计算机视觉的常用模型
本节课为「计算机视觉 CV 核心知识」第 14 节;
「AI秘籍」系列课程:
可直接在橱窗里购买,或者到文末领取优惠后购买:

Hi,大家好。我是茶桁。
上节课我们把第二部分的作业讲了一下,作业是要对 10 张图片进行分类。我希望大家把这个提特征和决策部分好好的写一下,从而体会一下传统的计算机视觉的一般流程。
就上节课咱们讲解完课程作业之后,我们第二部分《认识计算机视觉》算是结束了。从本节课开始,我们要进行第三部分《GPU 如何在 LeNet 提升中发挥作用》的讲解。
在整个第三部分中,我们就来看一下传统的图像处理和计算机视觉是如何过渡到 CNN 的,如何过渡到深度学习。
过渡到深度学习的时候我们会讲一个模型,LeNet,LeNet 讲完之后我们再讨论一下,在 LeNet 基础上如何去提升模型的性能。在 LeNet 基础上如何使深度学习模型精度和速度进行加速。
第三部分中,我们就给大家介绍一下计算机视觉的常用模型,包括机器学习的模型,也包括深度学习的模型。介绍这个主要是告诉大家有哪些模型。
CNN 实际上是统一了提特征与决策。这部分就会最后引入到 LeNet,会讲解 LeNet 是如何统一了提特征和决策这两个步骤。
我们都知道,提特征和决策这两个步骤是我们传统的计算机视觉的两个步骤。之前课程中讲了这两个步骤,之后我们就讲这两个步骤的统一。所以大家现在就可以想一下,究竟这个「统一」二字指的是什么。对于提特征和决策的统一,这个「统一」到底指的是什么。为什么我们说 CNN 是「统一」了这两个步骤。
那么 LeNet 讲完之后,我们就想办法去提升 LeNet 的性能。提升的方法有很多种,有从算法的角度去考虑的,也有从硬件的角度去考虑的。我们就先 从算法的角度去考虑,这个思路说一下。然后再讲一下从硬件的角度去考虑。
从硬件的角度去考虑就是用 GPU 去提升 CNN 的运行速度,从而提升 CNN 的性能。所以说,我们要把 GPU 的基本的结构介绍一下,然后最后再介绍一下 pycuda。
关于 CUDA,我也写过一些系列文章,大家可以去这里看看:Numbda 的 CUDA 示例
pycuda 就是我们现在常用的 GPU Python 接口。我们可以通过 pycuda 这个库直接的去操作 GPU 的线程,使用 GPU 对图像矩阵进行操作非常方便。可以看到直接使用 GPU 对图像矩阵进行操作的时候,每个像素是如何操作的。
我们原来使用 GPU 必须是通过 PyTorch, Tensorflow 等一些框架去使用的,那么我们通过 pycuda 就可以直接去使用 GPU 了,直接去调用 GPU 的一些API,GPU 的一些驱动函数。
那么最后 pycuda 这一部分,这个包主要是有些例子。
然后我们最后是讲一个 pycuda 完成矩阵乘法的一个例子,矩阵乘法如何用 pycuda 去实现。
咱们继续从上一节课的作业开始讲起吧。在上节课作业中,我们最后是要做判断的。实际上我们还有更多的 model 可以去用的,比如说以下这些:
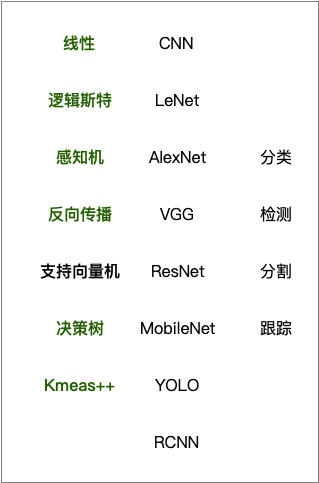
实际上我们可以用所有的这些模型。
比如说,我们可以用线性模模型。线性模型还记得吗?是否还记得线性模型的公式?
