Numba 的 CUDA 示例:原子和互斥
本教程为 Numba CUDA 示例 第 4 部分。
本系列第 4 部分总结了使用 Python 从头开始学习 CUDA 编程的旅程
介绍
在本系列的前三部分(第 1 部分,第 2 部分,第 3 部分)中,我们介绍了 CUDA 开发的大部分基础知识,例如启动内核来执行高度并行的任务、利用共享内存执行快速缩减、将可重用逻辑封装为设备功能,以及如何使用事件和流来组织和控制内核执行。

在本节中
在本系列的最后一部分中,我们将介绍原子指令,这些指令允许我们安全地从多个线程对同一内存进行操作。我们还将学习如何利用这些操作来创建互斥锁,这是一种编码模式,允许我们“锁定”某个资源,以便每次只能由一个线程使用。
单击此处获取 Google colab 中的代码:https://colab.research.google.com/drive/1umKcslGW6gpynEfvk79i-jV08uB8_njc?usp=sharing
入门
导入并加载库,确保你有 GPU。
1 | |
1 | |
原子
GPU 编程完全基于尽可能并行化相同的指令。对于许多 "令人尴尬的并行 "任务,线程不需要合作,也不需要使用其他线程使用的资源。其他模式,如还原,则通过算法设计确保同一资源只被一部分线程使用。在这种情况下,我们通过使用同步线程来确保所有其他线程都能及时更新。
在某些情况下,许多线程必须读取和写入同一个数组。如果试图同时进行读取或写入操作,就会出现问题。假设我们有一个内核,它将单个值递增 1。
1 | |
当我们使用线程单个块启动该内核时,我们将获得存储在输入数组中的值 1。
1 | |
我们要处理的字符数约为 570 万个。让我们运行并记录迄今为止的三个版本。
1 | |
histo 是一个 128 元素的数组,位于 GPU
的全局内存中。在任何一个点上启动的每个线程都在尝试访问这个数组中的某些元素(即元素
arr[iarr])。因此,在任何一个点上,我们都有大约 128 × 32 ×
80 = 327,680 个线程试图访问 128 个元素。因此,平均约有 32 × 80 = 2,560
个线程在竞争同一个全局内存地址。
为了缓解这种情况,我们在共享内存阵列中计算局部直方图。这是因为
- 共享阵列位于芯片上,因此读写速度更快
- 共享数组对于每个线程块来说都是本地的,因此只有较少的线程可以访问并因此争夺其资源。
信息:我们的计算假设字符是均匀分布的。请谨慎对待此类假设,因为自然数据集可能不符合这些假设。例如,自然语言文本中的大多数字符都是小写字母,因此我们将有 128 × 32 × 80 ÷ 26 ≈ 12,603 个线程竞争,而不是平均有 2,560 个线程竞争,这会带来更多问题!
1 | |
之前有 2,560 个线程在竞争相同的内存,现在则有 2,560 ÷ 128 = 20 个线程。内核结束时,我们需要汇总所有本地结果。由于有 32 × 80 = 2,560 个区块,这意味着有 2,560 个线程在竞争写入全局内存。不过,我们确保每个线程只写一次,而之前我们必须写完输入数组的所有元素。
让我们看看新版本与旧版本的对比情况!
1 | |
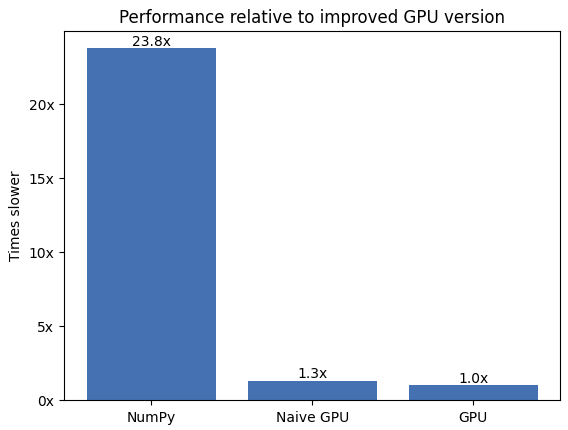
因此,这比原始版本提高了约 3 倍!
