06. BI - 量化交易,简单的炒股策略实现

[TOC]
Hi,你好。我是茶桁。
上一节课中,咱们详细的分解了 Fintech 的应用场景,也是将相关的一些业务给大家好好的梳理了一遍。
那么本节课中,咱们来一起做一个实战,关于 Python 的量化交易的一个板块。
先来了解一下咱们用到的工具,首先必须是 Python,Python 的数据会放到一个数据表里面,结构咱们用的是 dataFrame。以前介绍过,dataFrame 就是 Pandas 这个包内的数据格式。
在之前的 Python 基础课程有详细的给大家梳理过 Pandas,有相关基础不太好的小伙伴可以回过头去再好好看看我那一篇内容 27. Pandas。
Rolling 函数
这里咱们要用到 dataFrame 内的一个相关函数,rolling,
这是一个窗口的滚动,设置了时间窗口的大小,可以帮你去滚动几个窗口的数据。
1 | |
这其中,window 是时间窗的大小,即向前几个数据(可以理解将最近的几个值进行 group by)
min_periods,最少需要观测点数量,默认与 window
相等。
center,把窗口的标签设置为居中,布尔型,默认 False
on, 可选参数,制定要计算滚动窗口的列,值为列名。
我们一起来生成一些模拟的数据:
1 | |
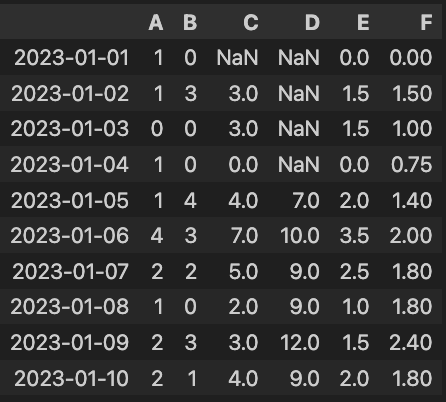
现在生成了一些模拟的数据, 然后把 B 列最近的两个值来进行相加,形成了 C
列,那 D 列是 5 个值进行相加。这两个都是在 B 列的第一个值 0
再向上多数了一个值,所以都是 NaN。然后咱们的 E,F 是求平均值,我写了一个
min_periods=1,这样的话就说它只要有一个值也可以做,mean
是求了一个平均数。
所以咱们来看 E 和 F,前面一个都是 B 里面的 0 来求平均值,那自然还是 0。E 的第二个值是 3/2,第三个值是 5/2, 而 F 第二个值也是 3/2,可是第三个值是 5/3,依次往下类推。
关于这个 Rolling 的函数是帮你去提取窗口特征。举个股票的例子,不知道大家有没有炒股的。炒股里面有个均线的设置叫 MA,比如 MA10,代表 10 天的平均值。为什么取 10 天的时间或者是多天的时间?因为取一天抖动会剧烈,所以在股票里面会有个 MA10。MA10 就是代表过去 10 天的一个平均数,如果用了过去时间的平均数就会更加的均和,更加的平均,所以它也是一个统计量的一个特征。通常会采用窗口里面的统计特征帮你来做股票的决策。
