纠正和防止机器学习中的不公平现象
预处理、处理中、后处理方法和非定量方法
「AI秘籍」系列课程:

机器学习中的公平性是一个复杂的问题。更糟糕的是,负责构建模型的人不一定具备确保公平的技能。这是因为不公平的原因超出了数据和算法的范围。这意味着解决方案也需要超越量化方法。
为了理解这一点,我们将首先讨论不同的定量方法。我们可以将这些方法分为预处理、处理中和处理后。我们将重点关注这些方法的局限性,以了解为什么它们可能无法解决不公平问题。最终,我们需要将公平视为一个更广泛的问题。
这就是为什么我们将继续讨论非定量方法。它们包括不使用或限制使用ML。提供解释、说明和挑战决策的机会是一个重要方面。它们还包括解决不公平的根本原因、对问题的认识和团队多样性。要有效解决不公平问题,需要结合定量和非定量方法。
定量方法
数据科学家擅长采用定量方法来确保公平。他们通过调整用于训练模型的数据或训练的算法来工作。查看图 1,您可以看到我们可以将这些方法分为预处理、处理中和后处理方法。这种划分取决于它们在模型开发的哪个阶段应用。
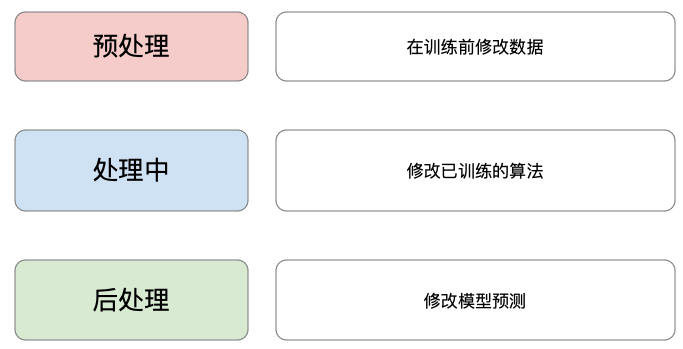
预处理
不公平的模型可能是数据偏差的结果。预处理方法试图在数据用于训练模型之前消除数据偏差 。数据经过转换,算法按照原始数据集的方式进行训练。希望最终的模型是公平的。即使准确度较低。
不公平模型的原因 其中之一是目标变量反映了历史上不公平的决策。这对于主观目标变量来说更常见。例如,性别歧视的招聘做法可能会导致更高比例的女性被拒绝求职。为了解决这个问题,一种预处理方法是交换先前决策的目标变量。也就是说,我们重新标记不公平的招聘决策,以人为地增加我们数据集中被雇用的女性数量。
一个问题是,改变目标变量并不总是可行的。目标变量通常是客观的。例如,我们不能将之前的贷款违约重新标记为非违约。对于一些主观目标变量来说,这可能也很困难。这是因为我们在做出决定时可能没有所有可用的信息。对于招聘决定,我们可能有简历。然而,我们可能没有录音面试,而这是申请的很大一部分。

不公平模型的另一个原因是代理变量。这些是与受保护变量相关或关联的模型特征。受保护变量代表种族或性别等敏感特征。其他方法着眼于“修复”或消除模型特征中的偏见。这些方法通过消除模型特征与受保护变量之间的关联来实现。
这种方法的一个例子是差异影响消除(DIR)。受保护变量通常分为特权组(例如男性)和非特权组(例如女性)。DIR 通过修改特征来工作,以便两个组的分布变得相似。例如,参见图 2。这里修改了男性和女性的收入分布。
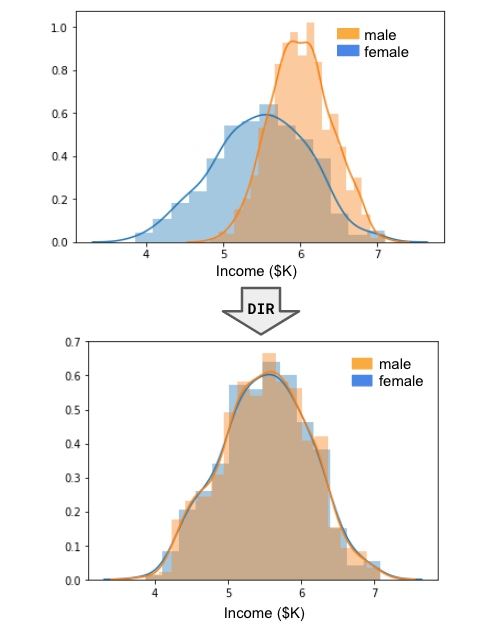
DIR 保持每个子群体内的排名顺序。也就是说,如果你是特权群体中收入最高的人,那么你仍然是该群体中收入最高的人。只有两个群体之间的排名顺序受到影响。结果是我们将不再能够使用收入来区分这两个群体。同时,我们将保留收入预测目标变量的部分能力。
DIR 还有一个调整参数,它在准确性和公平性之间引入了权衡。它允许您控制分布的偏移量。换句话说,它允许您仅删除模型特征和受保护变量之间的部分关联。
预处理方法的一个优点是它们可以与任何算法一起使用。这是因为只修改了数据。一个主要的缺点是我们的功能的解释不再清晰。我们可能需要修复多个受保护变量(例如性别、种族、原籍国)的特征值。特征分布经过如此多的转变后,它就失去了解释能力。向非技术受众解释这样的模型将具有挑战性。
进行中
我们可以调整 ML 算法,而不是转换数据。这些被称为内部处理方法。通常,模型经过训练以最大化某种准确度。内部处理方法通过调整目标来考虑公平性。这可以通过更改成本函数来考虑公平性或对模型预测施加约束来实现。模型是在有偏差的数据上进行训练的,但最终结果是公平的模型。
对于回归,一种方法是向成本函数添加惩罚参数。这与正则化的工作方式类似。对于正则化,我们惩罚参数值以降低复杂性和过度拟合。现在我们引入一个减少不公平性的惩罚参数。