我们将块数设置为 32 × SM 数量的倍数,如上一个教程中建议的那样。但是哪个倍数呢?让我们来计算一下!
1 | |
如果 array[0] 的当前值等于
old(这是“比较”部分),则此函数将仅以原子方式分配val给array[0](这是“交换”部分);否则它现在将交换。此外,它以原子方式返回
array[0] 的当前值。因此,要锁定互斥锁,我们可以使用:
1 | |
因此,我们只会在 unlocked(0) 时分配一个 lock(1)。上面这行代码的一个问题是,如果线程到达它并读取到 1(锁定),它就会继续执行,这可能不是我们想要的。我们理想情况下希望线程停止执行,直到我们可以锁定互斥锁。因此,我们改为执行以下操作:
1 | |
在这种情况下,线程将一直持续,直到它能够正确锁定线程。假设线程到达先前锁定的互斥锁,其当前值为
1。因此,我们首先注意到,compare_and_swap无法锁定它,
因为
curr = 1 != old = 0。它也不会退出while循环,因为当前值
1 与 0(while
条件)不同。它将一直停留在这个循环中,直到它最终能够读取当前值为 0
的未锁定互斥锁。在这种情况下,它还将能够将 1
分配给互斥锁,因为curr = 0 == old = 0。
要解锁,我们只需原子地为互斥锁分配一个 0。我们将使用
1 | |
它只是原子赋值 array[idx] = val,返回
array[idx]
的旧值(原子加载)。由于我们不会使用这个函数的返回值,在这种情况下,你可以把它看作是一个原子赋值(即
atomic_add(array, idx, val) 对
array[idx] += val 的赋值与
exch(array, idx, val) 对 array[idx] = val
的赋值一样)。
现在我们有了锁定和解锁机制,让我们重试原子“加一”,但使用互斥锁。
1 | |
一切顺利!
在结束之前,我答应过要重温一下 cuda.threadfence。
摘自 CUDA "圣经"(B.5.内存栅栏函数):
__threadfence()ensures that no writes to all memory made by the calling thread after the call to__threadfence()are observed by any thread in the device as occurring before any write to all memory made by the calling thread before the call to__threadfence().
尝试翻译一下:
__threadfence()确保调用线程在调用__threadfence()之后对所有内存的写入操作,不会被设备中任何线程视为发生在调用__threadfence()的任何写入操作之前。
如果我们在解锁互斥锁之前忽略线程隔离,那么即使使用原子操作,我们也可能会读取过时的信息,因为其他线程可能尚未写入内存。同样,在解锁之前,我们必须确保更新内存引用。这一切都不明显,而且早在2015 年 Alglave等人首次提出之前就已经存在了。最终,此修复程序发布在 CUDA by Examples 的勘误表中,这启发了本系列教程。
小结
在本系列的最后一篇教程中,你学习了如何使用原子操作,这是协调线程的一个基本要素。你还学习了互斥模式,该模式利用原子来创建自定义区域,每次只有一个线程可以访问这些区域。
最后:
在本系列的四期中,我们涵盖了足够的内容,让你能够在各种常见情况下使用 Numba CUDA。这些教程并非详尽无遗,旨在介绍和激发读者对 CUDA 编程的兴趣。
我们尚未涉及的一些主题包括:动态并行(让内核启动内核)、复杂同步(例如,warp 级别、协作组)、复杂内存隔离(我们上面提到过)、多 GPU、纹理和许多其他主题。其中一些目前不受 Numba CUDA 支持,其中一些被认为对于入门教程来说太高级了。
为了进一步提高你的 CUDA 技能,强烈推荐《CUDA C++ 编程指南》以及Nvidia 博客文章。
在 Python 生态系统中,需要强调的是,除了 Numba 之外,还有许多可以利用 GPU 的解决方案。而且它们大多可以互操作,因此不必只选择一个。PyCUDA, CUDA Python, RAPIDS, PyOptix, CuPy 和 PyTorch是正在积极开发的库的示例。
Numba 的 CUDA 示例:原子和互斥

