04. BI - LightGBM vs CatBoost,具体实现分析

[TOC]
Hi,你好。我是茶桁。
那今天我们是来讲解另外两个 Boosting 的工具,首先是微软出品的 LightGBM。
LightGBM
LightGBM 是微软提出来的, 是属于 XGBoost 的升级版,也曾经是 Kaggle 里面使用模型最多的机器学习的神器。当然,目前 LightGBM 之外,BERT 以及 GPT 都越来越受关注,但是 LightGBM 这么久了,依然还是占据一席之地,依然还是某些性质及任务要求下的首选。
Light 的概念就是轻和快,GBM 全称为 Gradient Boosting Machine,这个 GBM 就把它理解成就是 GBDT,所以它其实就是轻量级的 GBDT,而且是升级版本。所以我们看一看,它到底做了哪些轻量级的一些操作。
常用的机器学习算法,例如神经网络等算法,都可以以mini-batch的方式训练,训练数据的大小不会受到内存限制。
GBDT 在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小,如果不装进内存,反复地读写训练数据又会消耗非常大的时间。对于工业级海量的数据,普通的 GBDT 算法是不能满足其需求的。
LightGBM 的提出是为了解决 GBDT 在海量数据遇到的问题,让 GBDT 可以更好更快地用于工业场景。
我们看整个的例子,先让大家有个直观的感受。
我找了四个数据集,然后用 XGBoost, XGBoost_approx 以及 LightGBM 来做一个比较. 其中 XGBoost_approx 是 2016 年左右提出来的 XGBoost 的近似版.
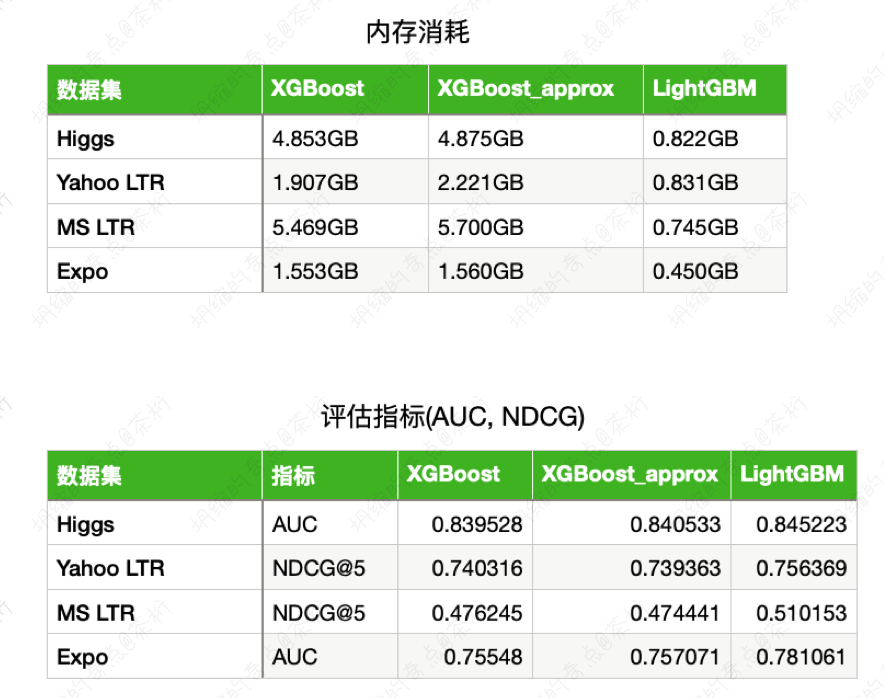
一共做了两种对比,一种对比是它的内存消耗,看谁的内存占用更小。可以看到 LightGBM 明显比 XGBoost 的内存会更小一点。同样的数据集只有大约 1/6 左右。
指标除了内存以外还是要关注一下评价结果,结果上 LightGBM 和 XGBoost 差别并不大,甚至有些情况下还会更好。所以在结果差别不大的情况下,内存只有原来的 1/6.