具体来说,该参数旨在满足公平性的数学定义。例如,参见图 3 中的均等赔率。这里,下标 0 表示无特权组,下标 1 表示有特权组。根据此定义,我们要求相等的真正率 (TPR) 和假正率 (FPR)。
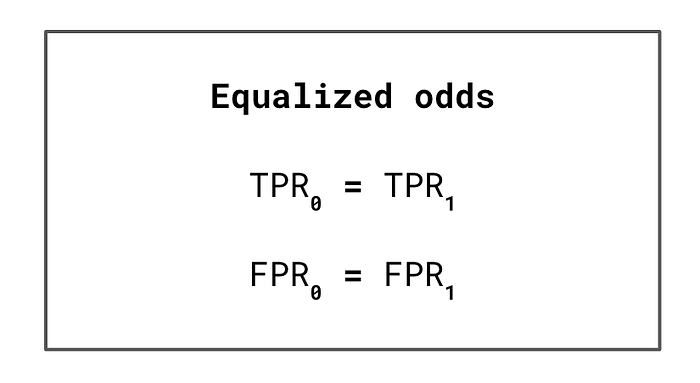
均等机会只是公平的一个潜在定义。其他定义包括平等机会和不同影响。我们曾在文章《分析机器学习中的公平性》 中讨论所有这些。我们还讨论了每个定义的理由,并向您展示如何使用 Python 应用它们。
这些方法的一个缺点是它们在实践中可能难以实施。它们需要调整成熟的算法。与预处理方法不同,这些调整也是针对特定算法的。我们引入惩罚参数的方式对于回归、树方法或神经网络会有所不同。
尝试用数学方法定义公平性也存在问题。这样做可能会忽略公平性的细微差别。在追求单一定义时,这种情况会变得更加困难。如果我们基于一种定义实现公平性,则不一定能基于另一种定义实现公平性。尝试将多种定义纳入惩罚参数将大大增加算法的复杂性。
后期处理
后处理方法通过改变模型的预测来工作。我们不对数据或算法进行任何调整。我们只是交换某些模型预测(例如从正到负)。目标是只对不公平的预测进行此操作。
一种方法是针对特权群体和非特权群体设置不同的阈值。例如,假设我们使用逻辑回归来预测贷款申请违约。我们将小于 0.5 的概率标记为正 (1)。也就是说,预测他们不会违约,我们会向客户提供贷款。假设使用 0.5 的阈值,我们发现女性 (0) 的 TPR 明显低于男性 (1)。
换句话说,图 4 中的平等机会并未得到满足。为了解决这个问题,我们可以将女性的概率阈值提高到 0.6。也就是说,我们对男性(0.5)和女性(0.6)设置了不同的阈值。结果是,更多的女性被接受贷款,从而导致更高的 TPR。在实践中,我们可以调整阈值,以实现 TPR 的差异在某个临界值之内。

这种方法的一个问题是,它要求我们在预测时掌握受保护变量的信息。要决定使用什么阈值,我们需要有关申请人性别的可靠信息。在许多情况下,由于法律或隐私原因,此类信息仅在培训期间可用。我们也面临着与内部处理方法类似的缺点。也就是说,我们将尝试基于一个定义实现公平。
定量方法的缺点
数据科学家倾向于关注这些公平的量化方法。这正是我们的优势所在。然而,认为仅通过调整数据和算法就能解决不公平问题的想法是天真的。公平是一个复杂的问题,我们需要将其视为超越数据集的东西。只使用量化方法就像不先取出子弹就缝合枪伤一样。
“因此,不公正和有害的结果被视为副作用,可以通过技术解决方案(例如“去偏见”数据集)来处理,而不是那些根植于模糊和偶然问题的数学化、历史不平等、不对称的权力等级制度或渗透到数据实践中的未经审查的问题假设的问题。”
这可能是量化方法的最大缺点。通过满足公平的某些数学定义,我们说服自己已经解决了问题。然而,这可能会忽略公平的细微差别。它也无助于解决不公平的根本原因。这并不是说量化方法没有用。它们将成为解决方案的一部分。然而,要完全解决不公平问题,我们需要额外的非量化方法。
非定量方法
在本节中,我们将讨论其中一些方法。您可以在图 5 中看到这些方法的概述。其中大多数方法要求数据科学家远离计算机,以更广阔的视角看待公平性。成功实施这些方法也需要非技术技能。
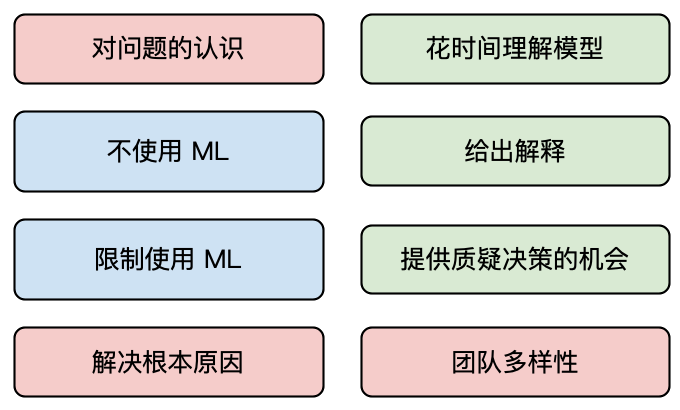
意识到问题
数据科学涉及技术工作。我们整天都在看数字、代码和屏幕。我们很容易忘记我们建立的模型会影响真实的人。更糟糕的是,有些人甚至不知道模型会导致不公平的结果。要解决不公平问题,我们首先需要了解并接受机器学习的潜在负面影响。
首先,我们需要了解不公平模型的原因。我们已经提到了其中一些原因。它们包括代理变量、倾斜的数据集和数据中嵌入的历史不公正。不公平也可能来自我们的算法选择或用户与模型的交互方式。我们在文章《机器学习中的 5 种常见偏见来源》中更深入地讨论这些问题。
