GitEval — 预测你的 GitHub 个人资料的质量
使用机器学习来预测你是否擅长编码
如果你曾经申请过技术职位,你可能已经向公司发送了你的 GitHub 个人资料链接。此个人资料中的信息可以很好地表明你的编码能力以及是否适合团队。所有这些信息的缺点是招聘人员可能需要很长时间才能评估它。为了节省时间,机器学习可能用于自动评估你的编码能力。

在本文中,我们将引导你完成构建此类模型的过程。我们讨论了如何从 GitHub 收集数据并使用这些数据创建模型特征。为了建立一些直觉,我们探索了数据集中的关系。最后,我们比较和解释了两种 ML 算法——决策树和随机森林。你可以在「GitHub」1上找到此分析的代码。
数据收集和特征工程
从你的代码存储库到你关注的其他程序员,你的 GitHub 个人资料中有很多公开可用的信息。我们构建了一个网络抓取工具,从 230 位用户的个人资料中收集了部分数据。例如,你将在任何用户的概览页面上看到与图 1 类似的贡献列表。当用户编写新代码并将其保存到他们的代码存储库 (repos) 之一时,他们就做出了贡献。
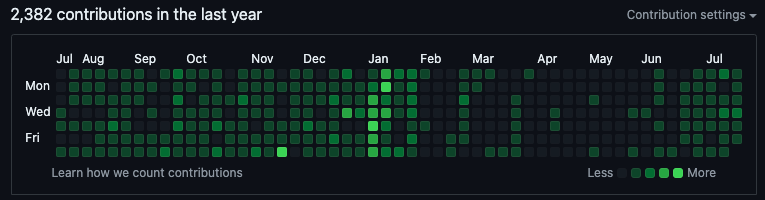
