29. BI - 初接触 Graph Embedding
29. BI - 初接触 Graph Embedding
本文为 「茶桁的 AI 秘籍 - BI 篇 第 29 篇」

[TOC]
Hi,我是茶桁.
Graph Embedding 是一个比较重要的内容,这一部分的内容可能要讲个几节课才能完全讲完。那今天的课程大家先放松一下, 这节课没那么多内容, 主要来了解一下相关概念。
课程回顾
在开始今天的课程之前,咱们先来回忆一下之前的课程内容.
上一节课中,我们讲了图的相关知识,包括两个最短路径算法 Dijkstra 和 Floyd.
其实不只是上节课,咱们整个四个篇章内都在讲基于图的算法,也可以说是思想. 最开始,引出了十大经典机器学习之一的 PageRank,咱们一共用了三节课的内容来讲其相关思想以及以它为基础延展的其他算法,包括 PersonRank,EdgeRank 以及 TextRank.
Graph Embedding 概要
今天,咱们还是要继续看图,来看看 Graph Embedding。
这个技术在 19 年到 21 年之间是非常火热的一项技术,当然,现在最火热的当属以 ChatGPT 为首的 LLM 相关的内容.
Graph Embedding 在推荐系统里面也有使用, 在一些文本表征里面都有使用. 今天咱们就来看一看 Graph Embedding 到底什么样的一个内容.
之前咱们一直有提到过 Embedding ,在 13. 机器学习 - 数据集的处理 中就提到过,而在 24. BI - Embedding 中专门讲过 Embedding. 看过前边课程的同学应该知道, Embedding 是一种嵌入的技术,它把很多特征的维度嵌入到一个固定特征的向量里面去. 所以看到 Embedding 有两个,第一个叫做固定维度. 我们的维度应该是固定下来的,第二个,固定下来维度以后目的就是可计算,方便后续来进行计算. 而且它的可计算只要更容易,找到后面分类结果会更好计算一些。
在后续的神经网络过程中 Embedding 都属于一个标配,只有采用 Embedding 技术才能放到后续更大的网络模型中. 今天咱们就来看一看如何来去对一个图的网络来做 Graph Embedding .
在这之前,我们先要来了解一个东西,就是 非欧几里得数据. 这是一个重要的概念.
我们在去求解 Graph Embedding 的时候有两个重要的技术,分别是 Deep Walk 还有 Node2Vec.
相信读我文章的人基本都是在公众号内阅读的,那可以肯定的是大家都用微信朋友圈. 微信朋友圈怎么投放广告呢? 要找跟你相似的一些人. 怎么找? 首先要对你的特征要了解,要学习,是基于你的 Embedding 特征表达,要找相似的内容. 基于 Embedding 特征去找相似的其他人还有哪些,这样就会给你做相关的一些推荐. 所以 Node2Vec 在微信朋友圈里面的投放里面是有一些广泛的应用.
这个可以把它理解成是用户画像的提取以及种子用户生成之后做一个人群放大的作用. 你会发现今天的内容在很多的 AI 的领域里面都会有使用。
说到 AI,大家应该都知道 AI 有三大主流的方向,CV,NLP 还有 BI. BI 又会包括其中一个重要的应用场景,就是 RS.
RS 是英文缩写,全称应该是 Recommended system,推荐系统. 推荐系统里面要对用户的特征来进行学习,所以在 CV,NLP,RS 中都有 GCN 的身影. GCN 也就可以理解为是 Graph Embedding 。
在图像里面可以有一些图的表达,可以用图的表征来做提取。文本中也能把它看成图, 在推荐系统用户关系里面也能看成图,所以 GCN 贯穿始终.
Graph 和 非欧几里得数据
咱们先来看几个应用的场景,以图像为例. 大家是否知道图像是由怎样的数据结构来表达的? 图像中一个比较经典的格式叫 JPG, 还有一些其他的格式比如 PNG. 这两个格式是怎么样进行存储的? 或者说把这个格式的图像读取出来.
先做一个小科普,知道的同学可以担待一下,不知道的同学在这里要记住. JPG
的图像格式大部分人应该都知道是三个通道,之前的课程中我也讲过.
哪三个通道呢? 包括「红,绿,蓝」三个通道,也就是我们经常说的
RGB 通道. PNG 和 JPG 相比多了一个透明通道,也就是
RGBA 四个通道,这个 A 是
Alpha.
