柏拉图式表征:人工智能深度网络模型是否趋于一致?
人工智能模型是否正在向现实的统一表征演进?柏拉图表征假说认为,人工智能模型正在趋同。
麻省理工学院最近的一篇论文引起了我的注意,因为它提出了一个令人印象深刻的观点:人工智能模型正在趋同,甚至跨越了不同的模态--视觉和语言。"我们认为,人工智能模型,尤其是深度网络中的表征正在趋同",这是 The Platonic Representation Hypothesis (https://arxiv.org/abs/2405.07987)论文的开头。
但是,在不同数据集上针对不同用例训练的不同模型如何趋同?是什么导致了这种趋同?

柏拉图的洞穴寓言 Jan Saenredam(https://en.wikipedia.org/wiki/Allegory_of_the_cave#/media/File:Platon_Cave_Sanraedam_1604.jpg) 著
1.柏拉图表征假说
我们认为,在不同的神经网络模型中,数据点的表示方法越来越相似。这种相似性跨越了不同的模型架构、训练目标,甚至数据模式。

source: https://arxiv.org/abs/2405.07987
1.1 引言
论文的中心论点是,各种来源和模式的模型都在向现实的表征靠拢--即世界事件的联合分布,这些事件产生了我们观察到的数据,并用来训练模型。
作者认为,这种向柏拉图式表征的趋同是由模型所训练的数据的基本结构和性质以及模型本身日益增长的复杂性和能力所驱动的。随着模型遇到各种数据集和更广泛的应用,它们需要一种能捕捉所有数据类型中常见基本属性的表示方法。
1.2 柏拉图的洞穴
本文特别引用了柏拉图的《洞穴寓言》(Allegory of the Cave),以类比假设人工智能模型如何发展出对现实的统一表征,以及柏拉图关于感知和现实的哲学思想。在柏拉图的寓言中,洞穴中的囚犯只能看到投射在墙上的真实物体的影子,他们只相信这些影子就是现实。然而,这些物体的真实形态存在于洞穴之外,比囚犯感知到的影子更加真实。

2.人工智能模型是否趋同?
各种规模的人工智能模型,即使建立在不同的架构上,并针对不同的任务进行训练,在如何表示数据方面都显示出趋同的迹象。随着这些模型的规模和复杂性的增长,以及输入数据的规模和种类的增加,它们处理数据的方法也开始趋于一致。