如果只看过去一天的数字很容易激进,因为过去一天有可能抖动很强。只要抖动强,不代表它的信号一定是上涨的,它有可能马上落下来了,所以 MA10 相对来说会更加的平缓,更加过滤掉一些市场上的噪音,它才能代表的一个趋势向。这就是 Rolling 窗口的函数作用。
JQDataSDK
股票的数据又从哪来呢?股票的数据要有一些专业性的软件,现在用一个工具叫 JQData, 这个工具就是一个 Python 开源的包。
1 | |
首先是需要你去授权,这个数据虽然是开源免费的,但是它有接口次数的要求,如果你是一个非常高频的,一天有几十万上百万的访问请求还需要付费来进行处理。对于学习来说的话这些访问的次数是完全足够用的。
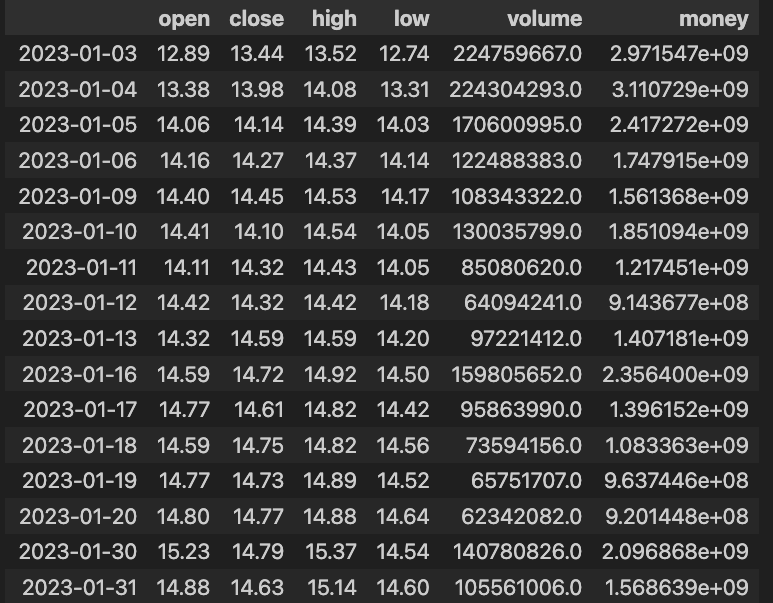
JQDdata 不光是可以帮你获取到基本的这个信息,有开盘价、收盘价、最高、最低的一些历史数据,还有 volume,就是交易量有多少。还可以帮你去计算额外的指标,这个股票的倍数、p 的倍数、市值、market cap、板块的信息等等。有了这个信息就可以帮你筛选一些股票。
1 | |
可以看到我在进行授权之后,尝试查看了一下我的使用情况。每天 100W
条,基本上是绝对够用了。之前调用过接口获取了相关数据,咱们获取的是股票编码
000001,也就是平安银行从 2023 年 1 月 1 日到 4 月 1
日的一个数据。
然后我们还可以查看这只股票一些其他的数据。
1 | |
可以看看这个属性都有哪些, 这支股票里面它的 PB, PS 等等。这些指标代表的是它的一些股票计算的因子。比如说 PE 就是市盈率的一个倍数,PS 应该是营收的倍数,market_cap 是市场的一个估值。
关于股票趋势的预测有很多特征是当前才知道,比如今天最高价、最低价、交易量,这些怎么划分数据集才能建立起来对未来一段时间趋势的预测呢?当天知道的是当下的时间。股票趋势预测一定是基于过去,历史数据也是有的。所以首先你过去一段时间的一个历史是可以做,这里有很多种模型。
未来预测时刻不能仅仅是当天的,还有过去的一段时间。有很多时间序列的模型,在后续课程里面会教给大家时间序列的一个使用方法。比如说有 ARMA、ARAMA 这些方法。过去 60 天就可以预测未来比如说 6 天它的股票价格。
所以建模是 OK 的,除了 ARMA 以外还有一些持续模型,可以做多个特征的预测。包括像 LSTM,长短记忆网络等等,这些过程在后续的课程里面都会教给大家去做。今天是教给大家一些简单的一些方法,并没有特别难的一些处理。今天的一些方法就是怎么样去获取一些数据。
