17. BI - Surprise 工具箱:Baseline
本文为 「茶桁的 AI 秘籍 - BI 篇 第 17 篇」

[TOC]
Hi, 你好。我是茶桁。
今天给大家介绍另外一个方法:surprise。重点来看一下 surprise 的一些工具的使用。
在此之前,来说明一下 Spark 单机的分布式。其实分布式是一个方法,它把一个数据分成了很多块,这些块是相对独立的,在最后的结果层再把它进行汇总,这个就是一个分布式的概念。那为什么一台机器也可以?
分布式的数据可以放到多台机器,一个数据分成了很多块,块 1 在机器 1 里面,块 2 在机器 2 里面,块 3 在机器 3 里面,分成了不同的块。这样的存储是分布的,计算也是分布的,最后计算完再进行汇总,这个就是分布式的概念。
原来在三台机器的数据现在放在一台机器可不可以?也可以,当你数据量级不大的情况下它也有可能都是在一台机器,在一台机器上分块进行操作这也是 OK 的。所以本身 Spark 是可以单机来进行运行的。
通常情况下,是放在多台机器的性能高还是放在一台机器的性能高?多台机器它的效率会更高,因为计算资源,每一台机器都是相对独立的一台机器,毕竟内存和计算 CPU 是有限的,要共用一个效率其实不高,肯定是多台机器高。
因此 Spark 是可以有单机版在单台机器来进行使用,但是它背后的原理也是分布式。它是把其看成了块 1、块 2,只不过指向的 IP 都是同一个 IP,计算资源都是同一个 CPU 而已。
目标函数的优化方法
接着,来看看 SGD 的概念。
之前的课程主要给大家讲解了交替最小二乘这种方式,随机梯度下降也是在机器学习的模型中比较常见的一个策略。这个策略怎么去学?
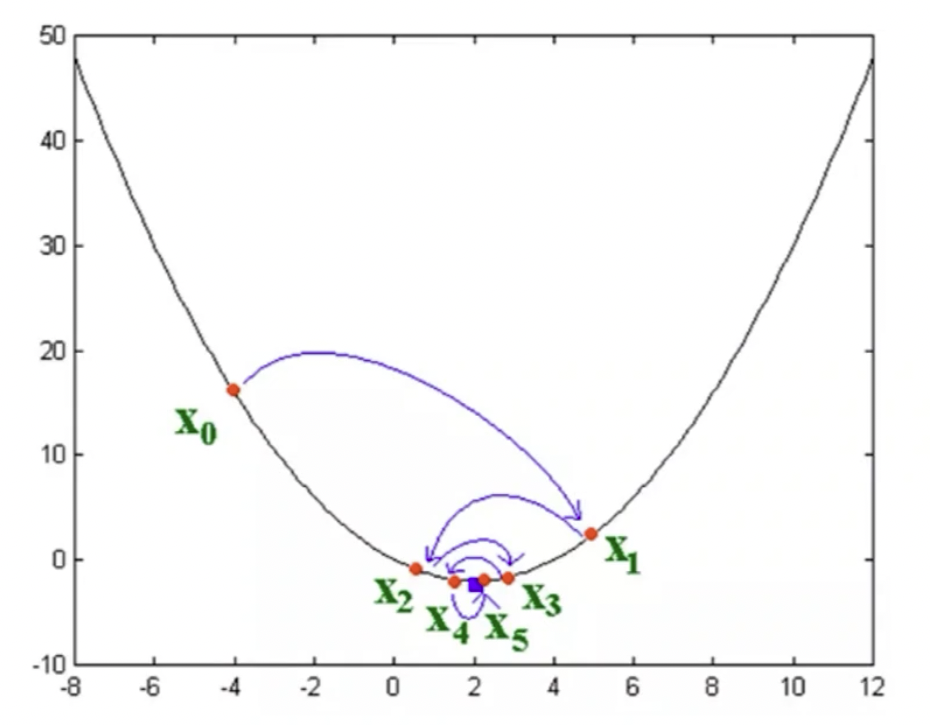
以 X0 这个点为例,目标是要最小值,这是 loss function 的极值问题,这个点现在在这还是有损失的。怎么办,要沿着切线去下降,沿着切线往下去走。步子如果迈的过大,就会跑到曲线右边,再大一点又会跑到左边,所以它就会出现不同的抖动情况。
SGD 就是怎么样去选择这个方向。方向很重要,在参数拟合过程中一个是方向,一个是步长。SGD 基本思路就是以随机方式遍历训练集中的数据,并给出每个已知评分的预测评分。用户和物品特征向量的调整就沿着评分误差越来越小的方向迭代进行,直到误差达到要求。所以 SGD 不需要遍历所有的样本即可完成特征向量的求解。
先看这个概念,看一个线性回归的一个例子,用它来去模拟的 y。
\[ \begin{align*} h_{\theta}(x) = \theta_0 + \theta_1x_1 + \theta_2x_2 + ... + \theta_nx_n \end{align*} \]
以上是预测的方程,其中 theta 为参数,代表权重,n 为特征数。它跟 y 之间用 MSE 去做一个表达,希望让损失函数最小化。
