为了提高我们的计时能力,我们将介绍 CUDA
事件及其使用方法。但在深入研究之前,我们将讨论 CUDA 流及其重要性。
Google colab
中的代码:https://colab.research.google.com/drive/1jujdw9f6rf0GoOGRHCvi82mAoXD3ufmt?usp=sharing
入门
导入并加载库,确保你有 GPU。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
import warnings from time import perf_counter, sleep import numpy as np import numba from numba import cuda from numba.core.errors import NumbaPerformanceWarning
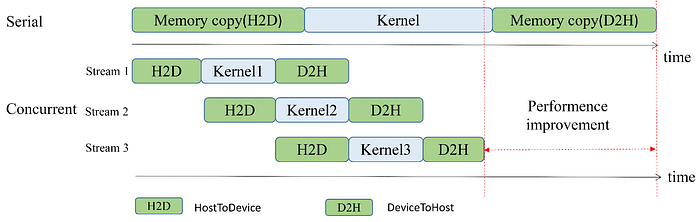
从此以后,代码就变得非常简单了。创建一个流,然后将其传递给我们想要在该流上操作的每个
CUDA 函数。重要的是,Numba CUDA
内核配置(方括号)要求流位于块维度大小之后的第三个参数中。
⚠️ 注意:
通常,将流传递给 Numba CUDA API
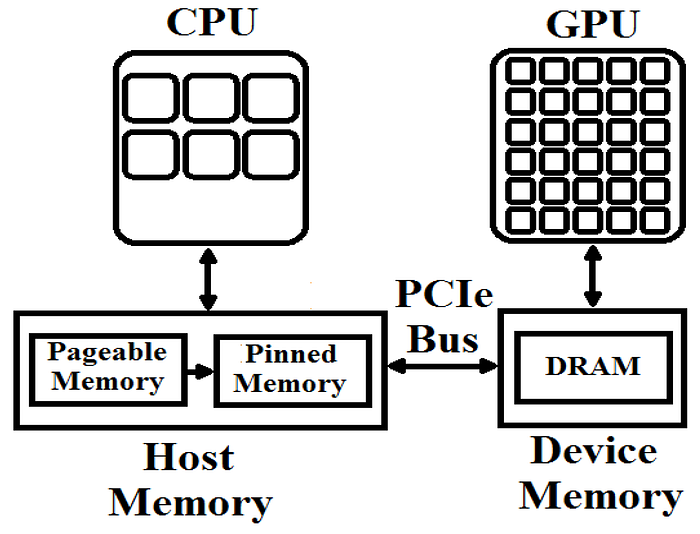
函数不会改变其行为,只会改变其运行的流。从设备到主机的复制是一个例外。调用
device_array.copy_to_host()(不带参数)时,复制会同步进行。调用
device_array.copy_to_host(stream=stream)(带流)时,如果device_array未固定,则复制将同步进行。只有在device_array固定并传递流时,复制才会异步进行。
toc = perf_counter() # Stop time of launches print(f"Launched processing {i} in {1e3 * (toc - tic):.2f} ms")
# 确保删除 GPU 数组的引用,这将确保在退出上下文时进行垃圾回收。 del dev_a, dev_a_reduce, dev_a_sum
tics.append(tic)
tocs = [] for i, (stream, arr) inenumerate(zip(streams, arrays)): stream.synchronize() toc = perf_counter() # Stop time of sync tocs.append(toc) print(f"New sum (array {i}): {arr.sum():12.2f}") for i inrange(4): print(f"Performed processing {i} in {1e3 * (tocs[i] - tics[i]):.2f} ms")
print(f"Total time {1e3 * (tocs[-1] - tics[0]):.2f} ms")
--- Old sum (array 0): 10000000.00 Old sum (array 1): 20000000.00 Old sum (array 2): 30000000.00 Old sum (array 3): 40000000.00 Old sum (array 4): 50000000.00 Old sum (array 5): 60000000.00 Old sum (array 6): 70000000.00 Old sum (array 7): 80000000.00 Old sum (array 8): 90000000.00 Old sum (array 9): 100000000.00 Launched processing 0in14.40 ms Launched processing 1in13.89 ms Launched processing 2in13.79 ms Launched processing 3in13.75 ms Launched processing 4in13.62 ms Launched processing 5in13.95 ms Launched processing 6in13.99 ms Launched processing 7in14.32 ms Launched processing 8in13.14 ms Launched processing 9in13.47 ms New sum (array 0): 1.00 New sum (array 1): 1.00 New sum (array 2): 1.00 New sum (array 3): 1.00 New sum (array 4): 1.00 New sum (array 5): 1.00 New sum (array 6): 1.00 New sum (array 7): 1.00 New sum (array 8): 1.00 New sum (array 9): 1.00 Performed processing 0in145.23 ms Performed processing 1in137.10 ms Performed processing 2in129.31 ms Performed processing 3in121.48 ms Total time 207.54 ms
