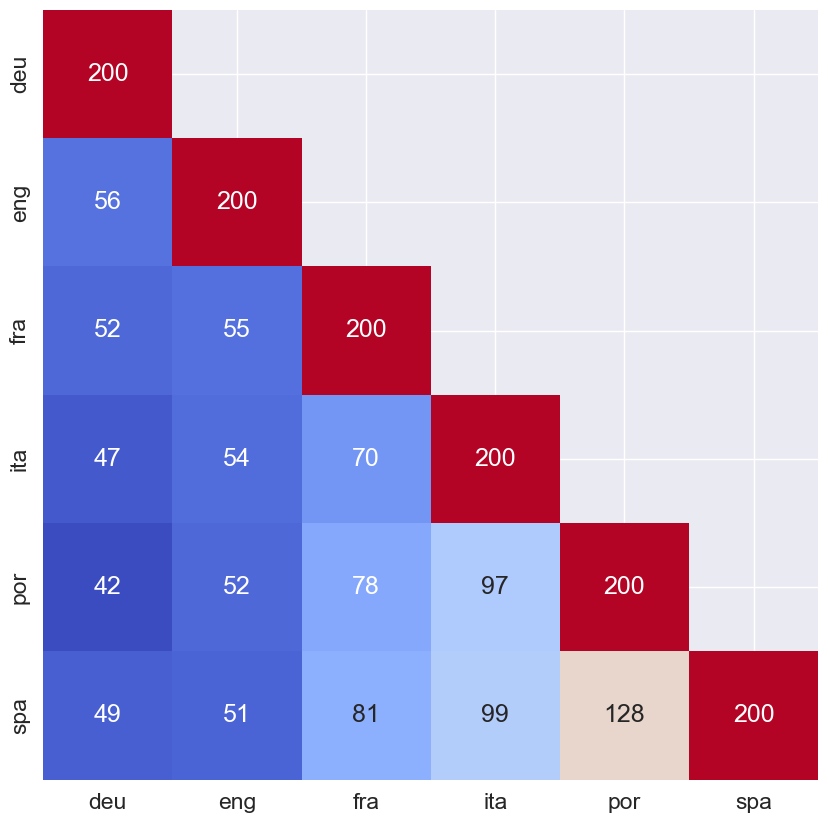
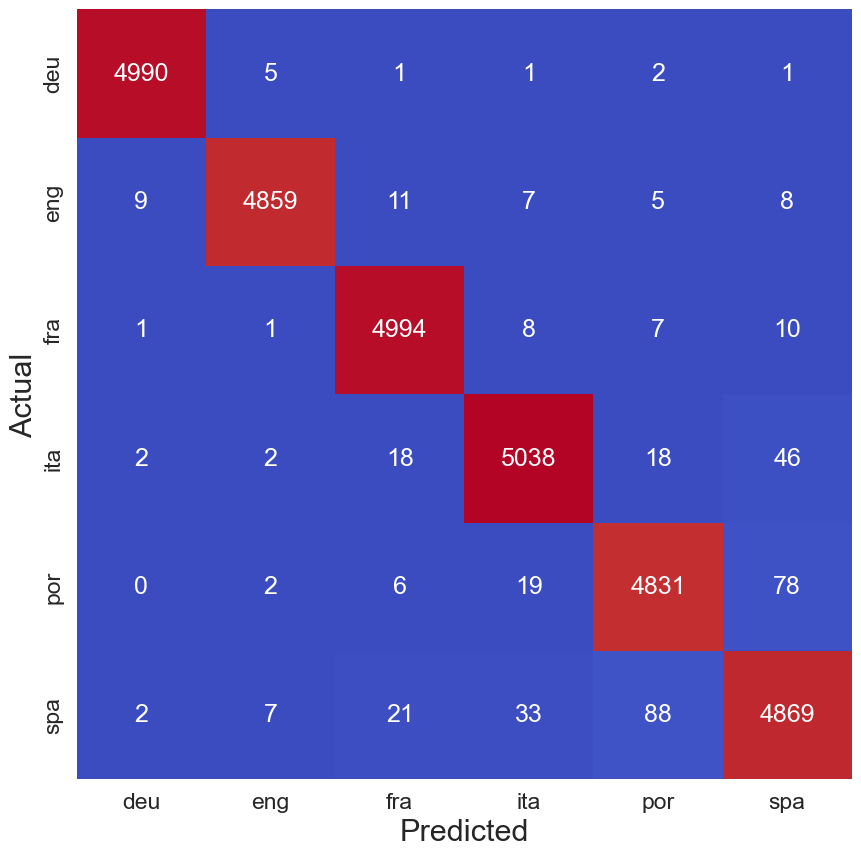
# Accuracy on test set accuracy = accuracy_score(y_test, predictions) print(f"Accuracy: {accuracy}")