这里每个通道都可以把它看成一个矩阵的表达,矩阵是可以看成一个长和宽的数组.
\[ \begin{align*} A = \begin{bmatrix} 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 1 & 1 & 1 & 1 & 0 & 0 \\ 0 & 1 & 2 & 2 & 1 & 1 & 0 \\0 & 1 & 2 & 2 & 2 & 1 & 0 \\0 & 0 & 1 & 2 & 2 & 1 & 0 \\ 0 & 0 & 1 & 1 & 1 & 1 & 0 \\ 0 & 0 & 1 & 1 & 1 & 1 & 0 \end{bmatrix} \end{align*} \]
不管是几个通道,每个通道都是一个矩阵. 现在要对矩阵的特征来进行提取. 咱们现在还没有专门讲到图像的识别技术,在核心基础篇里有稍微提到一些. 看过前面文章的同学应该知道, 如果对图像做特征提取一般会 CNN,也就是卷积神经网络.
CNN 就是一个小的卷积, 是一个小的二维矩阵.
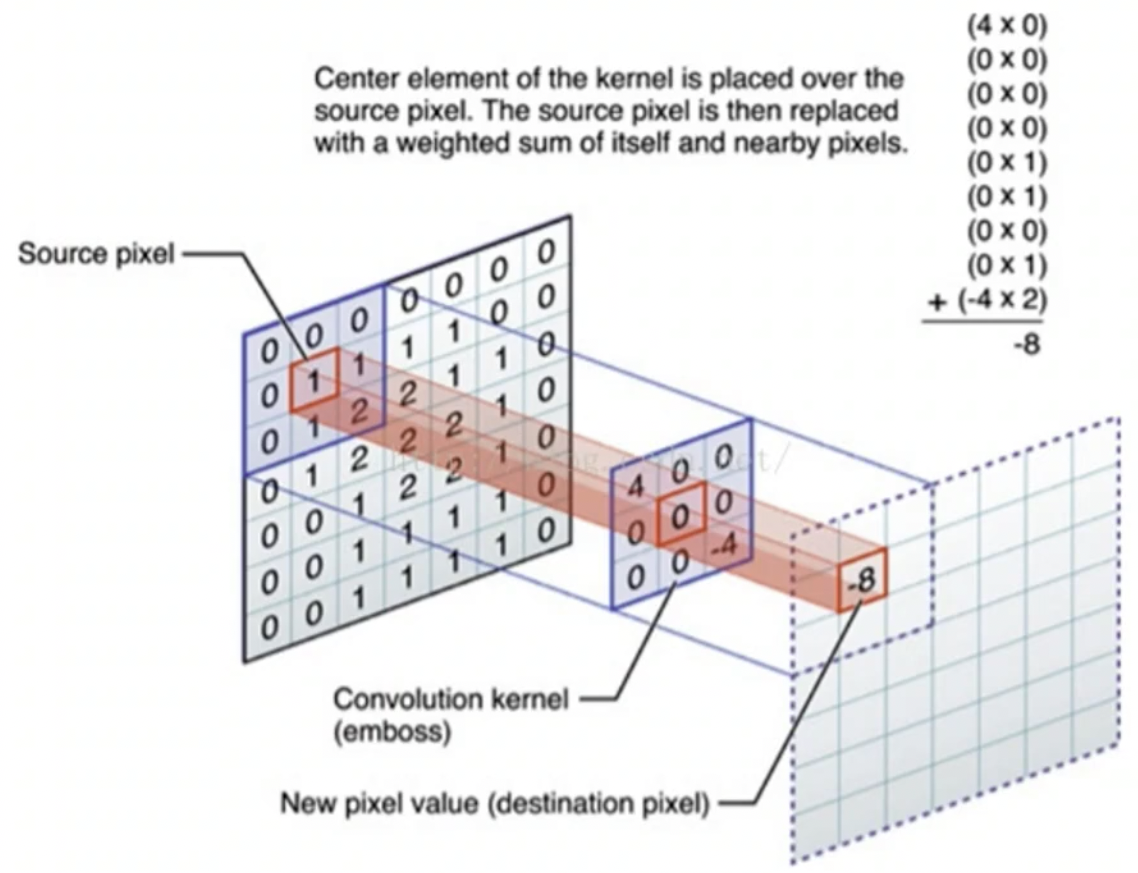
这个二维矩阵是一个规则二维矩阵数据,我们称之为欧几里得数据. 就是在数学课上学的欧式空间。