通过抓取这些数据,我们最终得到了去年每天的贡献数量列表。为了能够在模型中使用这些数据,我们首先需要进行一些特征工程。我们可以通过几种方式做到这一点。例如,我们可以计算去年的贡献总数(n_cont)。我们还可以计算自上次贡献以来的天数(last_cont)。这些贡献只是我们可以用来创建模型特征的
GitHub 个人资料的一个方面。
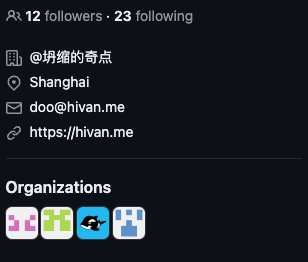
图 2
显示了用户侧边栏中的一些信息。从中,我们可以获取关注者的数量、关注数以及用户已加星标的存储库数量(stars)。这些已经是数字,因此无需进行特征工程。最后,我们还根据组织信息
( org_flag )
创建一个标志,该标志将指示用户是否属于某个组织。
最后一组特征来自用户的存储库。在图 3
中,我们可以看到一些代码存储库的示例。我们收集了用户创建的存储库总数 (
repos
)。我们还收集了每个存储库中使用的编码语言。由此,我们计算出所有用户存储库中使用的不同编码语言的数量
( n_lang )。
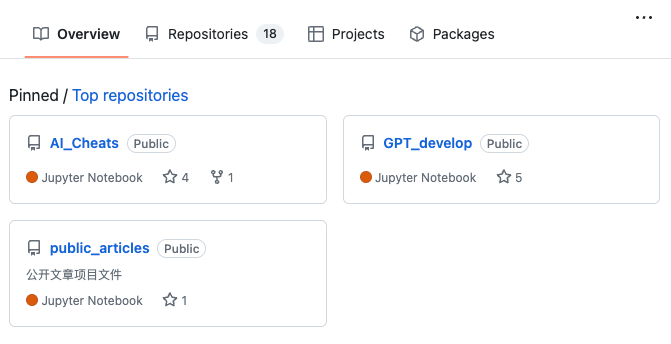
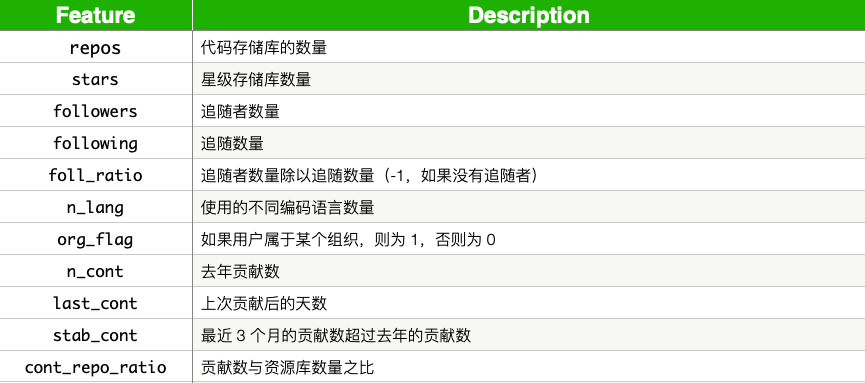
表 1