还有就是我这里有一份数据,包含了所有股票 5 年的数据。不过已经都是之前的数据了,并不是最新的。是一份 2013 年到 2018 年之间的股票数据,大概有 100 多支股票。要是用这份数据当然也是可以的,这份数据我还是会放在文末。
可以筛选一下行业,股票是跟行业相关的,行业有哪些可以看看:
1 | |
每支股票都属于其中一个行业,比如说你想要看跟计算机相关的行业有哪些就专门去做一个输出,
1 | |
它的代码是 C39, 这是跟计算机相关的行业。这样可以筛选出来跟计算机行业相关的股票。那怎么筛呢?我们已经知道它的代码是 C39,可以专门去写一个 C39, 然后把这个股票的值得给它打印出来。
1 | |
C39 是计算机相关行业股票,数据也比较多,一共有 558 只股票。
更具体的一些内容,大家可以查阅一下官方的手册来看看具体怎么使用:https://www.joinquant.com/help/api/help#JQData:%E4%BB%8B%E7%BB%8D%E4%B8%8E%E8%AF%B4%E6%98%8E
yfinance
如果你想要使用这个工具可能需要自己来注册个账号就可以了,也可以使用咱们文末分享的那个数据,拿这个数据去做一个练习也是可以的。
除了 jqdata
以外,还有一些这个开源的工具是不需要账号密码的,也可以获取一些数据。我们可以使用
yahoo 的财经工具来获取数据,这个包之前是为了修复
pandas_datareader 使用 get_data_yahoo()
可能出现获取数据出错,那么就有了 fix_yahoo_finance
工具包用来修复获取数据的问题。之后, fix-yahoo-finance
更名为 yfinance,但是使用还是没什么变化:
1 | |
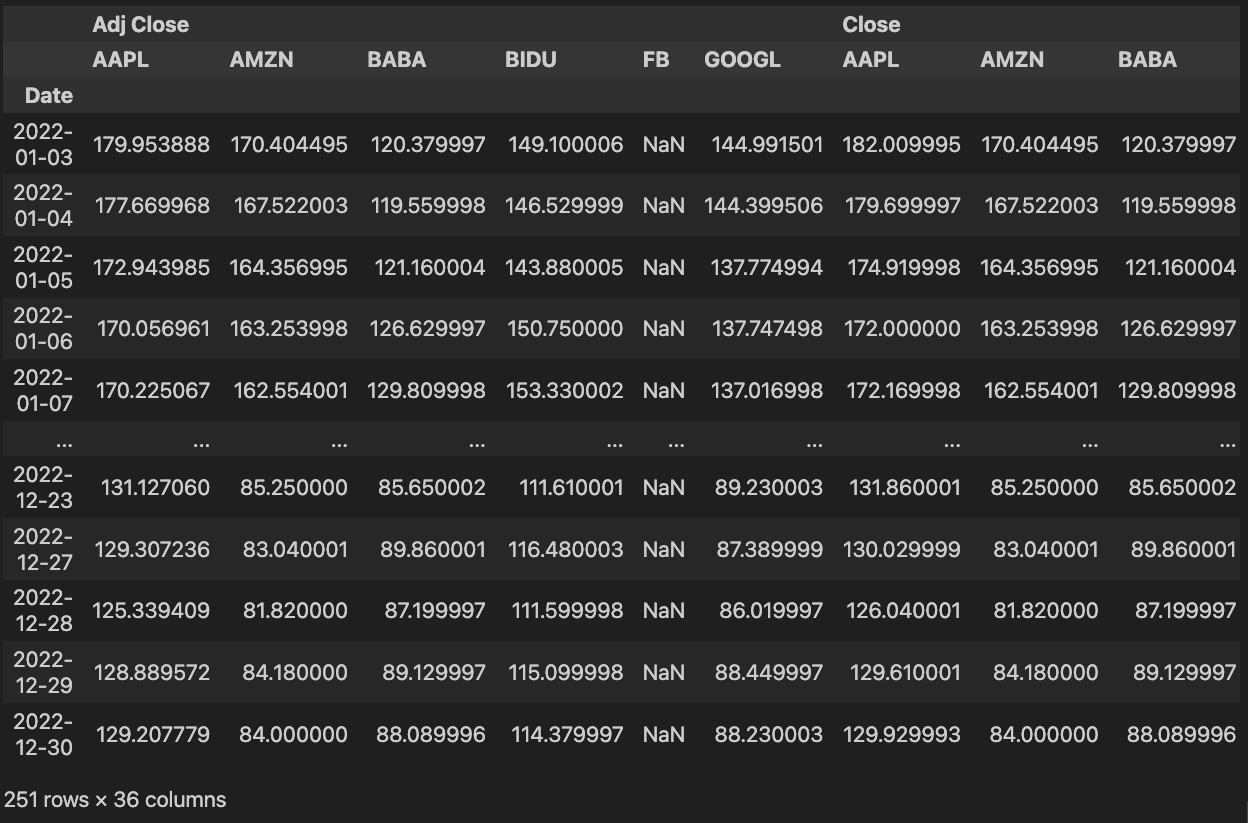
我们只要 download
这些数据就可以了,它后面股票代码会有一点小区别,如果你是上海的股票的话是
.SS,深圳股票的话是
.SZ。比如浦发银行的代号就是 600000.SS,
深发展的代号就是 000001.SZ,这是雅虎的使用方法。
我们看的股票是去年 1 月 1 号到 12 月 31 号,六支股票可以一次下载下来。可以看到这六支股票的收盘价,交易量,开盘价等等,所有的数据都出来了。
那其中 251 是代表什么呢?为什么去年他只有 251 行?这是一个交易日的情况。一会儿还会用到一个程序帮你画一个 MAC 地图,对 251 个交易日.