\[ \begin{align*} J(\theta) = \frac{1}{2} \sum_{i=1}^m(h_{\theta}(x) - y)^2 \end{align*} \]
这样的话每一次要学习的过程其实不长。
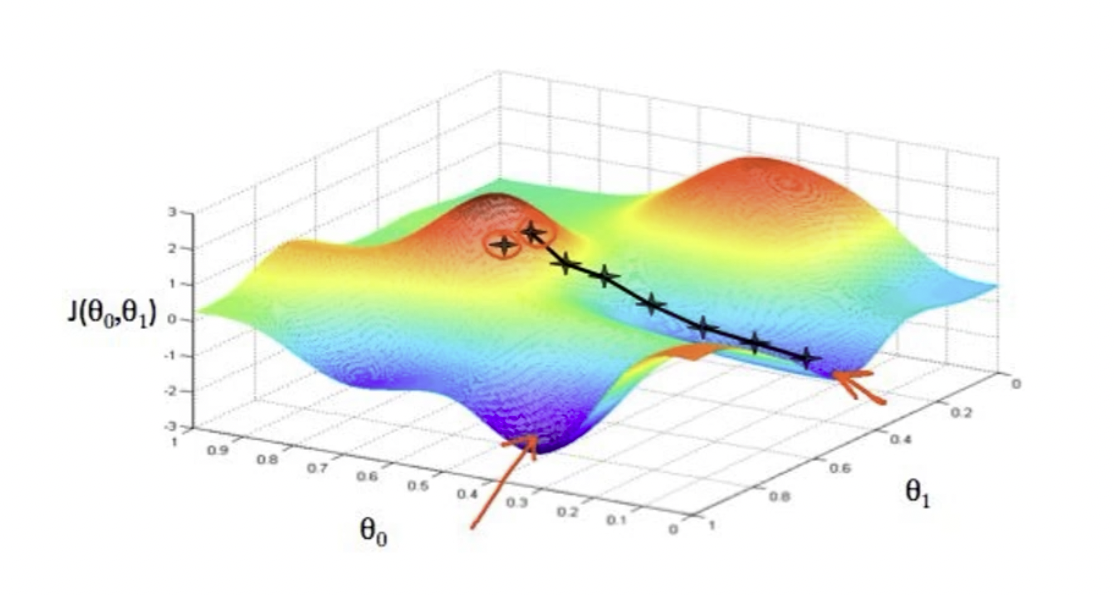
处于山中的某个位置,不知道极值点在哪里,每一步都以下降最多的路线来下山。
\[ \begin{align*} \theta_j = \theta_j - \alpha \bigtriangledown J(\theta) \end{align*} \]
这里的 alpha 代表的是学习率(步长),这个步长是沿着梯度的方式,就是沿着 loss function,对它的参数的一个导数,沿着它来进行下降。
曲面上方向导数的最大值的方向代表了梯度的方向。沿着梯度方向,会让 h 值升高,因此需要沿着梯度的反方向,也就是采用地图下降的方式进行权重更新。
每次的更新,梯度下降是沿着导数的反方向来进行下降的。那么 theta
就减去了这个方向,它就会前进一步。= 后面的 theta
是原参数,= 前面的是更新之后的参数,被赋予了新值。
所以参数每一轮都会进行不断的迭代,不断的优化。那选择这个方向重要不重要呢?这个方向很重要。来看看更新的过程。
\[ \begin{align*} \theta_j & = \theta_j - \alpha\frac{\partial}{\partial \theta_j}J(\theta) \\ \frac{\partial}{\partial \theta_j}J(\theta) & = \frac{\partial}{\partial\theta_j}\frac{1}{2}(h_{\theta}(x)-y)^2 \\ & = 2 \cdot \frac{1}{2}(h_{\theta}(x)-y)\cdot\frac{\partial}{\partial \theta_j}(h_{\theta}(x)-y) \\ & = (h_{\theta(x) - y}) \cdot \frac{\partial}{\partial\theta_j} \left[ \sum_{i=0}^n \theta_ix_i - y \right] \\ & = (h_{\theta}(x) - y)x_j \end{align*} \]
这是它的导数过程,方向有三种方向
- 批量梯度下降
- 随机梯度下降
- mini-batch 梯度下降
这三个咱们在机器学习的基础课中都有详细的讲解过其原理。大家可以回过头去好好看看相关的课程。这里简单说一下这三种方向的一个特点。
批量梯度下降,在每次更新时用所有样本,稳定,收敛慢。
随机梯度下降,每次更新时用 1 个样本,用 1 个样本来近似所有的样本,更快收敛,最终解在全局最优解附近。
而 mini-batch 梯度下降每次更新时用 b 个样本,折中的方法,速度较快。