针对不同数据模式(视觉或文本)训练的模型也会趋同吗?答案可能是肯定的!
2.1 会说话的视觉模型
这种一致性涵盖了视觉和文本数据--论文后来证实,这一理论的局限性在于它只关注这两种模块,而没有关注其他模态,如音频或机器人对世界的感知。LLaVA是支持这一理论的案例之一[1],它显示了使用双层MLP将视觉特征投射到语言特征中,从而获得了最先进的结果。
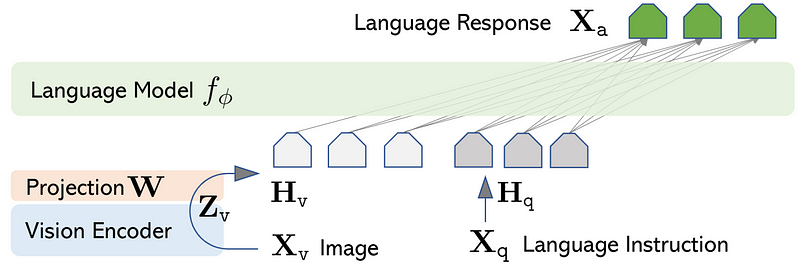
2.2 看得见的语言模型
另一个有趣的例子是《语言模型的视觉检查》[2],它探讨了大型语言模型理解和处理视觉数据的程度。这项研究使用代码作为图像和文本之间的桥梁,这是一种向语言模型提供视觉数据的新方法。论文揭示了 LLMs 可以通过代码生成图像,虽然这些图像看起来可能不太真实,但仍然包含足够的视觉信息来训练视觉模型。
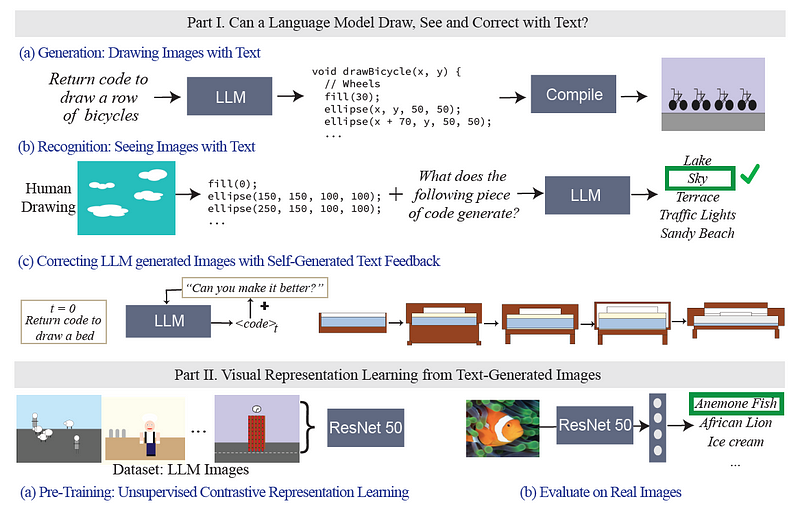
2.3 更大的模型,更大的排列组合
不同模型的一致性与它们的规模有关。举例来说,与较小的模型相比,在 CIFAR-10 分类基础上训练出来的更大模型之间的一致性更高。这意味着,随着目前建立十亿级和千亿级模型的趋势,这些巨型模型将更加一致。
"所有强模型都是相似的,每个弱模型都有自己的弱点"。
3.人工智能模型为何趋同?

人工智能模型的学习过程,\(f^∗\) 是训练好的模型,𝐹 是函数类,𝐿 是损失函数,取决于模型 𝑓 和来自数据集的输入 𝑥 ,𝑅 表示正则化函数,𝐸 表示对数据集的期望。每种颜色代表收敛的原因之一。Source:https://arxiv.org/abs/2405.07987
在训练人工智能模型的过程中,有一些因素对人工智能模型的收敛起到了最大的作用:
3.1 任务越来越通用
随着模型被训练来同时解决越来越多的通用任务,其求解空间的大小也变得越来越小、越来越受限制。更多的通用性意味着要努力学习更接近现实的数据点。
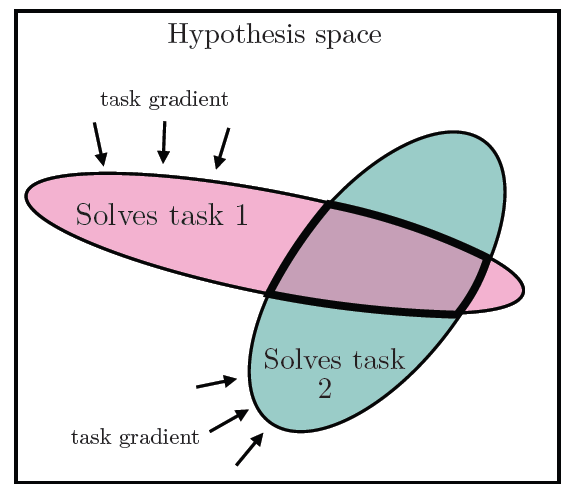
一个模型能解决的任务越多,它就不得不学习一种对解决所有这些任务都有用的不连贯表征。