toc = perf_counter() # Stop time of launches print(f"Launched processing {i} in {1e3 * (toc - tic):.2f} ms")
# 确保删除 GPU 数组的引用,这将确保在退出上下文时进行垃圾回收。 del dev_a, dev_a_reduce, dev_a_sum
tics.append(tic)
tocs = [] for i, (stream, arr) inenumerate(zip(streams, arrays)): stream.synchronize() toc = perf_counter() # Stop time of sync tocs.append(toc) print(f"New sum (array {i}): {arr.sum():12.2f}") for i inrange(4): print(f"Performed processing {i} in {1e3 * (tocs[i] - tics[i]):.2f} ms")
print(f"Total time {1e3 * (tocs[-1] - tics[0]):.2f} ms")
--- Old sum (array 0): 10000000.00 Old sum (array 1): 20000000.00 Old sum (array 2): 30000000.00 Old sum (array 3): 40000000.00 Old sum (array 4): 50000000.00 Old sum (array 5): 60000000.00 Old sum (array 6): 70000000.00 Old sum (array 7): 80000000.00 Old sum (array 8): 90000000.00 Old sum (array 9): 100000000.00 Launched processing 0in13.26 ms Launched processing 1in11.84 ms Launched processing 2in11.83 ms Launched processing 3in12.08 ms Launched processing 4in14.21 ms Launched processing 5in11.98 ms Launched processing 6in11.91 ms Launched processing 7in12.08 ms Launched processing 8in12.13 ms Launched processing 9in11.80 ms New sum (array 0): 1.00 New sum (array 1): 1.00 New sum (array 2): 1.00 New sum (array 3): 1.00 New sum (array 4): 1.00 New sum (array 5): 1.00 New sum (array 6): 1.00 New sum (array 7): 1.00 New sum (array 8): 1.00 New sum (array 9): 1.00 Performed processing 0in124.64 ms Performed processing 1in115.35 ms Performed processing 2in107.26 ms Performed processing 3in99.11 ms Total time 159.02 ms
但是哪一个更快呢?运行这些示例时,使用多个流时,总时间并没有得到一致的改善。造成这种情况的原因有很多。例如,要使流并发运行,本地内存中必须有足够的空间。此外,我们从
CPU 进行计时。虽然很难知道本地内存中是否有足够的空间,但从 GPU
进行计时相对容易。让我们学习如何操作!
信息:
Nvidia 提供了多种用于调试 CUDA 的工具,包括用于调试 CUDA
流的工具。查看Nsight
Systems了解更多信息。
事件
CPU 计时代码的一个问题是,它将包含除 GPU 之外的更多操作。
值得庆幸的是,通过 CUDA 事件可以直接从 GPU
获取时间。事件只是一个时间寄存器,它记录了 GPU
中发生的事情。在某种程度上,它类似于 time.time 和
time.perf_counter,但与之不同的是,我们需要处理这样一个事实:当我们在
CPU 上编程时,我们希望对来自 GPU 的事件进行计时。
因此,除了创建时间戳(“记录”事件)之外,我们还需要确保事件与 CPU
同步,然后才能访问其值。让我们看一个简单的例子。