除此之外,训练速度上还做了一个对比
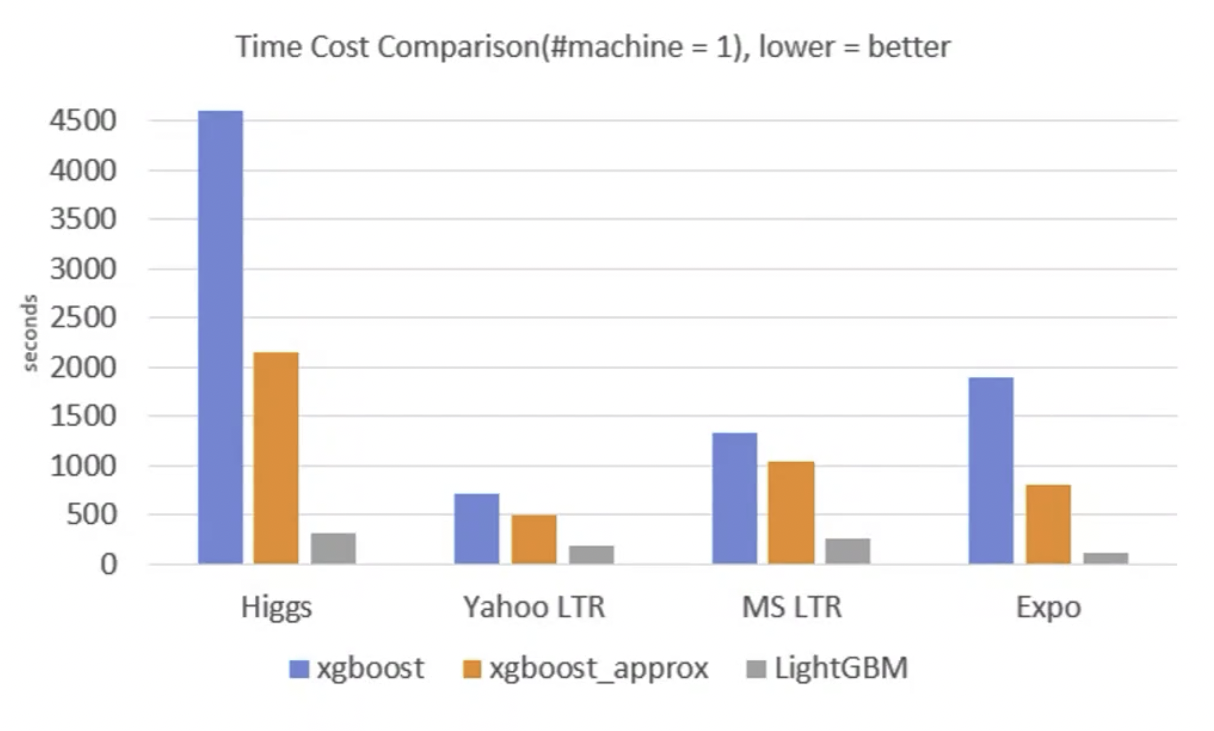
这里seconds代表的是时长,这四种训练集里面,XGBoost 的
2016 版比原来 2014
版速度要快,因为它是近似方法,还记得上节课说的直方图吧?LightGBM
明显还比它所有的这些版本都要快,大概快了有 1/10。
所以我们用了 1/10 的速度,用了 1/6 的内存,得到了一个还不错的结果,这两个模型也比较相当。这两个模型还可以帮我们来自动处理一些特征的确认值,XGBoost 是不支持类别特征的,而 LightGBM 支持类别特征。
那么问题来了, 为什么 LightGBM 会更快呢?
让我们稍微拆解了一下模型复杂度的流程
\[ 模型复杂度 = 树的棵数 \times 每颗树的叶子数量 \times 每片叶子生成复杂度 \]
树的个数越多就会越复杂,每棵树的叶子的数量越多应该也越复杂。然后再乘上每个叶子节点的生成的复杂度,这个生成的复杂度又会等于特征数量乘上候选的分裂点的数量以及样本的数量。
LightGBM 看到的这样的一个特点,就想要从这三个维度做一些简化。
第一个简化,减少分裂点的数量。采用 Histogram 算法。
这个其实跟 2016 年的版本是完全一致的。采用了直方图的方式先减少分类节点数量。
然后第二个,GOSS 算法。
这个方法基于梯度的单边采样算法,减少了样本的数量。
还记得上节课咱们使用 XGBoost 时给大家讲的 subsample 吗?XGBoost 里面用的是 0.5,比如原来是有 1 万个样本就用 50%,也就是说只用了 5,000 个样本来进行训练。如果是随机的选择 5,000 个样本来做训练,对于精度来说是有损失的。目的是希望更快,但是会损失一定的进度。
第三, EFB 算法。
它使用互斥特征捆绑算法,减少特征的数量。原来有 100 个特征,现在随机抽取 80 个特征,对精度也是有一定损失。
XGBoost 的预排序( pre-sorted )算法是将样本按照特征取值排序,然后从全部特征取值中找到最优的分裂点位。预排序算法的侯选分裂点数量 = 样本特征不同取值个数减 1。
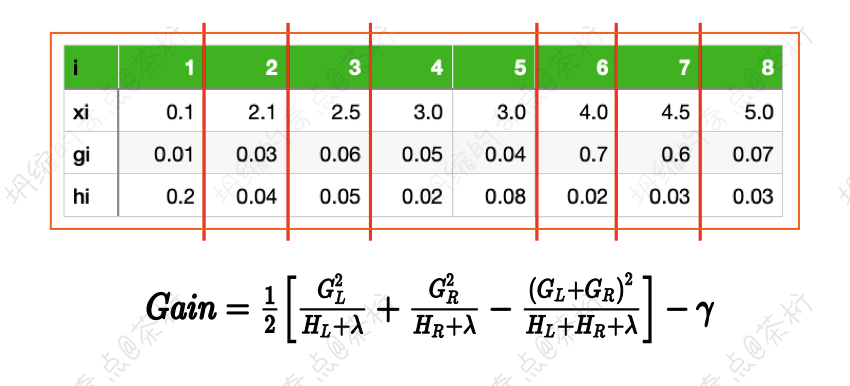
这是一个排序的方法,我们可以按照切分的方式来进行一个顺序的切分。原来的切分的方式每一个地方都可以进行切分,而现在分成了三个桶,就只有两种切分的方法, 如下:
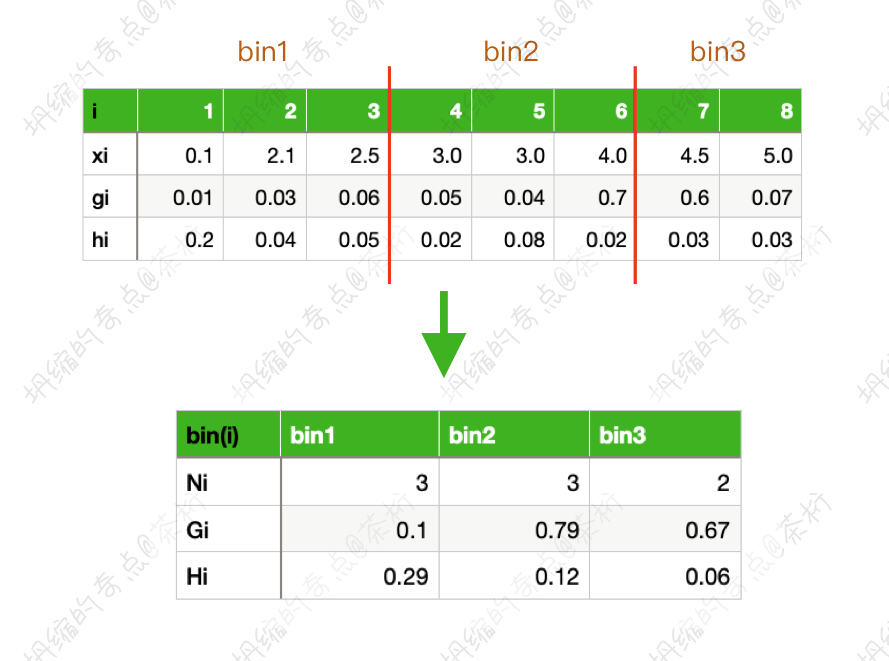