那我们再来看一张图:
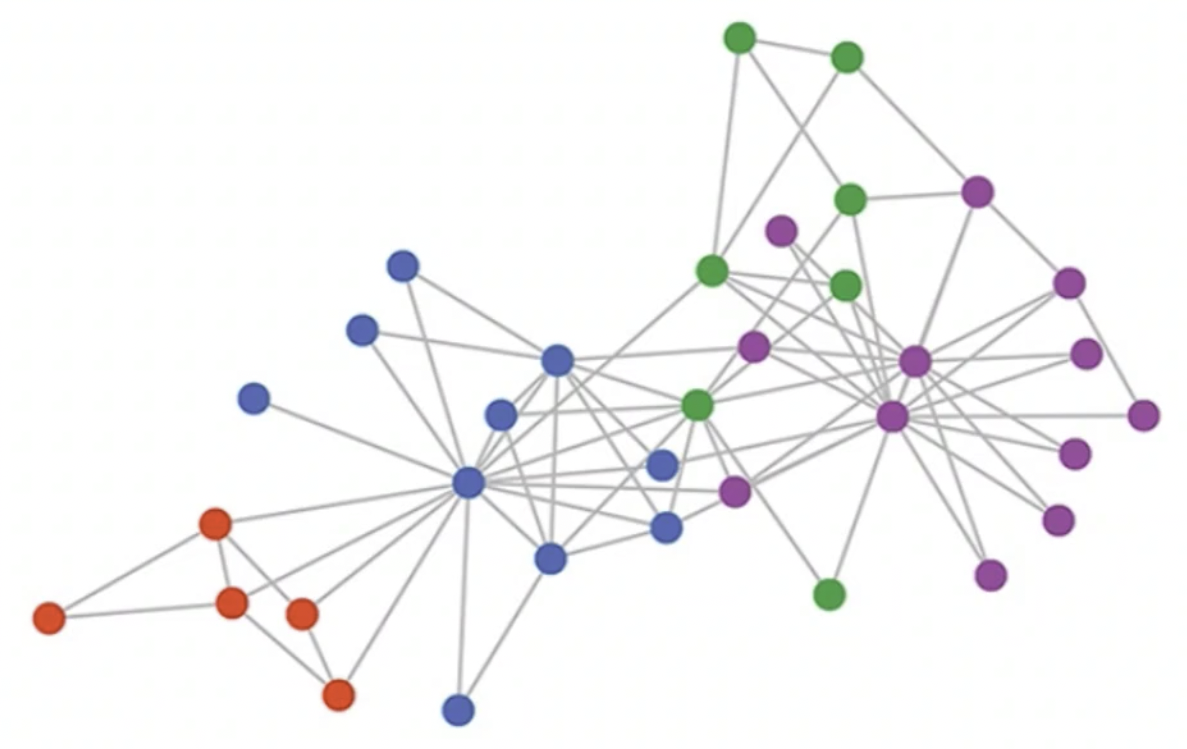
这张图里的数据没有明确的表达的方式,也没有一个明确的存储方法,我们可以把它称为
Graph, 之前 CNN
中的图像我们称为Image,这两个不一样.
二维矩阵上下都有点,相对来说比较规整. 图,也就是 Graph 是由顶点和边组成的,图中每个顶点其边的数量有可能是不定的,所以对于节点来说它的连接方式有可能是不一样的. 这种方式就不是规整的,就无法用欧式空间来进行求解. 我们把这样的数据称之为「非欧几里德数据」,也就是每个节点都有可能会有不一样的连接方法.
再来看看 NLP,在做一些文本的分类,文本的一些特征提取有很多源于 Embedding 的技术,word2Vec 就是其一。
之前在 24. BI - Embedding 这一章节中咱们就介绍过 word2Vec,里面也讲到过,这是 Google 提出来的一种模型.
我们在这里再来简单提一下,防止有些小伙伴没看过前面的课程或者忘记了. word2Vec 是把一个句子抠出来一块儿,两边的内容是它的上下文,中间的部分是要预测的内容. 我们有两种学习的方法,拿到两边预测中间或者拿到中间预测两边.总之我们要去求解的是它跟上下文之间的一个关系.