我们想要去模拟一些股票的情况,这是 2013 年的 2 月份到 18 年的 2 月份的 505 只股票的数据。就是给大家提供的五年的时间那个数据,是一个已经下载好的数据。模拟的过程中初始资金是 1 万,要制定一个策略,对股票来进行买卖,最后计算一下它的 2017 年 12 月 29 号的资金和投资回报率。
这是一个模拟的情况,该怎么去模拟?
模拟交易
17 年的 1 月 3 号是 1 万块钱,年底的时候投资回报率是多少。数据只能是看历史数据,假设看过去一年,把过去一年涨幅情况来做个排序,涨幅最高的那个追涨的策略,就是把涨幅最好那个策略全仓进行购买。然后计算一下投资组合的一个回报价值。
我们会有以下的一些函数帮你去完成。
1 | |
用的一个字典去存储一些信息,比如说 cash 这里代表的是你当下资金的一个数量是 1 万块钱。策略比较简单,就是找一个在 16 年表现的最好的股票,然后 1 万块钱的全仓。那这一年间我啥都不做,就是在 1 月 3 号就购买,购买以后看一下 12 月 29 号的投资回报率。
想想这个投资投标率会好吗?不一定,有可能好也有可能不好。主要是看这个股票在下一年的表现是怎样的。
首先,我们需要引入一些包:
1 | |
在 Python 里面比较常见的 Pandas, NumPy, 画图的包,时间的包。
然后我们来读取一下数据
1 | |
这五年数据去做个模拟,数据在文末去获取。这是所有的股票,股票的数量比较多,一共是有 619,040 行数据。
我们可以对数据来做一个探索,并且进行整理:
1 | |
它一共有多少只不同的股票,505 只。也可以对股票的数据去求取一下前几行的一个数据,通过 head 方法去看,都有哪些特征。
1 | |
接着,我们来看看交易日的情况,看看这 5 年时间有多少个交易日:
1 | |
这 5 年时间交易日大概有 1,259
个,把这个交易日to_datetime一下。这个是转化为 pandas
中的日期类型,这个使用情况的话也是比较多的,在 pandas
里面使用的日期类型基本上都是to_datetime来进行转化:
1 | |
咱们主要是想要做一些股票的一些模拟。要筛选某一支股票可以通过 name 来进行筛选,比如可以筛选 AAPL 这只股票:
1 | |
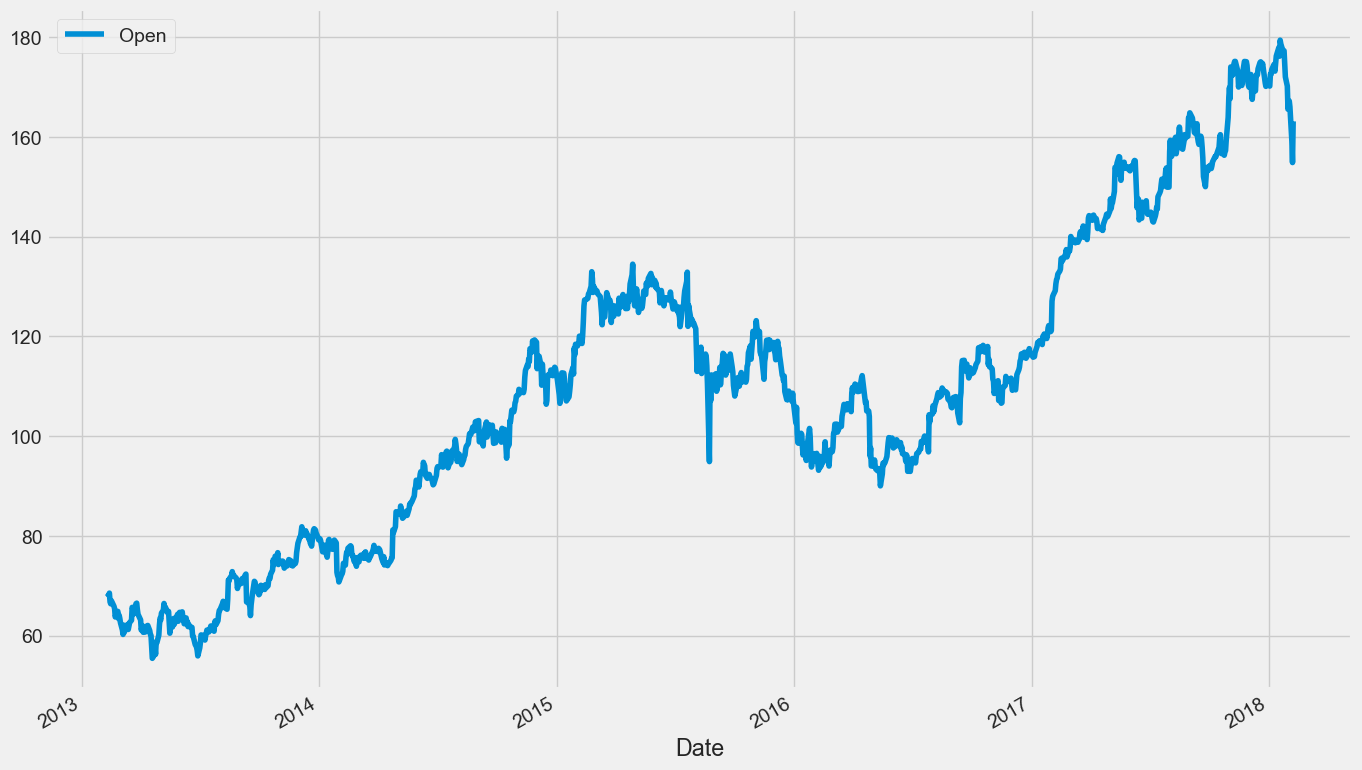
筛完以后我们还把这股票做了一个可视化,按照时间,刚才已经转换好的时间和开盘价来做一个获取。可以看到 Apple 这支股票随着时间应该是逐渐上涨的,确实它的表现还是不错。
然后咱们开始写函数,这个函数的目的是计算一下投资组合目前所带有的一个价值。
1 | |
这个函数逻辑就是统计每一支股票的一个价格, 然后做累加。
也可以写一个函数进行购买,购买就是在资金里面减去你购买的金额,然后在拥有股票里面把购买到这个份额给它累加到一起:
1 | |
卖股票的逻辑就是先看你有没有持仓这支股票, 如果没有持过这个股票就无法卖掉。你卖的股数如果大于你手上持有的数量也没法卖, 只有小于等于你现在手上的股才能卖掉。
1 | |
以上三个函数的逻辑一个是卖,一个是买,一个是计算仓位所持有的股票的价值。这三个函数你可以把它理解成是一个股票策略的模拟环境,需要的一个基础信息。
下面就是设置交易策略的一个初始状态了,初始状态是 1 万块钱,所以给它建了个字典:
1 | |
字典打印出来,开始等于 1 万。如果要买两支股票,这两支股票分别是 AAPL 和 Google,在 1 月 4 号买 10 股,可以看看:
1 | |
然后现在是 APPL 10 股, GOOG 10 股,cash 减少了,变成了 1,000 多。因为原来有 1 万块钱,然后看一下当下今天的情况:
1 | |
买入的话,假设是从开盘一早就进行购买,晚上的时候涨了 15 块钱,证明还是赚了一点点。
卖股票也可以按照刚才这个策略来进行售卖,在 2 月 1 号的时候把它卖掉了。
1 | |
但是我们写的代码在这里并不能进行卖出,为什么?因为我所拥有的 AAPL 10 股,这里要卖 20 股,那肯定卖不出去。
好卖不出去没关系,在 2 月 1 号的时候我们股票的市值是多少?