这样每一个桶就当成了一个整体和一个集合,相对来说,分裂节点的数量就减少了。这种方式其实就是 Histogram 算法,2016 年的 XGBoost 就是采用的这种算法。这种方式替代了 XGBoost 原先的 pre-sorted 算法。
因为做了合并,原来是三个样本的gi,
现在变成了一个Gi。Gi是求和,这里的Gi就把三个里面一阶导数的梯度做为个累加,就等于0.1。Hi二阶梯度相加就等于0.29。这样就是第一个桶的一个特征,合并以后
Histogram
变成了三个样本。整体的一阶导数是0.1,二阶导数是0.29,以它来完成运算。
第二个桶也有三个样本,一阶的导数之和是0.79,二阶导数之和是0.12。第三个桶是两个样本,一阶和二阶导数分别是0.67和0.06。
那么未来做分割的时候,我们就只要在这个基础上来做分割就好了。因为它前面已经合并成了一个整体,这种方式候选的节点的数量变成了
桶的个数-1 ,也就是k-1。
它的思想就是连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图,即将连续特征值离散化到k个bins上。当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
XGBoost 是需要遍历所有离散化的值,LightGBM 就只需要遍历 k
个直方图的值。其侯选分裂点数量就等于k-1。
除了这种方法以外,LightGBM 还有两种优化策略。GOSS
算法的全称是Gradient-based One-Side Sampling,
基于梯度的单边采样算法。
刚才是用 subsample ,XGBoost
里面专门有一个参数,可以把它设成0.5,也就是
50%,它会有精度的下降,会有损失。
那我们现在来思考一个问题,样本的梯度是大好还是小好呢?我们在机器学习过程中是通过什么来去更新我们的参数?
机器学习有一种方式叫做梯度下降,梯度下降证明了你学习的方向。如果方向梯度越大,就代表我学习方向越明确。如果梯度已经变成了0.00001,就不好学习到内容。所以对于样本的梯度来说,其实希望它大一点好,可以持续降低。梯度越大就证明学习方向是非常明确的,更容易学到内容。
GOSS 方法它想到,之前 50% 随机采样,舍弃了
50%,如果舍弃的是那些梯度比较大的样本在精度上更容易有损失。所以 GOSS
就希望先保留那些梯度大的样本,给它设了一个阈值。比如说图例中阈值设为
0.1,梯度大于0.1我们就全部保留,因为这些样本它是属于好的样本。
好样本的梯度怎么理解?