Source:https://arxiv.org/abs/2405.07987
《柏拉图表象假说》一文将其表述为“多任务缩放假说”:
"能够胜任 N 项任务的表征要少于 M < N 项任务的表征。当我们训练出能同时解决更多任务的更通用的模型时,我们应该想到可能的解决方案会更少"。
换句话说,复杂问题的解决方案要比简单问题的解决方案狭窄得多。当我们在跨不同模式的巨大互联网数据集上训练越来越通用的模型时,你可以想象解空间将受到多大的限制。
3.2 模型越来越大
随着模型能力的提高,通过更复杂的架构、更大的数据集或更复杂的训练算法,这些模型会发展出彼此更加相似的表征。
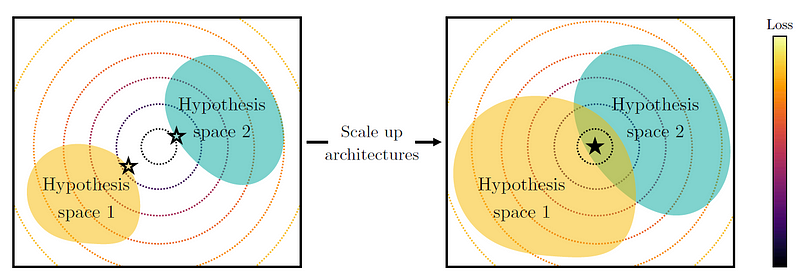
更大的假设空间比更小的假设空间更有可能找到解决方案。Source: https://arxiv.org/abs/2405.07987
虽然《柏拉图表征假说》论文并没有为这个被他们称为 "容量假说 "的假说--"大模型比小模型更有可能收敛到共享表征"--提供证明或例子,但似乎微不足道的是,大模型至少比小模型有更大的容量来提出互解空间。
随着人工智能模型规模的扩大,由于其深度和复杂性,它们具有更强的抽象能力。这使它们能够捕捉到数据的基本概念和模式,并消除噪音或异常值,从而获得更概括、可能更接近真实世界的表征。
3.3 简单性偏差
想象一下,在两个不同的任务上训练两个大规模神经网络:一个模型必须能够从图像中识别人脸,而另一个模型则被训练来解读人脸的情绪。起初,这两项任务似乎毫不相干--但如果这两个模型都趋向于用类似的方法来表示面部特征,你会感到惊讶吗?毕竟,这一切都归结于对关键面部地标(眼睛、鼻子、嘴巴等)的准确识别和解读。
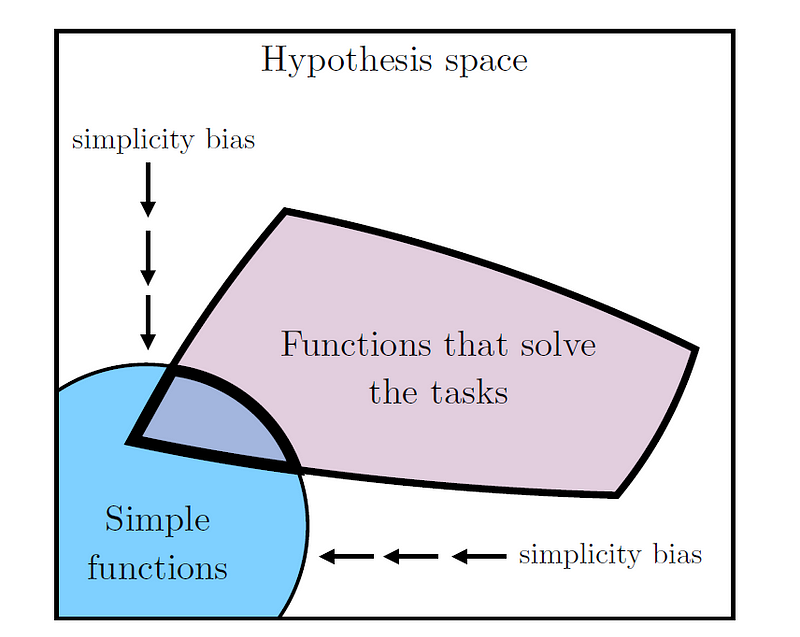
深度神经网络倾向于使用更简单的功能。Source: https://arxiv.org/abs/2405.07987
一些文献指出,深度神经网络倾向于寻找更简单、更通用的解决方案 [3,4,5]。换句话说,深度网络更倾向于简单的解决方案。本文通常称之为 "简单性偏差"(The Simplicity Bias):