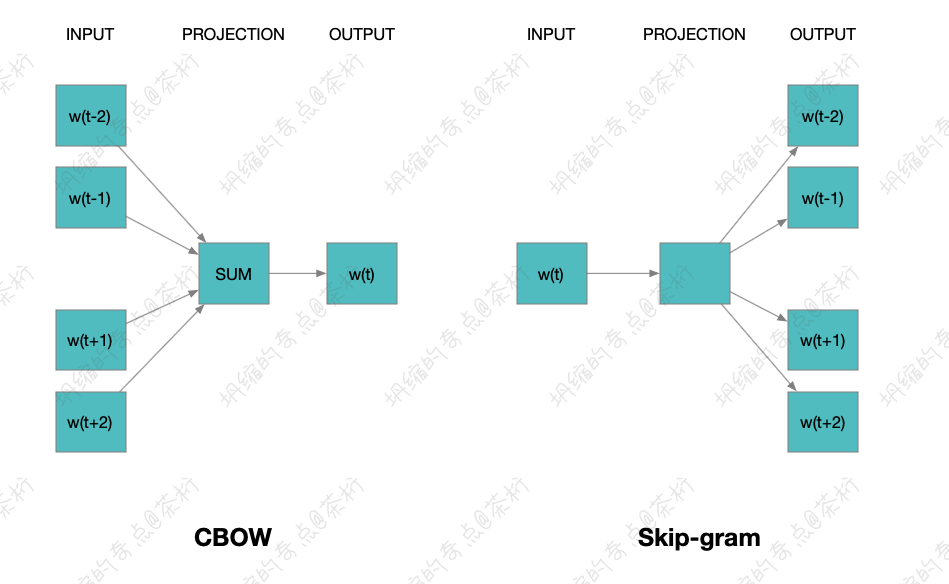
对于一个句子来说,它的长度确实有可能是不一样.
但是在表达和计算的时候我们会以窗口的方式 Window size
来做一个定义,每次都是由滑动窗口在一个规则的形状上面来进行移动,这个是不是跟
CNN 类似?
CNN 是一个矩阵在图上进行移动,而 word2Vec 的滑动窗口是一个长度的窗口,一维窗口,在上面进行采集读出数据,这个数据也是规整的.
那接下来这张图就不是规整的内容了
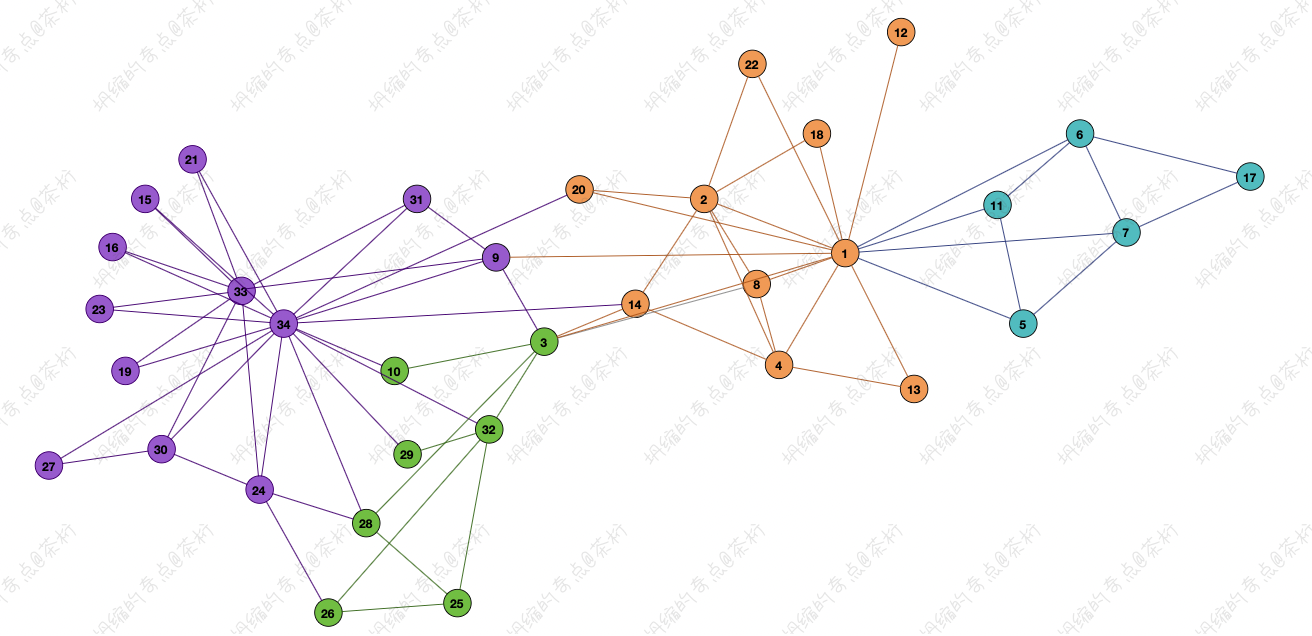
有些情况下,确实是可以把它看成这张图这种表达的形态. 所以在这种方式里面就可能要采用一些不一样的方法,就是将要给大家讲解的 Graph Embedding .