第一列的这些模型在机器学习部分我们应该是接触过一些模型,有兴趣的可以看看我的核心课程《茶桁的 AI 秘籍-核心基础》,这里面应该是都讲过。
所以说在咱们作业的决策部分就可以用这些模型,用任意一个模型都可以。自己写或者用工具箱都可以。自己写当然要求可能比较难一点,因为你要自己去写优化算法,写求解方法,你要写训练。
我相信有不少同学都可以做的,我出的那个作业其实是相对还是非常简单的。
那么后续课程我们陆续中间这部分的模型,包括 CNN, LeNet, AlexNet, VGG, ResNet, MobileNet, Yolo, RCNN,一些主要的模型。Yolo 系列是个全家桶。
当然还有分割的模型 FCN/UNet,大概就围绕这种经典的模型来讲。
那么第三部分中我们会把 LeNet 讲了,之后的部分我们会讲其他模型。Yolo 和 RCNN 都是目标检测类,这个我们花费的时间会长一点,大概算下来应该是平时两部分的内容。像 AlexNet, VGG, ResNet 我们都会放在一个部分的长度里去讲,看课程内容情况,我们会决定是否讲一下 MobileNet。
在讲解这些模型的过程中,咱们不会给你讲论文或者单独只是讲模型,咱们讲的时候会讨论一下如何去涉及分类模型。也就是说,我们在 LeNet 基础上如何去提升它的性能,AlexNet 模型做了什么创新,在 LeNet 基础上做了些什么事情,然后成了 AlexNet。
AlexNet 之后 VGG 又做了什么,它比 AlexNet 性能好很多,为什么,它做了什么实验。VGG 模型为什么又不能做到更深,VGG 模型为什么到 22 层就没有更深了,为什么没有做 26 层、28 层。
所以后面就引出了 ResNet。ResNet 的这个残差网络设计的非常巧妙。
我们发现 ResNet 是 15 年、16年左右的,看完 ResNet 之后,我们现在是 24 年了,这小 10 年都过去了,我们发现现在还仍然大量在用 ResNet。
VGG,AlexNet 以及 LeNet 都已经用的很少了,我们还在用 ResNet。即便是现在有注意力机制,我们还在用它。所以说 ResNet 是一个非常需要掌握的一个模型。
并且我发现大量的一些从业的人员 ResNet 还有一些误解,一些概念上还不太清晰。所以说 ResNet 之后,大家就认为这个模型的性能可能产业上已经够用了。所以有一些学者就开始去做模型的优化,就是模型的参数量或者模型的计算量希望小一些,同样它的性能能够保持住。能够在我们实际的一些嵌入式设备上用,或者计算量比较低的平台上去跑的速度更快一些。
所以说后面就有了 MobileNet,就一些落地用的 Net。包括后面还有个 VOVNet。VOVNet 有机会的话弄一节免费课来说说。不过 VOVNet 要想听懂,前面那些基础的模型得理解。
设计完分类,我们就会说,分类是我们人工智能的基础。分类是我们人工智能所有计算机视觉中的基础。目标检测、目标分割、跟踪、关键点检测等等,分类是它们的基础。学会分类,其实那些方法都会了。
所以说那些方法本质上都是分类算法的提升。怎么把分类算法用的更好,把分类算法用到目标检测,用到目标跟踪,用到自然语言处理上,用到推荐上,基本上道理都是一样的。
所以说,分类我们会讲的比较细。然后,分类讲完了,我们就可以去利用分类去设计我们的检测模型了。
所以下面我们就讲检测模型。检测模型有两大系列,是 Yolo 和 RCNN,分别是代表一阶段检测、二阶段检测的思路。
那么当前的论文,像 20 年的论文,21 年的论文。特别是 20 年的,我看大部分是出自于两阶段的 RCNN 系列模型。之后的一些设计思路基本上都是基于它的。所以说是非常经典。
因为 RCNN 出来之后是 Yolo 出来了,Yolo 当然也要参考它的思路。时间就比较晚,晚一年、两年。然后在他的思路上做了创新,后面我看到 20 年大家还是在这些思路上做创新。
检测我们是两部分的内容。然后后面一个部分就是讲分割,就如何设计分割模型。再后面讲如何设计跟踪模型。
这就是咱们后续课程的一个展开情况,是我们后面要讲的。有了前面两部分课程的一个基础,咱们才好开始模型的设计学习。
好,这就是咱们这节课的内容,主要讨论了一下计算机视觉的常用模型,并且讲之后课程的内容概要给大家讲了讲。这节课内容其实蛮重要的,对于已经大致了解的同学作用不太大,对于刚进入计算机视觉这个领域的同学,大家可以趁机去查一下我说的这些个模型,做一个预习,好接下来跟上咱们后续的课程。
下节课,咱们取讨论下「CNN 统一了特征与决策」这样一个话题。
好,下节课见。拜拜。
计算机视觉的常用模型