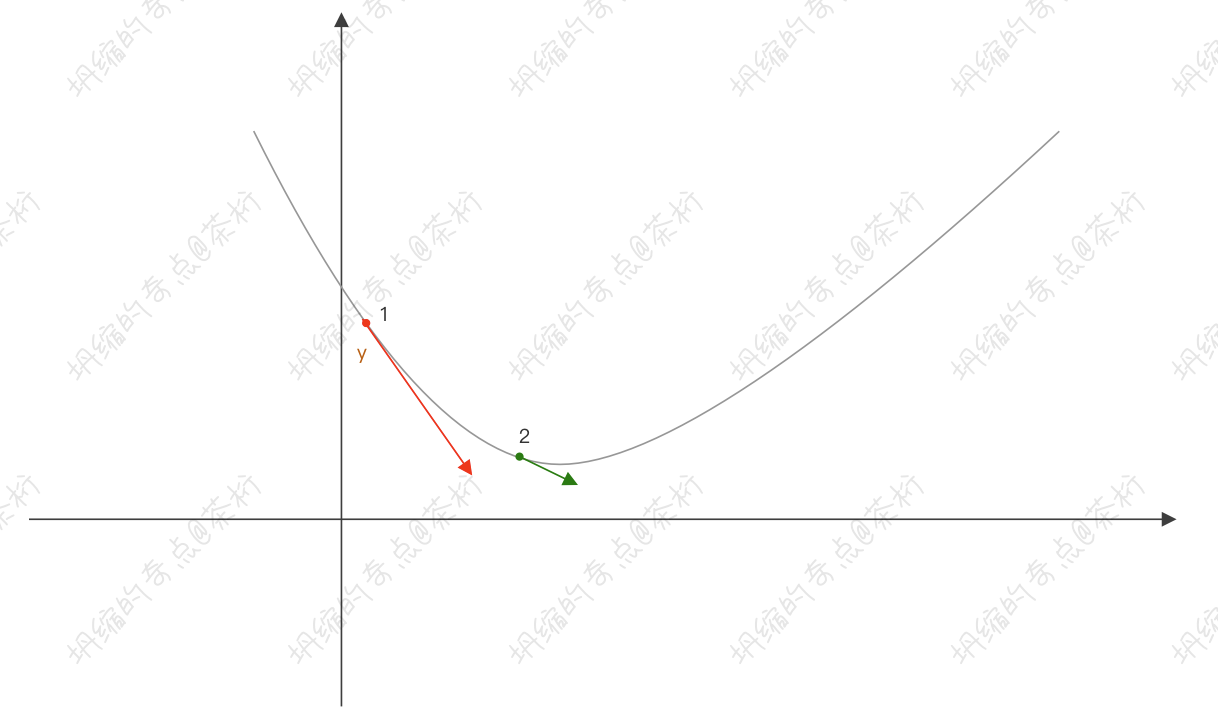
我们来看这张图,红色的点是一个样本点。我们的样本在这里,预测出来的值是
\(y'\),实际值是 \(y\)。所以它们之间是有一个方向,\(y\) 和 \(y'\) 之间有个方向。用 MSE
的话,我们都知道 \(MES = (y' -
y)^2\),所以它的梯度就代表了是我要学习下降的一个方向。如果方向越明显其实就更容易去前进,我们再看绿色的点
2,其实在后面已经不容易学到内容了。点 1
明显梯度会更大一点。
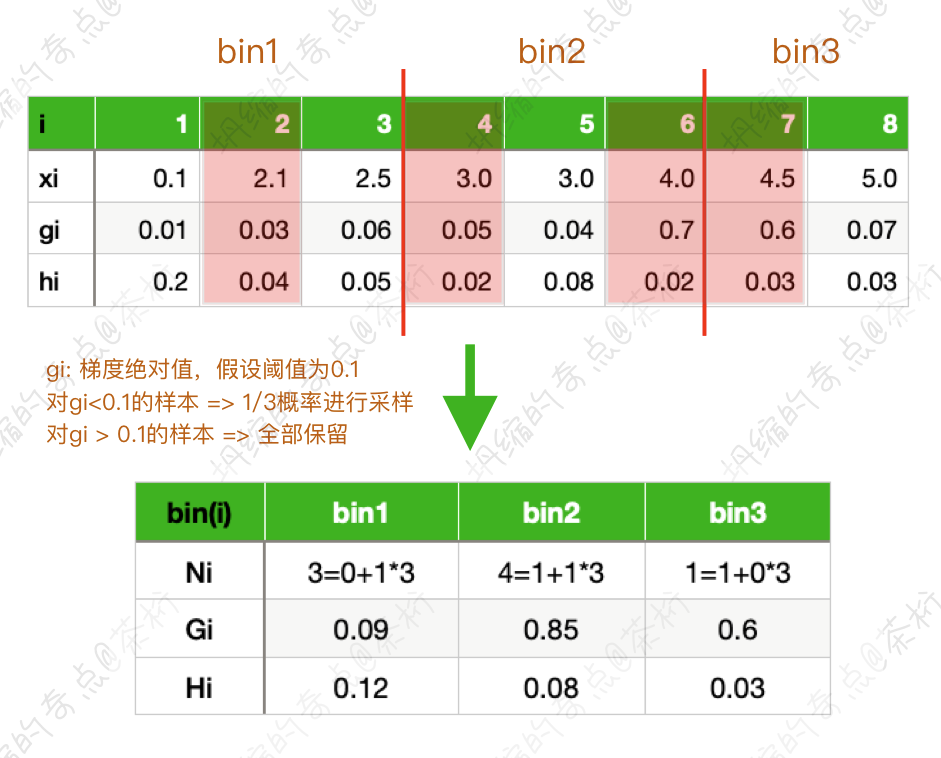
回到上面那张数据的图上,6 和 7
的的gi一个是0.7,
一个是0.6,都大于0.1,所以这两个是必须要留下来,因为它还没有学好。剩下的小于0.1的样本,我们就保留了
1/3。这是一个随机性的,假设现在选中的是2,
4这两个。因为8减去6,7之后还剩下六个样本,六个样本里面的
1/3,就是保留两个,我们随机保留了 2 和 4。
最后结果是我们也保留了 50% 的样本进行采样,但是这 50% 是使用了 GOSS 算法计算之后的结果。
前面的直方图我们是已经计算好了的,所以有三个bin。对于第一个bin的计算,
做了1/3的采样,
选中的2。可以想成是人大代表,代表 3 个人。因为是从 3
个人里面选举出来的这一个人作为代表,这也是 3 个人的情况。
那么对于第一个桶来说,里面只抽出来了样本
2,2 是一个代表,所以它相当于是 \(1 \times 3\),3 个样本。样本 2
的gi原来是 \(0.03\),它的代表相当于是 \(0.03 \times 3\),hi 是
0.04,同理就是 \(0.04 \times 3 =
0.12\)。
那对于第二个桶,是一样的计算方法。6
是全部保留,4 代表了 3 个,所以是 \(1 \times 3\) 个,那就是 \(1+1\times 3\)。Gi 就是
6 加上 4 乘 3, 那就是 \(0.7 + 0.05 \times 3 =
0.85\)。Hi 也是一样的算法,\(0.02+0.02 \times 3 = 0.08\)。
那最后一个桶,bin3 里也是这么计算得来的。
GOSS 算法的思想是通过样本采样,减少目标函数增益 Gain
的计算复杂度。单边采样,只对梯度绝对值较小的样本按照一定比例进行采样,而保留了梯度绝对值较大的样本。因为目标函数增益主要来自于梯度绝对值较大的样本
=> GOSS 算法在性能和精度之间进行了很好的权衡。
那最后,LightGBM 内还包含了一个 EFB
算法。刚才咱们的采样可以理解为行采样,就是从 10,000 个样本减到 5,000
个采样, EFB 是列采样。 EFB
其实是互斥特征绑定法,Exclusive Feature Bunding。
机器学习过程中,有的时候会用 one-hot 编码把类别特征转化成为