总结了创建的所有模型特征。除了stab_cont、foll_ratio和cont_repo_ratio,我们在上面讨论了所有这些特征。还有其他信息/特征来源可以创建。我们将自己限制在这一组,因为它们相当简单,数据很容易抓取。希望这些特征至少与编码能力相关,使我们能够做出准确的预测。具体来说,我们将尝试使用它们来预测
0 到 5 之间的评级。
此评分是通过取两个独立评分的平均值得出的。重要的是,评分者不受上述功能中包含的信息的限制。例如,评分者可以打开存储库中的文件并阅读实际编写的代码。在浏览个人资料后,每个评分者都会根据用户的编码能力给出评分,从 0 到 5(5 为最佳)。两个评分的平均值作为最终评分/目标变量。
数据探索
在深入建模之前,探索模型特征是个好主意。我们这样做是为了建立直觉并了解哪些特征能够很好地预测评分。图
4
中可以看到一个潜在的良好预测器示例。在这里,我们可视化了评分和n_cont之间的关系。请注意,随着用户的总贡献增加,用户的评分也趋于增加。
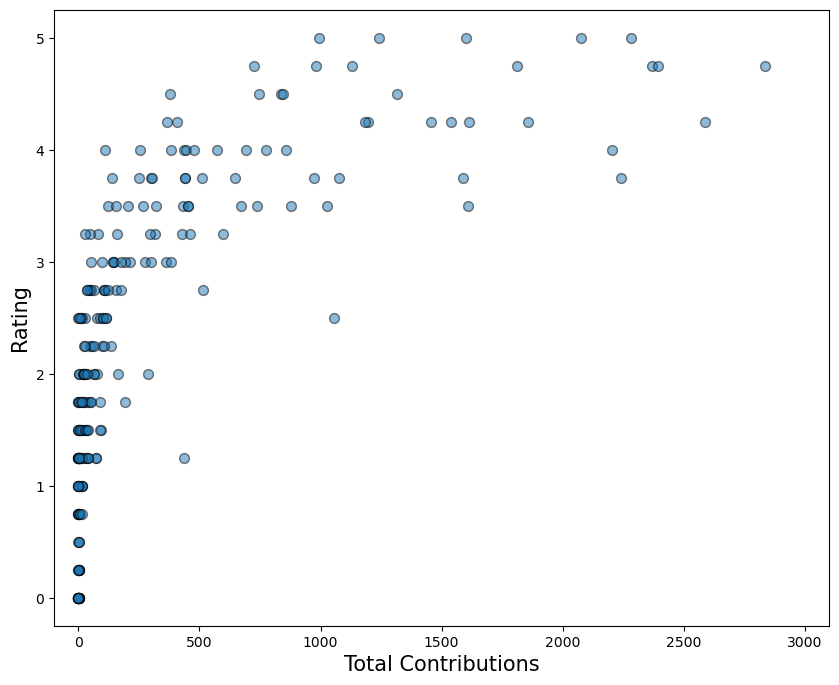
此时,你应该问问自己,这种关系是否合理。没有或很少做出贡献的用户在过去一年中不会做太多编码。做出大量贡献的用户会做很多编码。这似乎合乎逻辑——你编码越多,你的编码能力就越强。我们的模型有望利用这种关系进行预测。