深度网络偏向于寻找简单的数据拟合,模型越大,这种偏向越强。因此,随着模型变大,我们应该期望收敛到更小的解决方案空间。
为什么神经网络会出现这种行为?神经网络之所以表现出简单性偏差,主要是由于用于训练它们的学习算法的基本特性。算法倾向于选择更简单、更具有泛化能力的模型,以此来防止过拟合并增强泛化能力。在训练过程中,更简单的模型更容易出现,因为通过捕捉数据中的主要模式,它们能更有效地最小化损失函数。
在训练过程中,简化偏差起到了自然调节器的作用。它将模型推向表示和处理数据的最佳方式,这种方式既能通用于各种任务,又足够简单,可以高效地学习和应用,从而增加模型学习相互假设空间的机会。
4.这种趋同的影响
模式趋同又如何?首先,这表明不同模态的数据可能比以前想象的更有用。根据预训练的 LLM 微调视觉模型,或者反之亦然,都会产生令人惊喜的好结果。
论文指出的另一个含义是 "扩展可能会减少幻觉和偏差"。其论点是,随着模型规模的扩大,它们可以从更大、更多样化的数据集中学习,这有助于它们对世界形成更准确、更稳健的理解。这种强化的理解使它们能够做出预测,并产生不仅更可靠而且更少偏差的输出结果。
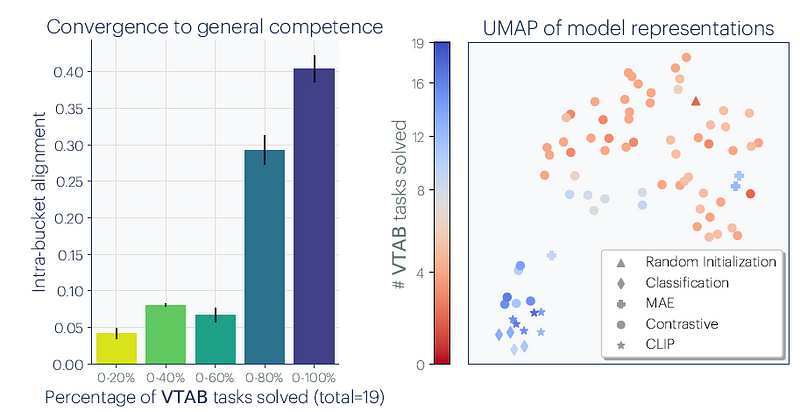
随着能力的提高,VISION 模型会趋于一致。Source: https://arxiv.org/abs/2405.07987
5. 需要斟酌
说到论文提出的论点,你必须考虑到一些局限性,几乎所有这些局限性论文也都提到了。
首先,论文假设了现实的双射投影,其中一个现实世界的概念 Z,有可以学习的投影 X 和 Y。然而,有些概念是独一无二的固有模块。有时,语言可以表达许多图像无法表达的概念或感觉,同样,语言也可能无法取代图像来描述视觉概念。
其次,如前所述,本文主要关注两种模式:视觉和语言。
第三,"人工智能模型正在趋同 "这一论点只适用于多任务人工智能模型,而不适用于特定的人工智能模型,如 ADAS 或情感分析模型。
最后,虽然论文显示不同模型之间的一致性在提高,但这并不表明模型的表征变得相似。大型模型之间的一致性得分确实高于小型模型,但 0.16/1.00 的得分仍然给研究留下了一些悬而未决的问题。
柏拉图式表征:人工智能深度网络模型是否趋于一致?