然后,我们需要进行彻底的公平性分析。这是为了了解上述原因的普遍程度。将这种分析扩展到数据和模型之外也很重要。模型可能会拒绝或接受贷款申请。我们可以用 1/0 量化这些并计算公平指标。然而,这隐藏了我们模型的真正后果。拒绝可能会导致企业破产或学生无法上大学。
只有充分了解不公平的风险,我们才能做出适当的决定来减轻这些风险。这样做可能需要数据科学家改变对自己角色的看法。它不再是纯粹的技术,而是影响真实的人。
不要使用机器学习
我们必须承认,机器学习并不是解决所有问题的良方。即使可以使用,也可能导致不公平的结果。机器学习还有许多不可接受的用途——例如,使用面部识别预测犯罪行为。这意味着最好的解决方案可能是根本不使用机器学习。我们不会自动化某个流程。相反,人类将负责任何决定。
选择这条路线时,您需要考虑所有成本。一方面,人类做出决策可能代价高昂。另一方面,有偏见的模型可能会给用户带来重大负面影响。这可能导致信任丧失和声誉受损。这些风险可能超过自动化流程的任何好处。对这些风险的理解将来自上述公平性分析。
限制机器学习的使用
很有可能,如果你已经努力构建了一个模型,你就会想要使用它。因此,你可以限制模型的使用方式,而不是完全丢弃它。这可能涉及对机器学习做出的决策应用某些手动检查或干预。最终,我们将使用模型来仅部分自动化流程。
例如,模型可以自动拒绝或接受贷款申请。相反,我们可以引入一个新的结果——推荐。在这种情况下,申请可以由人工手动检查。推荐申请的过程可以设计为减少不公平结果的影响。这些应该旨在帮助那些最脆弱的人。

解决根本原因
数据不公平是现实的反映。如果我们解决真正的根本问题,我们也可以解决数据中的问题。这将需要公司或政府政策的转变。这也意味着将资源从量化方法中转移出来。这将需要更广泛的组织甚至整个国家的合作。
例如,假设自动化招聘流程导致女性被聘用人数减少。我们可以通过鼓励更多女性申请来帮助解决这个问题。公司可以通过广告活动或让其环境成为女性更好的地方来实现这一目标。在国家层面,可以通过加大对女性 STEM 教育的投资来实现这一目标。
花时间理解模型
模型可解释性对于公平性至关重要。可解释性涉及理解模型如何进行预测。这可以是整个模型(即全局解释)。这是通过查看多个预测的趋势来实现的。这使我们能够质疑这些趋势并确定它们是否会导致不公平。
它还意味着了解模型如何做出个别预测(即局部解释)。这些告诉我们哪些模型特征对特定预测贡献最大。这使我们能够判断模型是否导致特定用户产生不公平的结果。
可解释性要求我们优先考虑理解而不是性能。我们可以使用本质上可解释的模型(如回归或决策树)来实现这一点。这些可以通过查看模型参数直接解释。对于非线性模型(如 xgboost 或神经网络),我们需要模型无关的1方法。一种常见的方法是 SHAP2,日后会撰写相关文章中介绍。
给出解释
模型预测可能会给用户带来严重后果。考虑到这一点,他们有权要求对这些预测作出解释。解释可以主要基于局部解释。也就是说,我们可以解释哪些特征对影响用户的预测贡献最大。
重要的是要理解解释和说明不是一回事。解释是技术性的。我们查看模型参数或 SHAP 值。说明是向非技术受众提供的。这意味着以一种可以理解的方式给出它们很重要。我们需要在日后的文章中仔细分析解释预测的作用和艺术。
解释还可以超越功能贡献。我们可以解释决策过程自动化的程度。我们还可以解释该过程中使用了哪些数据以及我们从哪里获得这些数据。解释的这些方面可以由法律或客户需求来定义。
提供挑战决定的机会
一旦用户得到解释,他们就可以决定它是否合理。如果他们认为它不合理,他们必须被允许质疑这个决定。赋予用户这种决策权力对于打击不公平至关重要。这意味着不公平的决定更有可能受到质疑和纠正。
这又回到了限制使用机器学习的问题上。我们需要制定程序,允许至少部分决策可以手动做出。就像我们的贷款模型示例一样,决策可以提交给贷方,而不是自动拒绝。申请人能够控制这一过程非常重要。
我们也可以回想一下我们的量化方法。像 DIR 这样的方法会增加复杂性并对可解释性产生负面影响。这会使给出人性化的解释变得更加困难。换句话说,通过影响解释,一些量化方法可能会对公平性产生负面影响。