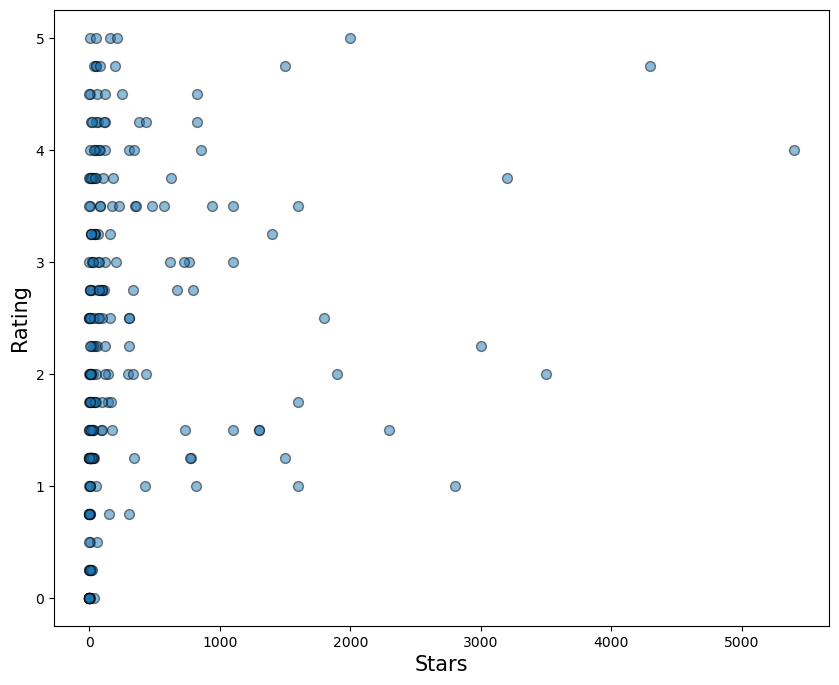
另一方面,你可以看到评级与加星标的存储库数量(Stars)之间的关系。在这种情况下,似乎没有任何模式。也许这是因为你不必进行任何编码即可为其他用户的存储库加星标。也就是说,星星不会告诉我们你的编码能力。从这个分析来看,我们不应该期望星星成为我们模型中的一个重要特征。
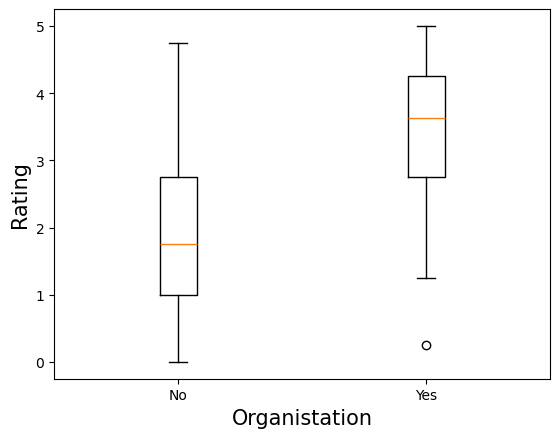
另一个可能很重要的特征是组织标志。我们可以预期,属于某个组织的用户会成为更好的程序员。特别是,如果他们属于像谷歌开源社区2这样的组织。在下面的箱线图中,我们可以看到,属于某个组织的用户的评分确实往往更高。没有组织的平均评分为
1.8,而用户属于某个组织时的平均评分为
3.4。这种差异表明org_flag可能是一个很好的预测指标。
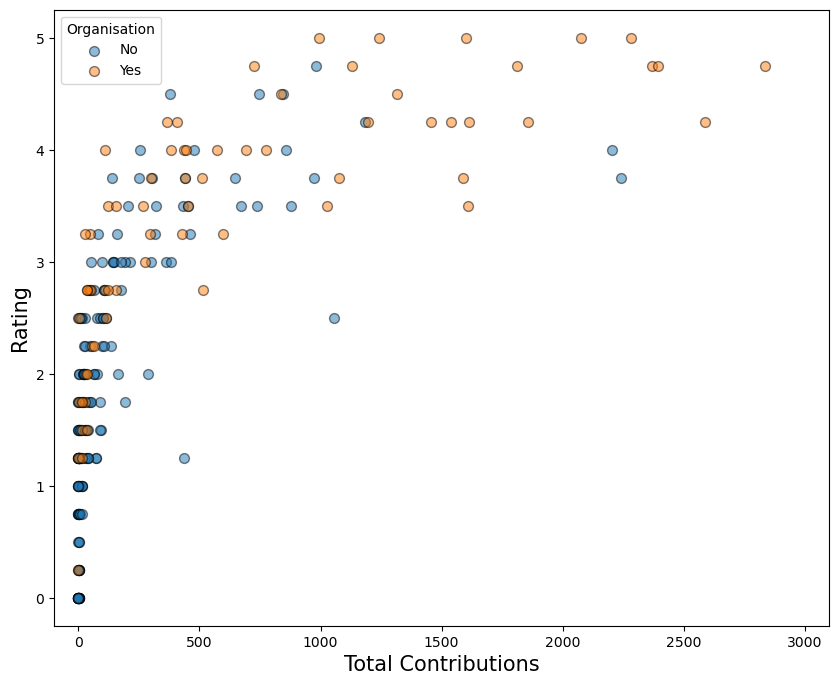
我们应该记住,这些特征并不是孤立存在的。看起来具有预测性的特征,当它们与其他特征一起包含在模型中时,可能并不那么重要。这是由于特征本身之间的关系。例如,在图 7 中,我们可以看到贡献更多的用户更有可能成为某个组织的一部分。具体来说,贡献 500 次或更多的用户中有 70% 是某个组织的成员。而贡献少于 500 次的用户中,这一比例仅为 20%。