这也是一个比较常见的概念,未来不管是面试的时候还是在使用优化方法的时候都可以去了解采用的方法是哪一种方法。随机下降会使用更多,它虽然每次都是随机一个但是速度会更快,相对来说 SGD 的使用场景会比较多。
其实目标函数优化方法已经不仅仅是 SGD,SGD 是最早提出来的,后面还有很多种。现在用的更多的是 Adam, 它综合了很多个方法,这个后面有时间再详细给大家进行讲解。SGD 也有一些缺点。在梯度过程比较常见的是刚才说的这三种。
Baseline 算法
ALS 和 SGD 是可以用于很多的优化方法,这里给大家看 surprise 的一种:baseline。它要求解的是预估一个电影的评分,结果是 \(b_{ui}\),把这个评分结果拆成了 3 个指标,
\[ b_{ui} = \mu + b_u + b_i \]
mu 是均指,大盘平均的分数。\(b_u\) 是用户偏差,\(b_i\) 是商品偏差。
举个例子,还是以前几节课中的 MovieLens 那个电影为例。在那个电影中有一部电影叫做泰坦尼克号,这个电影拍的比较好,它的 \(b_i\) 是正向的,多了 0.5 分。在 MovieLens 里面它整个的评分是 3.7 分。
这个值是直接计算来的,直接把所有电影相加以后除上总数就可以得到评分值。还有 \(b_u\) 是用户偏好,比如说这个用户比较苛刻,比一般的人打的分要低,低 0.3 分。那么这个苛刻一点的人给泰坦尼克号会打多少分?
如果利用这个公式就直接可以求出来,这是一个简单的建模过程。把用户和电影之间的交互拆成了三段,大盘分,用户的偏好分和商品的偏好分。这个苛刻的人对泰坦尼克号会打多少分,就直接把这 3 个数值做一个相加,应该等于 3.9 分。这就是 baseline 的一个策略,用户对商品的评分分成了 \(\mu + b_u + b_i\)。
要学的参数是哪一个?mu 是直接求出来的,\(b_u\) 和 \(b_i\) 是要去学的内容。这个 baseline 方法没有做个性化的偏好,做的是整体的偏差。
一个苛刻的人,假设他对所有电影都倾向于比一般的人要低 0.3。\(b_i\) 是这个商品整体的评分,假设所有人都会认为它比一般的电影要好 0.5 分,其实并不一定,有些人可能就不喜欢这种类型的电影,有些人可能会更加喜欢。现在不考虑那种个性化的偏好,只考虑那些对整体的评价,所以这个参数要学的应该就是 \(b_u\) 和 \(b_i\),\(b_u\) 和 \(b_i\) 要进行学习。
\[ \begin{align*} min_{b_u}\sum_{(u,i)\in k}(r_{ui} - \mu - b_u - b_i)^2 + \lambda_1(\sum_{u}b_u^2 + \sum_ib_i^2) \end{align*} \]
这个方法有点像之前给大家介绍的 ALS 方法?从定义上来去看的话很类似,都是原来的实际分减出预测出来的分,再加上后面的正则化项。不过区别也是有的,哪种方法计算量会更简化一些?是之前给大家讲的 ALS 方法更简单,速度更快,还是 baseline 这个方法速度更快?
