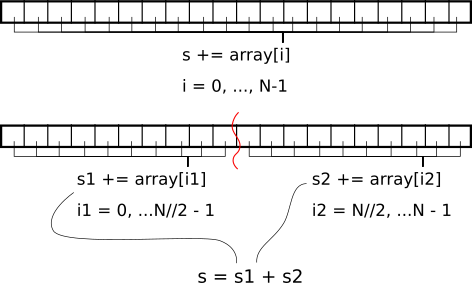
许多任务虽然不是高度并行的,但仍可从并行化中获益。在本期的CUDA by
Numba
Examples中,我们将介绍一些允许线程协作进行计算的常用技术。本部分的
Google colab
代码:https://colab.research.google.com/drive/1hproEOKvQyBNNxvjr0qM2LPjJWNDfyp9?usp=sharing
# We need to create a special *shared* array which will be able to be read # from and written to by every thread in the block. Each block will have its # own shared array. See the warning below! s_block = cuda.shared.array((threads_per_block,), numba.float32)
# We now store the local temporary sum of a single the thread into the # shared array. Since the shared array is sized # threads_per_block == blockDim.x # (1024 in this example), we should index it with `threadIdx.x`. tid = cuda.threadIdx.x s_block[tid] = s_thread
# The next line synchronizes the threads in a block. It ensures that after # that line, all values have been written to `s_block`. cuda.syncthreads()
# Finally, we need to sum the values from all threads to yield a single # value per block. We only need one thread for this. if tid == 0: # We store the sum of the elements of the shared array in its first # coordinate for i inrange(1, threads_per_block): s_block[0] += s_block[i] # Move this partial sum to the output. Only one thread is writing here. partial_reduction[cuda.blockIdx.x] = s_block[0]
⚠️ 注意 :共享数组必须
尽量“小”。具体大小取决于 GPU 的计算能力,通常在 48 KB 到 163 KB
之间。请参阅本表:https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#features-and-technical-specifications__technical-specifications-per-compute-capability
中的“Maximum amount of shared memory per thread block”项。
if tid == 0: # Single thread taking care of business for i inrange(1, threads_per_block): s_block[0] += s_block[i] partial_reduction[cuda.blockIdx.x] = s_block[0]
# We need to create a special *shared* array which will be able to be read # from and written to by every thread in the block. Each block will have its # own shared array. See the warning below! s_block = cuda.shared.array((threads_per_block,), numba.float32)
# We now store the local temporary sum of the thread into the shared array. # Since the shared array is sized threads_per_block == blockDim.x, # we should index it with `threadIdx.x`. tid = cuda.threadIdx.x s_block[tid] = s_thread
# The next line synchronizes the threads in a block. It ensures that after # that line, all values have been written to `s_block`. cuda.syncthreads()
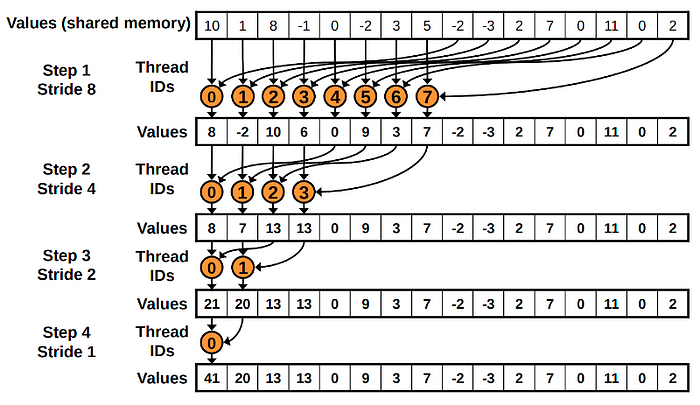
i = cuda.blockDim.x // 2 while (i > 0): if (tid < i): s_block[tid] += s_block[tid + i] cuda.syncthreads() i //= 2
if tid == 0: partial_reduction[cuda.blockIdx.x] = s_block[0]
reduce_better[blocks_per_grid, threads_per_block](dev_a, dev_partial_reduction) s = dev_partial_reduction.copy_to_host().sum() # Final reduction in CPU