假设我们只使用org_flag
创建一个模型。从上面的分析来看,组织中的人员可能会获得更高的预测评级。我们可以通过在模型中添加n_cont
来改善这些预测。同样,贡献较大的人员可能会获得更高的评级。但是,许多贡献较大的用户都是组织的一部分。这意味着他们可能已经获得了高评级,因此包括n_cont可能不会像我们想象的那样改善这些预测。最终,n_cont的重要性实际上取决于它比org_flag提供的信息多多少。

决策树
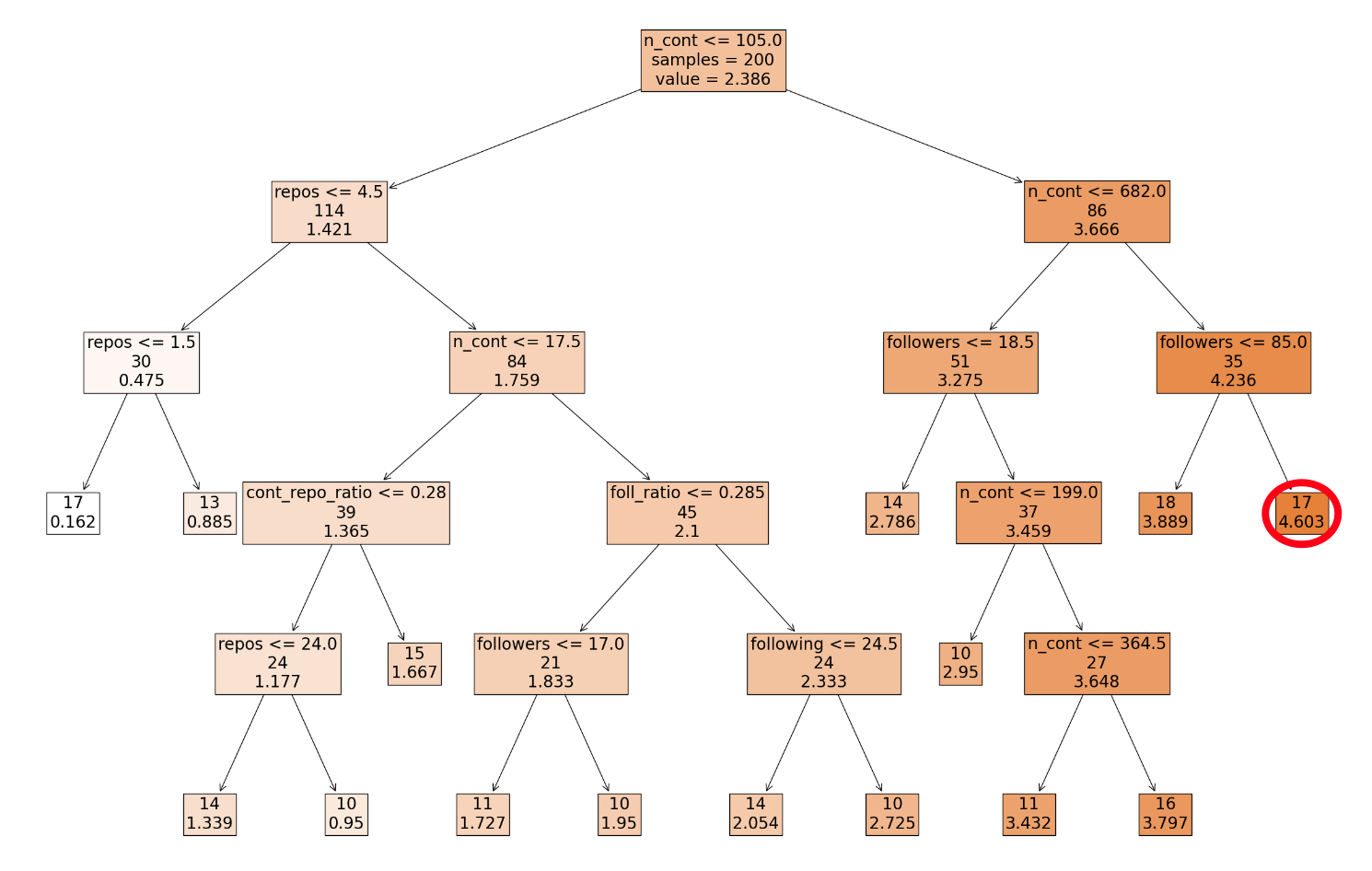
考虑到我们的探索性数据分析,现在是时候进行建模了。我们将从创建一个简单的决策树开始。为此,我们首先拆分数据集并使用 200 行训练决策树。我们将剩余的 30 行保留为测试集。决策树是使用基尼不纯度测量创建的,以确定每个节点的最佳分割。我们还限制树在每个叶节点中至少有 10 个样本。你可以在图 9 中看到整个决策树。
要了解这棵树的工作原理,让我们从根节点开始。如果用户满足第一行中的规则(即至少做出了 105 次贡献),我们就会沿着树的右箭头向下移动。如果不满足规则,我们就会沿着左箭头向下移动。