0-1 特征。 one-hot 就是将你要的特征变为
1,其它变为0。比如说,在一个星期中,我要星期三,那么这组特征就会变成
0010000。
如果用了 one-hot 编码会出现大量稀疏特征。什么叫稀疏,0
代表没有,大量为 0 的叫稀疏。这个过程放眼望去肯定是
0 多,0 代表空,1
代表有价值有数据,所以它是大量的稀疏特征。
EFB 就发现了这样的一个逻辑:XGBoost 有很多人提前做了 one-hot 编码,就会有大量稀疏特征。那能不能把这个大量稀疏特征给它合并到一起?这也就是 EFB 的思想。特征中包含大量稀疏特征的时候,减少构建直方图的特征数量,从而降低计算复杂度。
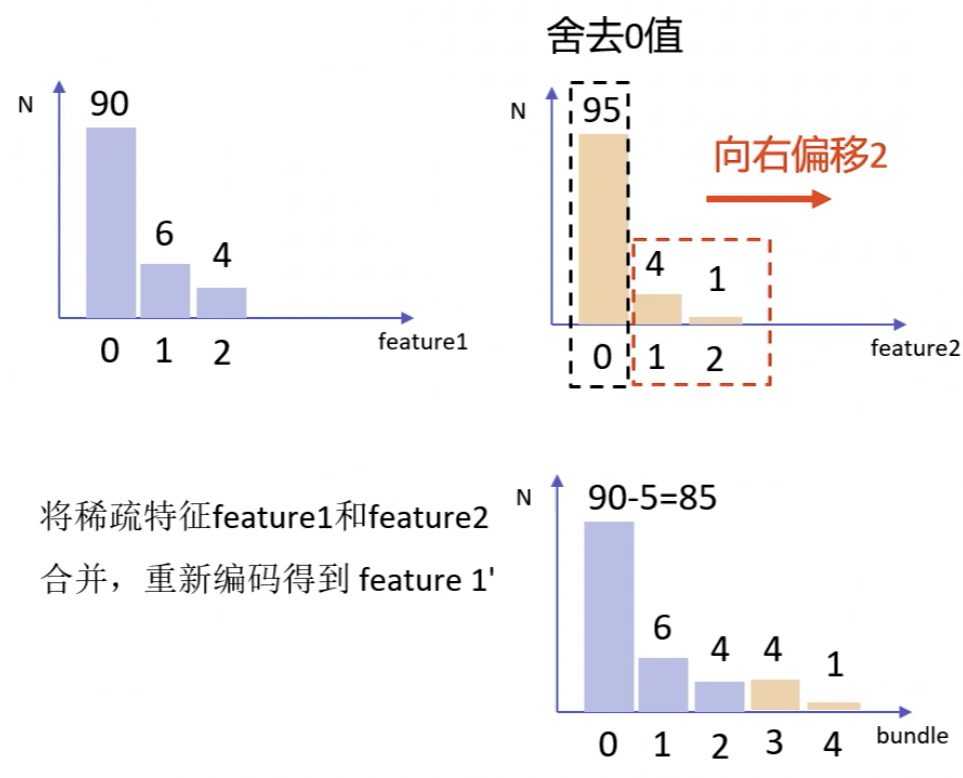
比如说第一个 feature,0
这个代表为空没有含义,1 和 2 有 10
个值,这是有价值的。
第二个特征也是一个稀疏特征,有 95 个是没有的意义,只有 1
和 2 是有价值的。
那作者就想到,能不能把 1 和 2
这两个特征合并成一个新的特征,叫 feature 1'。怎么合并?首先
feature 1 里的 1 和 2
依然把它作为 1 和 2 , feature 2
里的 1 和 2 跟 feature 1 里的
1 和 2
不是一个概念,所以我们要把它做一个新的编码,把它称为 3 和
4 。这里的 3 对应出来是原来
feature 2 里的 1 , 4 对应的是
feature 2 里的 2 。
原来 feature 1 里面是有 100 个特征的,现在增加了
3和4 ,一个是 4 个,一个是 1 个,所以匀了 5
个特征给后面补进来的部分,整个特征数是不能变的,所以最前面的
0 特征,就从 90 个里面减去了 5 个,变成了 \(90-5 =
85\)个。这样就把两个特征列合二为一变成一个新的特征列,而且精度没有损失,因为把原来的做成一个等价的还原。
如果用 EFB 方法把两个特征捆绑到一起合成一个新的特征,这个特征没有损失,是可以完全唯一的还原。因为它能发现有大量 one-hot 稀疏特征很容易进行合并,合并之后就可以让特征的数量大大减少,就不需要用刚才说的设置 100 自动的抽 80 列,那样其实信息是有损失的,但是 EFB 不会有损失。
LightGBM 的使用
LightGBM
的用法也是从引入包开始import lightgbm as lgb,其参数也基本上差不多,我们来看下:
boosting_type,训练方式,gbdtobjective,目标函数,可以是 binary,regressionmetric,评估指标,可以选择 auc, mae,mse,binary_logloss, multi_loglossmax_depth,树的最大深度,当模型过拟合时,可以降低 max_depthmin_data_in_leaf,叶子节点最小记录数,默认 20lambda,正则化项,范围为 0~1min_gain_to_split,描述分裂的最小 gain,控制树的有用的分裂max_cat_group,在 group 边界上找到分割点,当类别数量很多时,找分割点很容易过拟合时num_boost_round,迭代次数,通常 100+num_leaves,默认 31device,指定 cpu 或者 gpumax_bin,表示 feature 将存入的 bin 的最大数量categorical_feature,如果 categorical_features = 0,1,2, 则列 0,1,2 是 categorical 变量ignore_column,与 categorical_features 类似,只不过不是将特定的列视为 categorical,而是完全忽略
Bagging 参数:bagging_fraction + bagging_freq(需要同时设置)
bagging_fraction,每次迭代时用的数据比例,用于加快训练速 度和减小过拟合bagging_freq:bagging 的次数。默认为 0,表示禁用 bagging,非零值表示执行 k 次 bagging,可以设置为 3-5feature_fraction,设置在每次迭代中使用特征的比例,例如为 0.8 时,意味着在每次迭代中随机选择 80%的参数来建树early_stopping_round,如果一次验证数据的一个度量在最近的 round 中没有提高,模型将停止训练
那我们比较常见的参数配置如下:
1 | |
现在咱们还是用之前员工离职预测的来做一个代码示例,在进行模型训练的时候,这里有一个和
XGBoost 类似的地方,之前 XGBoost
用的是自己的数据结构DMatrix,在 LightGBM 里也有一个
Dataset,也是几乎一样的用法,除了用官方的 Dataset
方式进行封装之外,训练的时候要用 train 来进行训练,
那这是一个官方的版本,不过我们这里用 sklearn
提供的版本来使用。为什么要用它而不是官方版本,这是因为 sklearn
的参数名称都比较统一,比如说我们的机器学习里面有个参数都叫
n_estimators, 而官方的 XGBoost 和 LightGBM 都称作
num_boost_round。为了和其他机器学习方式统一避免麻烦,所以我建议大家还是使用
sklearn 里的方式来使用。
那我们这次为了看 LightGBM 的实际效果,还是使用官方的方法:
1 | |
训练好之后,来看看结果:
1 | |

CatBoost
后面还有一种方法叫 CatBoost。https://arxiv.org/pdf/1706.09516.pdf