什么是 Graph Embedding
Graph Embedding 可以在很多的场景里面去使用,在图像里面,在文本的特征提取里面都有可能去使用到它,包括推荐系统也可以使用 Graph Embedding 。
我们在上一节课 28. BI - 图论工具的作用 的内容中使用过一个美国大学生足球队的数据。 之前的课程中我们对这个数据也有了一个大概的了解, 一共是 115 支球队, 被划分成了 12 个联盟。在上一节课中用过这个数据, 做了图上的一个划分,实现了一个社区发现。
这个数据中每个节点是一个足球队, 每条边是两支球队的比赛记录。只要数据的顶点和边都定义好了, 在图上就可以学习它的一些特征。
具体应该怎么去做?我们就可以采用 Graph Embedding ,Graph Embedding 不止是可以解决足球队的特征提取,把每个球队信息压缩到一个固定的向量空间里面去。还可以有很多场景的使用。
第一个,社交网络。社交网络人和人会有很多的边,它的行为组成一个图,我们可以对它来学习。微信的朋友圈就是采用这种方式来进行种子用户的特征提取。
生物的信息也可以把它看成之前那张图中的一种结构,每个分子之间都可以有些联系,在这里我们再拿过来看一下这张图:
还有在推荐系统用户的购物行为中,每个用户也可以做这样一个链接的关系。
另外在阿里的推荐系统里会有多种角色的划分。推荐系统会有一些用户,还会有一些商品。把用户看成点,把商品也可以看成点,他们之间都会有交互。另外用户和用户之间,商品和商品之间可能也存在着一些关联关系。还有店铺,用户和店铺之间,商品和店铺之间,店铺和店铺之间也可能有关系。
所以我们的顶点,不同的一些类型可以用不同的颜色来做区分,这样就会形成一张特别大的网络。
在这个大的网络中有很多种角色可以一起进行学习,因为他们之间都会有些相互的行为记录。这样我们就可以把每一个用户、商品和店铺的特征都在图上面进行表征的学习。
我们也可以用于后续的一些预测。当找相似性的商品,相似性的用户的时候就可以去做一些推荐。
所以当前讲解的 Graph Embedding 在社交网络、生物信息、用户购买预测等等这些领域里都是可以使用的,他们都存在着大量的关系图谱。
Graph Embedding 就是一种 Embedding 降维技术,可以有效的挖掘图网络中的节点特征表示,把原来很稀疏,很大的向量给固定下来,压缩到一个稠密的空间中。这样就可以方便的去做后续的一些计算。
Graph Embedding 在推荐系统、计算广告等等领域中是一个热点模型,可以把它看成是 Embedding 的技术延伸。
我们之前讲到过,在 Graph Embedding 之前已经有 Embedding 这个名词了,最早是应用于 Word Embedding,它是 Google 提出来的一种单词的表征方法,它会对单词特征做一个提取用于后续的一些分类任务。Graph Embedding 是在 Word Embedding 的基础上又进行了一些深化,可以用于图的表达,也可以用于非欧几里得数据的计算。
Graph Embedding 可以帮我们从图网络中进行特征提取,将图网络中的点用低维的向量表示,并且这些向量要能反应原有网络的特性,比如原网络中有两个点的结构相似,那么这两个点表示的向量也应该类似。
Graph Embedding 主流的技术有三种,第一个是在图上面去做一个因式分解机,称为「图因子分解机」( factorization methods ),第二种是「随机游走」(random walk techniques) ,第三种是「深度学习」(deep learning)。这次我们先讲解随机游走的方法,之后的课程中,我们再去介绍深度学习的方法。这三种方式都可以在图上面得到特征表达。
下节课, 咱们就来看看 Graph Embedding 的相关算法 Deep Walk。
29. BI - 初接触 Graph Embedding