我们继续检查规则并沿着箭头移动,直到到达叶节点。例如,如果用户做出了 900 次贡献并拥有 90 名关注者,我们最终会到达用红色圈出的叶节点。17 位用户最终进入了这个桶,他们的评分为 4.603。
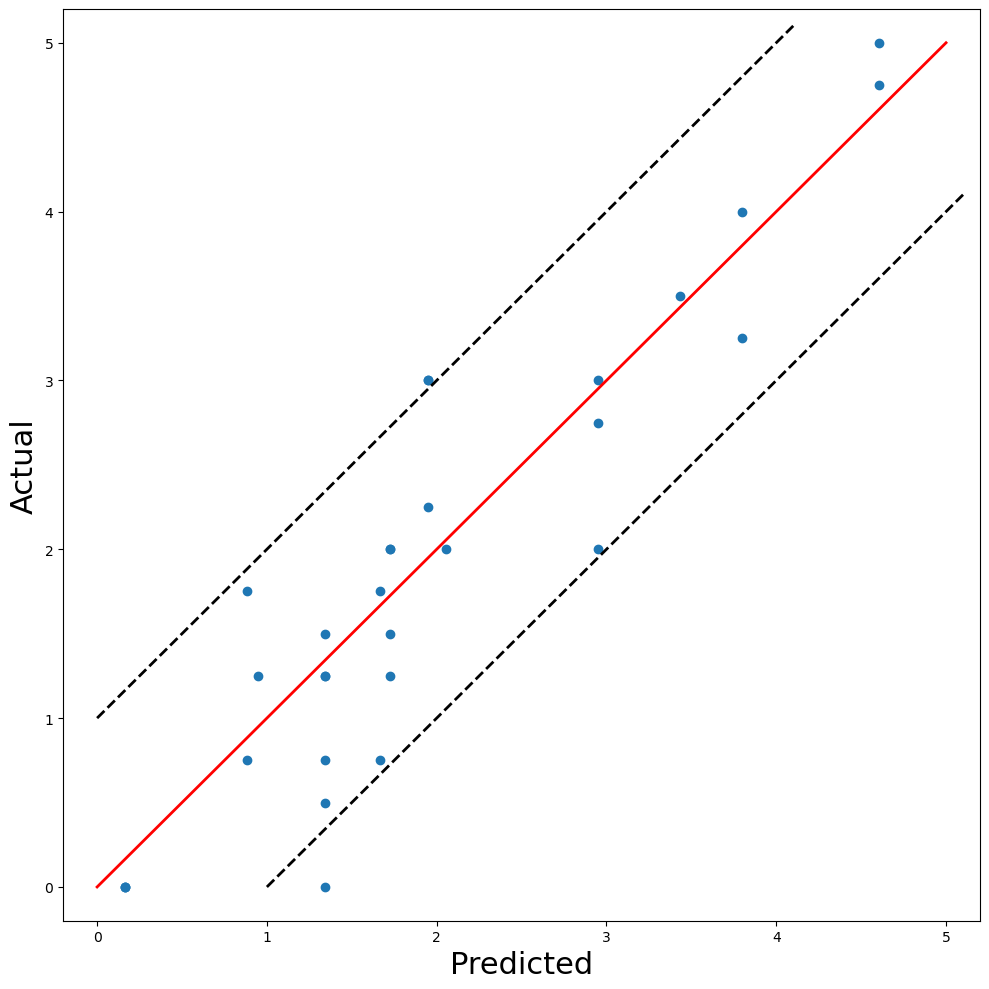
下一步是使用此模型对测试集进行预测。为了评估此模型,我们应该将实际评分与这些预测进行比较。一种方法是使用图 8 中的散点图。如果模型完美,则所有点都会落在红线上(即实际 = 预测)。黑色虚线距离红线一个单位。这意味着与实际评分相比,只有 2 个预测的差异大于 1。总体而言,该模型在测试集上的 MSE 为 0.3077。
随机森林
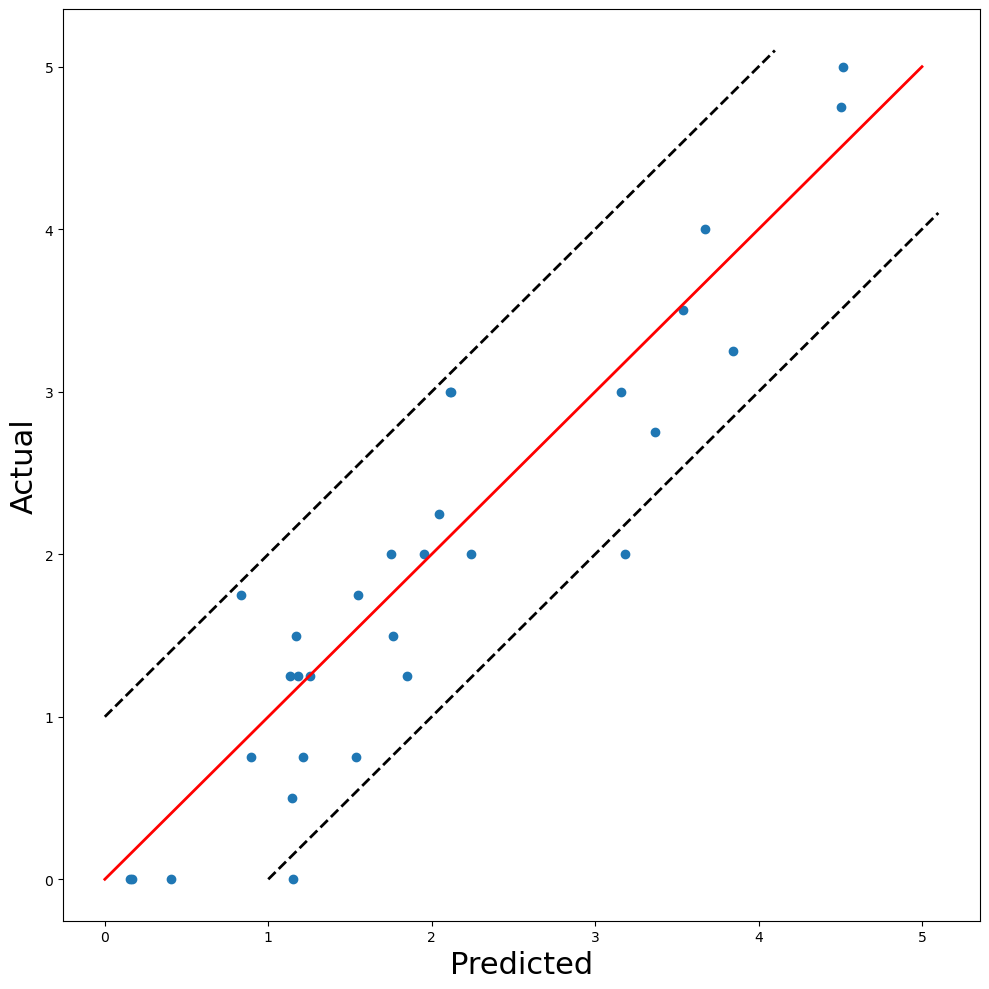
决策树通常被认为是一个简单的 ML 模型。让我们看看是否可以使用更复杂的方法——随机森林来提高这种准确性。具体来说,我们使用一个有 100 棵树的随机森林。每棵树的最大深度限制为 4。与决策树一样,你可以在图 10 中看到实际评分与预测评分的图。
我们再次发现 2 个预测的误差超过 1 个单位。就 MSE 而言,似乎确实有所改善。测试集上的 MSE 为 0.2691,比决策树低 12.5%。在决定使用哪种最终模型时,应权衡准确度的提高与使用更复杂模型的缺点。