np.isclose(s, s_cpu)
--- True
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
timing_naive = np.empty(21) for i inrange(timing_naive.size): tic = perf_counter() reduce_better[blocks_per_grid, threads_per_block](dev_a, dev_partial_reduction) s = dev_partial_reduction.copy_to_host().sum() cuda.synchronize() toc = perf_counter() assert np.isclose(s, s_cpu) timing_naive[i] = toc - tic timing_naive *= 1e3# convert to ms
print(f"Elapsed time better: {timing_naive.mean():.0f} ± {timing_naive.std():.0f} ms")
--- Elapsed time better: 23 ± 1 ms
在 Google Colab 上,这比简单方法快约 30%。
⚠️ 注意:你可能会想把 syncthreads 移到 if
块内部,因为每一步之后,超过当前线程数一半的内核将不会被使用。但是,这样做会让调用
syncthreads 的 CUDA
线程停止并等待其他线程,而其他线程则会继续运行。因此,停止的线程将永远等待永远不会停止同步的线程。这给我们的启示是:如果要同步线程,请确保所有线程都调用了
cuda.syncthreads()。
1 2 3 4 5 6 7
i = cuda.blockDim.x //2 while (i > 0): if (tid < i): s_block[tid] += s_block[tid + i] cuda.syncthreads() # 不要放在这里 cuda.syncthreads() # 而不是这里 i //= 2
# Index the threads linearly: each tid identifies a unique thread in the # 2D grid. tid = cuda.threadIdx.x + cuda.blockDim.x * cuda.threadIdx.y s_block[tid] = s_thread
cuda.syncthreads()
# We can use the same smart reduction algorithm by remembering that # shared_array_len == blockDim.x * cuda.blockDim.y # So we just need to start our indexing accordingly. i = (cuda.blockDim.x * cuda.blockDim.y) // 2 while (i != 0): if (tid < i): s_block[tid] += s_block[tid + i] cuda.syncthreads() i //= 2
# Store reduction in a 2D array the same size as the 2D blocks if tid == 0: partial_reduction2d[cuda.blockIdx.x, cuda.blockIdx.y] = s_block[0]
N_2D = (20_000, 20_000) a_2d = np.arange(np.prod(N_2D), dtype=np.float32).reshape(N_2D) a_2d /= a_2d.sum() # a_2d will have sum = 1 (to float32 precision)
reduce2d[blocks_per_grid_2d, threads_per_block_2d](dev_a_2d, dev_partial_reduction_2d) s_2d = dev_partial_reduction_2d.copy_to_host().sum() # Final reduction in CPU
np.isclose(s_2d, s_2d_cpu) # Ensure we have the right number
--- True
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
timing_2d = np.empty(21) for i inrange(timing_2d.size): tic = perf_counter() reduce2d[blocks_per_grid_2d, threads_per_block_2d](dev_a_2d, dev_partial_reduction_2d) s_2d = dev_partial_reduction_2d.copy_to_host().sum() cuda.synchronize() toc = perf_counter() assert np.isclose(s_2d, s_2d_cpu) timing_2d[i] = toc - tic timing_2d *= 1e3# convert to ms
print(f"Elapsed time better: {timing_2d.mean():.0f} ± {timing_2d.std():.0f} ms")
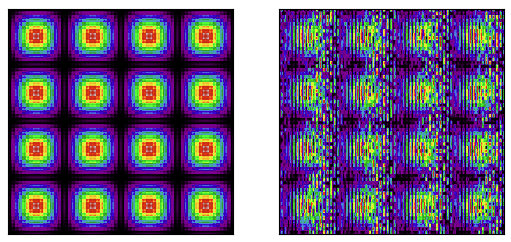
# When we don't sync threads, we may have not written to shared # yet, or even have overwritten it by the time we write to array2d array2d[iy, ix] = shared[15 - tiy, 15 - tix]