这个方法只要知道它的一个大概使用情况就好。cat 不是猫,应该叫做 catgorical,就是分类的概念。所以它是专门针对分类特征多的情况下提出来的 boosting 的算法。这个方法不一定效果好,但是它有可能对于分类特征多的数据集有奇效,所以你可以把这个方法作为一个备选,也可以尝试着去用一用,尤其是分类特征比较多的情况。
这里有一个数据集,是 kaggle 上的一个数据集。2015 年航班延误数据,包含分类和数值变量:https://www.kaggle.com/usdot/fight-delays/data。这个数据集大约有 500 万条记录,使用 10% 的数据,即 50 万条记录。
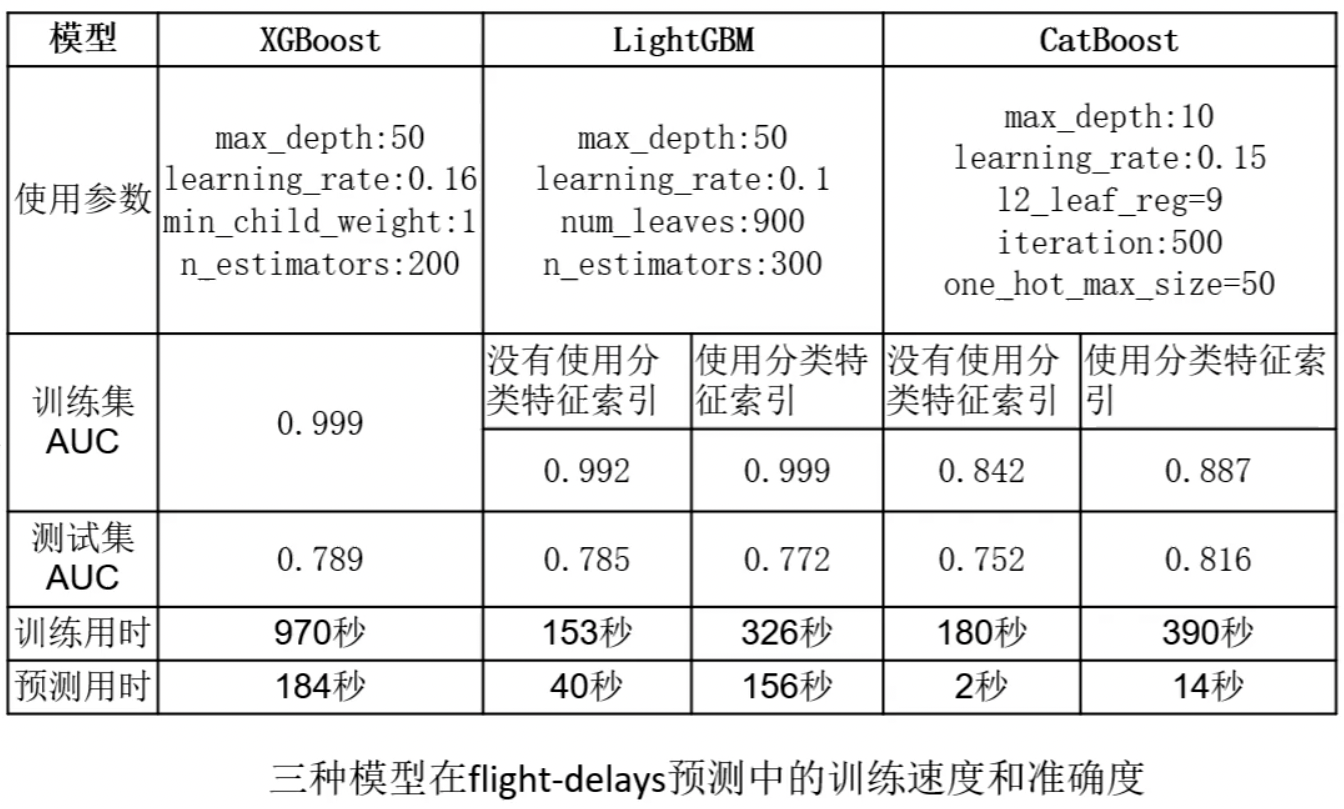
这里有 XGBoost,LightGBM 和 CatBoost, 我们可以看一下大家可以看一看,XGBoost 和 LightGBM 训练集非常好,但是测试集差很多,这种我们都知道,就是过拟合了。
但是 CatBoost 对于这个航班延误的数据集的训练结果是 84%、88%,测试结果跟它相差不是很大,相比于 XGBoost 和 LightGBM 来说,CatBoost 的过拟合程度是最小的,这是它的特点。此外时间最快是 LightGBM,其次是 CatBoost,最后是 XGBoost。
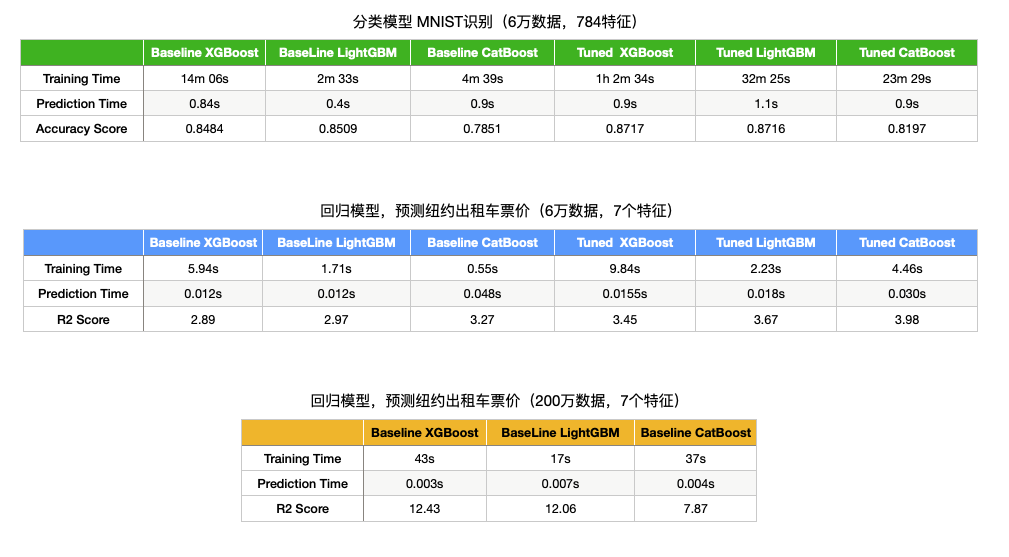
这三种模型我们还对比了一下精度,还是来先看训练时间,最快的依然是 Light, Cat 次之,最慢的依然是 XGBoost。那从训练的精度上来看,XGBoost 和 LightGBM 差不多,但是 Cat 稍微差一点。不过不要认为 CatBoost 就不行,就如之前说的,在一些特殊的分类特征更多的情况下,CatBoost 的表现反而是最好的那一个,当然,80%以上的情况下,它的效果都会较差一点。
CatBoost 的使用
CatBoost 工具的 Github 地址: https://github.com/catboost/catboost,还有 https://catboost.ai/en/docs/
我们还是可以直接调包去使用,它的模型包跟前面的模型包基本上差别也不是很大。
构造函数:
learning_rate,学习率depth, 树的深度l2_leaf_reg,L2 正则化系数n_estimators,树的最大数量,即迭代次数one_hot_max_size,one-hot 编码最大规模,默认值根据数据和训练环境的不同而不同loss_function,损失函数,包括 Logloss,RMSE,MAE,CrossEntropy,回归任务默认 RMSE,分类任务默认 Loglosseval_metric,优化目标,包括 RMSE,Logloss,MAE,CrossEntropy,Recall,Precision,F1,Accuracy,AUC,R2
fit 函数参数:
X,输入数据数据类型可以是:list; pandas.DataFrame; pandas.Seriesy=Nonecat_features=None,用于处理分类特征sample_weight=None,输入数据的样本权重logging_level=None,控制是否输出日志信息,或者其他信息plot=False,训练过程中,绘制,度量值,所用时间等eval_set=None,验证集合,数据类型 list(X, y)tuplesbaseline=Noneuse_best_model=Noneverbose=None
那对于员工离职预测这个问题,我做了一版,大家可以看我下面的代码自己进行尝试:
1 | |
然后:
1 | |
好,那到这里,关于 Boosting 的几种工具就都给大家介绍完了,来简单总结一下,这三种工具,LightGBM 效率是最高的,在 Kaggle 比赛中应用多, CatBoost 对于分类特征多的数据,可以高效的处理,过拟合程度小,效果好。XGBoost,LightGBM 和 CatBoost 的参数都比较多,调参需要花大量时间。 Boosting 集成学习包括了 AdaBoosting 和 Gradient Boosting, 那 Boosting 就只是集成学习中的一种,还有 Bagging 和 Stacking。
最后留一些问题啊给大家去思考一下,那这些问题大家最好自己去梳理一下,然后写上自己的答案,把你的答案写到本文留言框里,我们来看看谁梳理的最好。
- Thinking 1: XGBoost 与 GBDT 的区别是什么
- Thinking 2: XGBoost 与 LightGBM 的区别是什么
那除此之外,还有一个问题
- Thinking3:举一个你之前做过的预测例子(用的什么模型,解决什么问题,比如我用 LR 模型,对员工离职进行了预测,效果如何... 你可以在下面留言来说一下。)
那我们要做的题目:Action1,用我之前给大家使用过的:男女声音识别的数据集: voice.csv
链接: https://pan.baidu.com/s/1UgXmDZLOpVeXz21-Ebddog?pwd=5t4e 提取码: 5t4e --来自百度网盘超级会员 v7 的分享

这个数据集中有 3168 个录制的声音样本,采集的频率范围是 0hz-280hz, 已经对数据进行了预处理。
一共有 21 个属性值,请判断该声音是男还是女。
最后,使用 Accuracy 作为评价标准。
那我们之前在 BI 第二课的时候用的是 SVM 的方法进行预测,在这个 Action1 中,大家试试用 XGBoost 和 LightGBM 的方式来进行。
那这个 Action1 就是留给大家的一个实操作业,可以去我的代码库中找相关的示例,但是我还是希望大家能自己去做一下,不要一上来就去看参考。
04. BI - LightGBM vs CatBoost,具体实现分析