其中一个缺点是,我们无法像解释决策树那样解释随机森林。换句话说,我们无法像图 9 那样简单地可视化整个模型。这意味着我们对模型如何进行预测的理解会更差。要解释模型,我们必须使用额外的技术,例如特征重要性分数。
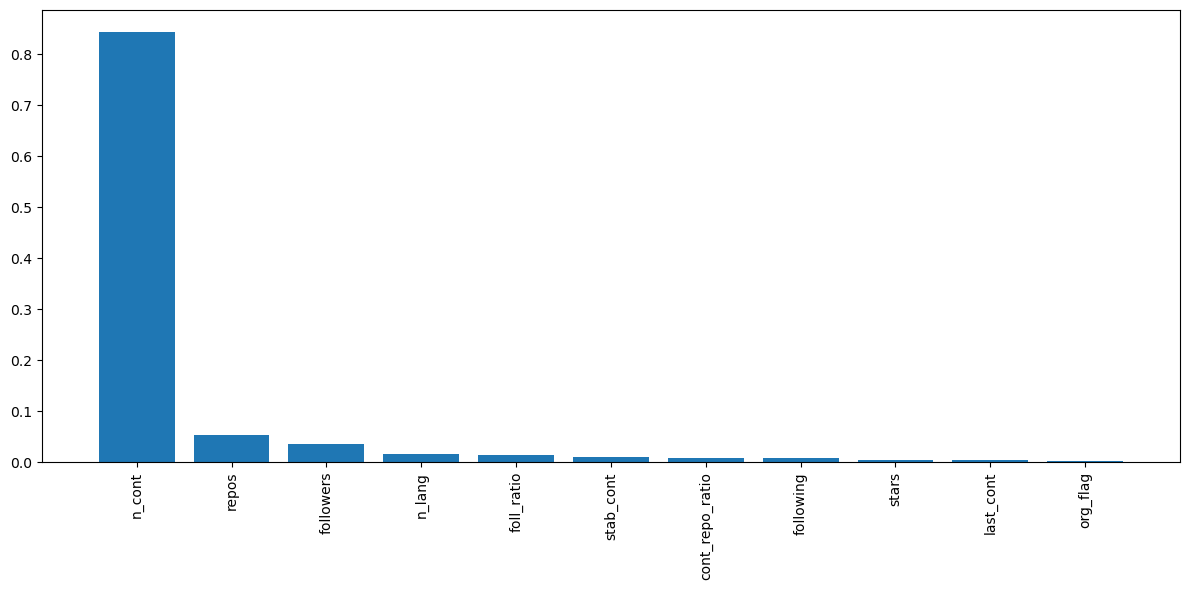
在图 11
中,我们可以看到随机森林的特征重要性得分。一般来说,特征重要性越高,该特征在进行预测时就越有用。我们可以看到,n_cont是迄今为止最有用的,其次是repos和followers。我们可以看到stars不是很重要。这与我们的探索性分析一致。不一致的是org_flag是最不重要的。当与其他特征一起包含时,似乎这个特征并不像我们预期的那么重要。
思考和未来工作
任何模型都有一些需要解决的弱点。我们应该尝试理解的一个方面是,为什么n_cont比其他任何特征都重要得多。查看图
12,当你第一次打开某人的个人资料时,贡献会立即引起你的注意。这可能会对评分者的决策过程产生影响。换句话说,他们可能比他们想要的更依赖贡献。
评分也可能以其他方式产生偏差。例如,如果评分者考虑用户的个人资料图片,则可能会引入种族/性别偏见。为了解决这个问题,我们需要提出一个客观的评分系统。它应该只考虑与编码能力直接相关的信息,并且信息应该更统一地呈现。