1 | |
达到了 10,788,涨了 7%。
以上就是一些模拟软件的一些策略,在后面我们要筛选一些股票,筛选出来一定的年份。我们这里找的是 2016 年全年的信息,505 只股票全年的情况做一个筛选, 那我们现在的第一个策略就是,2016-2017 年,按照过去 1 年涨幅排序,直接全仓购买最好的.
1 | |
这么多股票当中,我们想要找的是一个最好的情况。用什么方法把 2016 年全年的股票都做了一个判断,从最开始的时间到最大的时间
1 | |
最小的时间到最大的时间做个筛选, 然后 close 减去 open 再除以
open。这样我们可以找到它的增长率,增长率如果要更高的话就把它保存起来。我们用的方法叫做打擂方法,寻找best_stock。就是在
2016 年的最好股票,打印出来。
这个方法是比较常用的方法,叫打擂法,可以找到最优解。通过计算我们可以发现,应该是一个叫 AMD 的股票在过去 2016 年全年的时间是效益是最好的。这股票涨了 322.383 百分比,涨很猛啊,涨了 3 倍,一年时间翻 3 倍,这个投资回报率真的是很棒。
如果你能把选股做好的话,基本上应该稳赚不赔的事情。那如果我们在 2017 年想全仓持有,重仓持有,那要计算一下你能买多少股:
1 | |
购买的时刻是 2017 年的 1 月 3 号,那这种策略是个好策略吗?我知道有些人喜欢追涨。策略没有好坏之分,只有适合与否。在某个时间段它有可能就是好策略,但是同样的策略在某时间段有可能就不好。
我们假设从 1 月 3 号开始买,买的是 AMD 这只股票,看一下能买多, 能够买 875 股。