团队多元化
数据是我们做出有效决策的最佳工具。然而,正如前面提到的,它可以隐藏机器学习的真正后果。我们的生活经历可以更好地说明这一点。这些经历与我们的文化背景有关。这就是我们体验世界的方式,而技术取决于我们的性别、种族、宗教或原籍国。这使得从不同的人群中获得对我们的机器学习系统的反馈变得非常重要。
聘请多元化的团队也很重要。这些人将真正构建模型和系统。这样做将带来一系列不同的生活经验。他们都将了解系统将如何影响他们自己的生活。这将使他们更容易在部署模型之前识别潜在的公平问题。

多样性还意味着聘用具有不同专业领域的人员。正如我们所提到的,要解决不公平问题,我们需要超越定量方法。换句话说,我们需要大多数数据科学家不具备的技能。团队的关键成员将是人工智能伦理方面的专家。他们将对我们上面概述的非定量方法有更深入的了解。然后,数据科学家将能够专注于定量方法。
希望这篇文章对您有所帮助!您可以通过后买「企业 AI 项目实战」来进行级数进阶,并以此来支持我。实战教程将助力您尽快上手企业实际的 AI 项目。
参考
Birhane, A., (2021) Algorithmic injustice: a relational ethics approach. https://www.sciencedirect.com/science/article/pii/S2666389921000155
Pessach, D. and Shmueli, E., (2020), Algorithmic fairness. https://arxiv.org/abs/2001.09784
Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K. and Galstyan, A., (2021), A survey on bias and fairness in machine learning. https://arxiv.org/abs/1908.09635
Feldman, M., Friedler, S.A., Moeller, J., Scheidegger, C. and Venkatasubramanian, S., (2015), Certifying and removing disparate impact. https://dl.acm.org/doi/pdf/10.1145/2783258.2783311
Bechavod, Y. and Ligett, K., (2017), Penalizing unfairness in binary classification. https://arxiv.org/abs/1707.00044
Lo Piano, S., (2020). Ethical principles in machine learning and artificial intelligence: cases from the field and possible ways forward. https://www.nature.com/articles/s41599-020-0501-9
Smith, G., (2020). What does “fairness” mean for machine learning systems? https://haas.berkeley.edu/wp-content/uploads/What-is-fairness_-EGAL2.pdf
Google, (2022), How Inclusive Data Builds Stronger Brands https://www.thinkwithgoogle.com/feature/ml-fairness-for-marketers/#what-we-learned
纠正和防止机器学习中的不公平现象