实际上,不同公司或团队的评级系统可能有所不同。对于给定的用户,数据工程团队可以给数据科学团队完全不同的评级。这是因为每个团队所需的技能不同。换句话说,评级将反映用户在特定团队中的表现,而不是他们总体上的编码能力。

围绕特征工程还有很多工作可以做。到目前为止,我们使用的特征实际上只是与编码能力有关。做出很多贡献并不能让你成为一名优秀的程序员。只是优秀的程序员往往会做出很多贡献。我们应该尝试从实际编写的代码中创建特征。例如,我们可以确定用户是否使用了单元测试、使用了一致的命名约定或是否正确注释了他们的代码。
总体而言,似乎可以使用机器学习来预测编码能力。使用一种相当简单的方法,我们可以做出与实际评分一致的预测。希望这将为未来更好的模型奠定基础。
我们提到了性别/种族偏见。机器学习中的这种偏见比许多人意识到的更常见。一个例子是亚马逊使用的系统没有以性别中立的方式对求职者的简历进行评级。我们在文章《[[什么是算法公平性]]》中讨论这个问题以及其他一些有偏见的算法:
旨在理解和防止机器学习模型偏见的领域的介绍
AI 进阶:企业项目实战3
参考
「AI秘籍」系列课程:
GitEval — 预测你的 GitHub 个人资料的质量