去购买使用的是刚刚写好的那个portfolio_buy这个函数,拿它来进行购买.
1 | |
它原来等于 1 万,购完以后只剩 7 块 5 了,就没剩下什么钱了。然后我们再看一下 12 月 29 号的一个股票价值剩多少呢?
1 | |
剩了 9,000 块钱。所以大家可以看一看这个追涨特别好吗?如果你一直没有抛的话,在 2017 年的年底你可能会亏 10%。这个策略其实一直持有的话在那一年并不是个好策略。
我们统计一下 2017 年所有交易日,看一看这个股票随着不同交易日的时间的变化是怎样的。年底的时候是亏的,那年中有没有可能找个适合点去抛掉会挣钱呢?可以做一个分析
1 | |
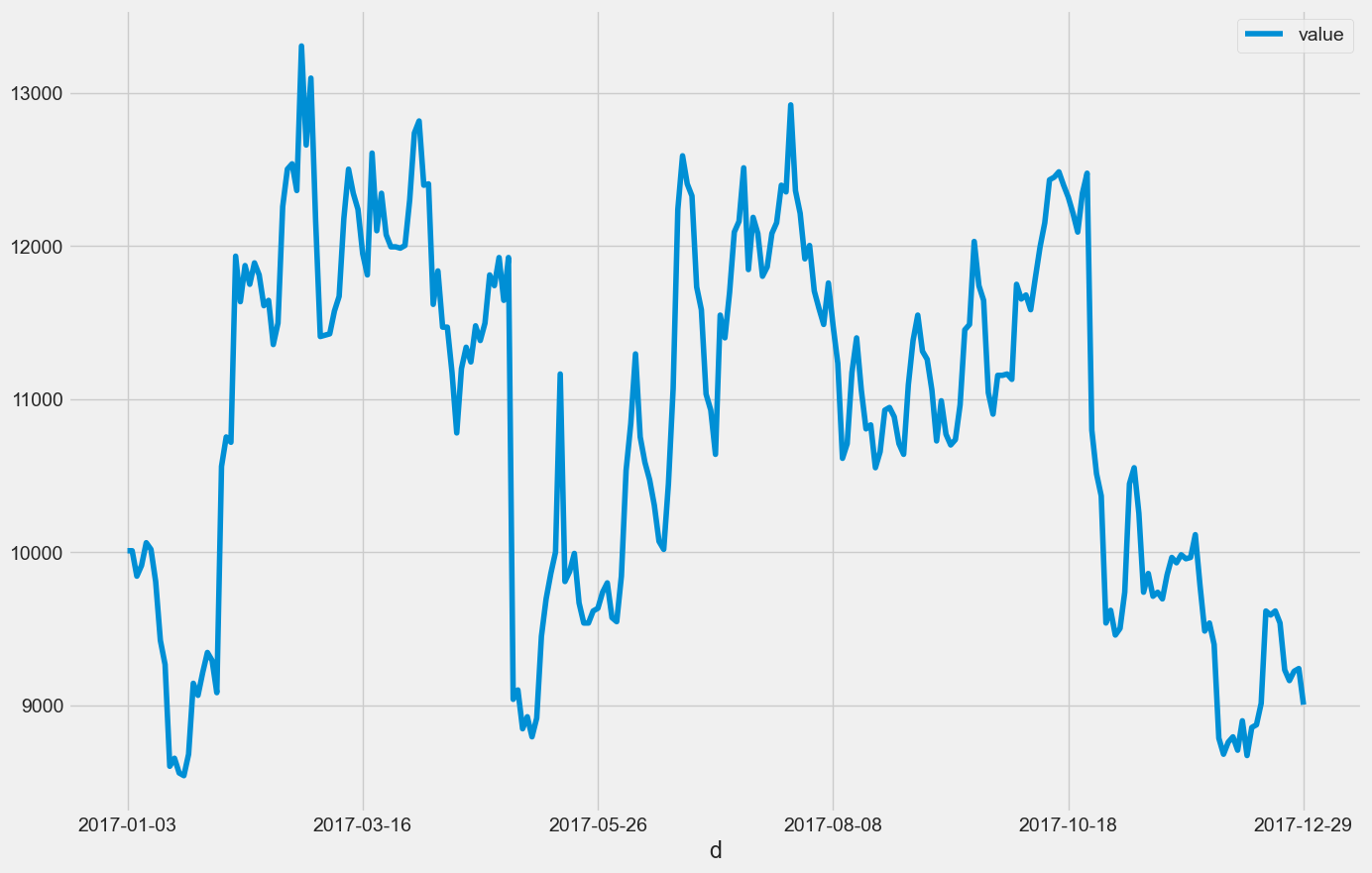
最后把这股票打印出来,这里是使用了一个获取投资组合,就是计算他在交易日的价值。你看这个价值还是有升的,同时也有降的情况。把这个价值整理出来以后给它画出来。可以看到有的时候曾经达到了 13,000 美金,就是涨了 30%。中间如果没有抛的话,最后有可能就套住了,套住 10%。
这个工具是通过 pandas 来去做模拟,那使用的方法其实并不难,都是通过 pandas 来去做了核心。就是我们能有一个简单的模拟环境可以帮你来去买卖股票。花钱买股票然后在适适当的时刻进行售卖,最终我们希望能找到一个策略,帮你来去制定一个好的交易策略,从而可以让你赢的更多。
5 年股市数据
链接: https://pan.baidu.com/s/1otDWJef6Zx6JTLXikcUVJA?pwd=jvfv 提取码: jvfv --来自百度网盘超级会员 v7 的分享
06. BI - 量化交易,简单的炒股策略实现