如果做的是个机器学习的建模,要衡量的是要学习的参数量是多少。那 baseline 更快,因为参数量更小,\(b_u\) 和 \(b_i\) 只需要计算它整体的过程。
之前是有个 k 的概念,k 等于 3
,要把一个用户分成三种情况,商品分成三种情况。而现在可以把它看成一种特殊的
k 等于 1。相当于只需要把一个 k 变成 1,就类似于变成一个
baseline。就之前讲解的12 * 3和3 * 9两个矩阵,user
和 item, 只需要 user 的一列,item 矩阵也只需要一行就行了。
这就是 k 等于 1 的一种情况,只需要快速的计算一下 k = 1,这是 baseline 的一个特点。
它使用的方法也可以使用 ALS,ALS 就固定一个求解另一个。现在 k=1,k=1 它不是矩阵而是向量了。可以固定一个向量 \(b_u\) 求另一个 \(b_i\),再把 \(b_i\) 固定下来以后再去求 \(b_u\) 就可以了。所以 baseline 的速度会稍微快一点点。
each item i we set:
\[ \begin{align*} b_i = \frac{\sum_{u:(u,i)\in k}(r_{ui} - \mu)}{\lambda_2 + |{u|(u,i)\in k}|} \end{align*} \]
Then, for each user u we set:
\[ \begin{align*} b_u = \frac{\sum_{i:(u,i)\in k}(r_{ui} - \mu - b_i)}{\lambda_3 + |{i|(u,i)\in k}|} \end{align*} \]
Surprise 推荐系统工具
baseline 是在 surprise 里的一个工具,surprise 又是 scikit 系列中的一个推荐系统库。文档:https://surprise.readthedocs.io/en/stable/
还有一个就是 LightFM,是 Python 推荐算法库,具有隐式和显式反馈的多种推荐算法实现。易用、快速(通过多线程模型估计),能够产生高质量的结果。
今天给大家使用的是 surprise,其常用算法包括:
- Baseline 算法
- 基于领域的协同过滤
- 矩阵分解:SVD, SVD++, PMF, NMF
- SlopeOne 协同过滤算法
刚才给大家看的 baseline 是一种比较简略的方法。认为用户的打分求出来的参数是对整体的,商品的好坏也是对整体的。
除了 baseline 还有一些算法,其实整个的 surprise 工具箱里面提供了很多可以调包的一些工具:
| 算法 | 描述 |
|---|---|
NormalPredictor() |
基于统计的推荐系统预测打分,假定用户打分的分布是基于正太分布的 |
BaselineOnly |
基于统计的基准预测线打分 |
knns.KNNBasic |
基本的协同过滤算法 |
knns.KNNWithMeans |
协同过滤算法的变种,考虑每个用户的平均评分 |
knns.KNNWithZScore |
协同过滤算法的变种,考虑每个用户评分的归一化操作 |
knns.KNNBaseline |
协同过滤算法的变种,考虑每个用户评分的基线 |
matrix_factorzation.SVD |
SVD 矩阵分解算法 |
matrix_factorzation.SVDpp |
SVD++矩阵分解算法 |
matrix_factorzation.NMF |
一种非负矩阵的协同过滤算法 |
SlopeOne |
SlopeOne 协同过滤算法 |
这是整个的 surprise 工具箱里面能提供的可以调包的一些工具。baselineOnly 是基线,一般来说看到 baseline 的基线都可以猜测到它的方法速度会比较快,但是准确率可能相对一般,拿个六七十分应该问题不大。
Surprise 进行 MovieLens 电影推荐
要用的话,还是直接去调包 surprise:
1 | |
surprise 里面这个类 Dataset 和 Reader,相当是自己的一个读数的工具,你可以把它理解成是个读卡器。这个读卡器需要设定一些格式,通过这个格式会转成一个内部格式。
先是读入一些数据,build 一下训练集:
1 | |
所以先去引用一下它的 reader,从 CSV 里面进行读取得到一个 data,这是它内部的 dataset,然后再把这个内部 dataset 调入一个 build trainset,一个函数,这样它就会自动生成一个训练集。这是它写好的一个内置函数,不需要你做 train set 了。
生成的这个训练集以后在 surprise 里面要用 baselineOnly 这个方法创建这个包。在设置参数过程中有几个比较重要的项,一个是优化方法可以指定 ALS、epoch,也就是迭代轮次,还有 \(r_u\) 和 \(r_i\)。
1 | |
reg_i 和 reg_u 是正动化系数,再去求 i 和 u 的过程中正动化系数也可以会有一些不一样的地方。
然后又设定了一个 k 折交叉验证,其实不设验证直接去 fit 也可以。
1 | |
fit 以后得到一个结果,然后去 test 得到一个结果。k 折交叉验证是得到 3 折,把这 3 个结果都给它输入出来:
1 | |
除了 ALS 以外,还可以做 SGD。因为它也是优化方法,只要把学习的目标定义出来就可以采用不同的优化侧面来进行求解。
预测结果是指定用户和指定商品,\(r_{ui}\) 代表实际值。可以看一看它跟实际值之间的偏差会有多少
1 | |
这相当于做了 3 个子模型,每个子模型都去判断一下 196 这个用户对 302 的电影的偏差。
可以看到这 3 个子模型 MSE 其实差别不太大,基本差不多。求出来这个结果实际值 4.0,预测出来是 4.18,4.09, 4.11。基本上差别不太大。
以上是用了 baselineOnly,虽然是一个基线的方法,但是结果差别也不是很大,还算是比较准确的。
surprise 里面除了 baselineOnly,还有一个 NormalPredictor,这个方式今天没有详细讲,其实你也可以调包去使用。它背后的原理是拟合一个正态分布,通过拟合的正态分布给出一个预测出来的值。
1 | |
好,下一节课咱们来看看 Surprise 里的另外一个协同过滤方法,SlopeOne 算法。
17. BI - Surprise 工具箱:Baseline

