08. BI - 万字长文,银行如何做贷款违约的预测,特征处理及学习
本文为 「茶桁的 AI 秘籍 - BI 篇 第 08 篇」

[TOC]
Hi, 你好。我是茶桁。
课程回顾
上节课,咱们讲了一个股票的指标:MACD。在趋势行情里面它应该还是有效的指标。它比较忌讳动荡行情,比如说它一会上升一会下降,那还没有等 12 天过完,就是均线还没有画好它又马上变成了另一个行线,这样 MACD 有可能会失效。
这个问题我们大家自己去思考一下,如果你采用这个策略在过去一段时间里面选择一些股票来进行购买的话,能不能让它的收益率大于 60%?有这种可能性,选好股的话确实在过去一年交易里面收益率是有可能大于 60%。
那我们之前的课程里,带来了 Fintech 的应用场景,同时又对其中一个量化交易的场景做了一个简单实验。今天,咱们来另一个 Fintech 的场景,同样也是有数据,这个数据是来自于一场比赛。
这个比赛是关于贷款违约预测的一个比赛,来,我们一起回想一下,在这个 BI 系列课程开始的几节课里咱们讲的模型、机器学习的神器。大家还记得是哪两个神器吗?其实严格来说的话应该是三个神器。
XGBoost 是第一个,LightGBM 是更快的,还有一个是跟分类相关的 CatBoost。 ## 案例分析
接下来,我们来看一个问题:
零基础入门金融风控-贷款违约预测
这里有 47 个指标,120 万贷款记录。其中 15 列为匿名变量,并且对 employmentTitle、purpose、postCode 和 title 等字段进行了脱敏。
给你两个数据集, 一个是训练集,一个是测试集:
训练集为 train.csv 测试集为 testA.csv 提交格式 sample_submit.csv
我这里就不提供数据了,有需要的可以用阿里云帐号自行去获取:
https://tianchi.aliyun.com/competition/entrance/531830/information
我们来看看字段:
| 字段 | 说明 |
|---|---|
| id | 为贷款清单分配的唯一信用证标识 |
| loanAmnt | 贷款金额 |
| term | 贷款期限(year) |
| interestRate | 贷款利率 |
| installment | 分期付款金额 |
| grade | 贷款等级 |
| subGrade | 贷款等级之子级 |
| employmentTitle | 就业职称 |
| employmentLength | 就业年限(年) |
| homeOwnership | 借款人在登记时提供的房屋所有权状况 |
| annualIncome | 年收入 |
| verificationStatus | 验证状态 |
| issueDate | 贷款发放的月份 |
| purpose | 借款人在贷款申请时的贷款用途类别 |
| postCode | 借款人在贷款申请中提供的邮政编码的前 3 位数字 |
| regionCode | 地区编码 |
| dti | 债务收入比 |
| delinquency_2years | 借款人过去 2 年信用档案中逾期 30 天以上的违约事件数 |
| ficoRangeLow | 借款人在贷款发放时的 fico 所属的下限范围 |
| ficoRangeHigh | 借款人在贷款发放时的 fico 所属的上限范围 |
| openAcc | 借款人信用档案中未结信用额度的数量 |
| pubRec | 贬损公共记录的数量 |
| pubRecBankruptcies | 公开记录清除的数量 |
| revolBal | 信贷周转余额合计 |
| revolUtil | 循环额度利用率,或借款人使用的相对于所有可用循环信贷的信贷金额 |
| totalAcc | 借款人信用档案中当前的信用额度总数 |
| initialListStatus | 贷款的初始列表状态 |
| applicationType | 表明贷款是个人申请还是与两个共同借款人的联合申请 |
| earliesCreditLine | 借款人最早报告的信用额度开立的月份 |
| title | 借款人提供的贷款名称 |
| policyCode | 公开可用的策略_代码=1 新产品不公开可用的策略_代码=2 |
| n 系列匿名特征 | 匿名特征 n0-n14,为一些贷款人行为计数特征的处理 |
现在我们想要评估它,可以看一下到底哪一个是我们的 label? 贷款的
id、金额、期限、利率、等级等等,这些都是业务指标。最后有一个匿名特征,15
个。还有一个isDefault,代表违约,1 是违约,0
代表是正常。所以我们预测词段应该是最后一个词段叫isDefault。
这是一个什么问题?我们可以思考一下,这是机器学习里面非常经典的一个问题,叫做分类问题。确切说这是个二分类问题,那么二分类问题可以提交结果是 0 和 1,也可以提交一个概率。如果你提交概率,评价指标是 AUC提交哪一个会更好?是提交 0 和 1 具体的分类结果好,还是提交一个概率结果。如果预测出来是个概率值的话,把它转化成了 0 和 1,有可能 AUC 是不高的,这是一个小的技巧性的问题。所以建议大家是以概率值来进行提交。
0 和 1 是实际的结果,从这个物理含义上来说的话它确实有违约和不违约两个最终的结果。但是我们要去预测,你做分类任务也可以得到一个概率值,这概率值是 0.95,就是他违约概率是 95%,还比较高。0.06 就是他不太违约,可以写 0 和 1,也可以写上它的概率值。概率值通常情况下 AUC 的结果会更大,就是你的排名会更靠前。
这些可以自己做个对比,因为它本身是一个在线的比赛,你可以把它转化成为一个分类结果再去看一看 AUC 会变成多少。
题目就是这样一个题目,去预测一个二分类的任务,是个跟贷款违约相关的场景。除了我们要知道这种分类模型可以用 XGBoost 的 LightGBM 以外,关键是要统计它的一些特征。
梳理一下整个过程,第一个要做数据加载,前期数据探索,探索一般来说我们要看字段 label,跟 label 相关的,还有就是有没有缺失值,唯一值的个数也可以做一些探索。
sns.countplot()函数,以 bar
的形式展示每个类别的数量。
探索以后可以做一些预处理,中间如果有缺失值要在模型里面进行补全,补全也会分两种情况,第一种情况叫做数值特征:num_features,第二种叫做类别特征:
cat_features。
以年龄为例,就是一个具体的数字。还有一个叫做收入,类似这种跟钱相关的指标用什么样的方式来做补全?两种方式,一般平均值和中位数。我个人更倾向于使用中位数。
举个例子,我们回头看一下刚才字段里的贷款金额,不同人的贷款金额可能不一样。不知道有没有人尝试过网络贷款,跟金额相关的其实差别是比较大的,均值会偏高,你想你借 500 块钱、1,000 块钱,有也会有人在贷款软件上借 20 万、30 万。这种如果你放到均值里面,差别会特别大。
再举个场景,收入,你们公司的收入平均收入是多少?如果你把马云放进去,你想想马云的收入高不高?一下子平均收入个人都是上亿的,这样大家都变成了异常值。
所以收入字段这种字段是不能用平均值的,用平均值做补全是没有意义的。因为那个缺失的值很有可能不是马云,你被平均了。所以用的是中位数,中位数会更加的过滤异常值,金额可以用中位数补全。
除了收入以外,一般来说年龄这种平均值差别不会太大。你可以自己做个实验,基本差不多。
第二种是类别特征,那众数在类别特征里做补全比较好,因为在类别特征里面不是一个连续值。
举个例子,gender 代表性别,请问性别能用平均值补全吗?肯定不行。因为性别只有两种情况,所以两种情况我们要找到那种情况最大的,如果他男性居多,我们的补全可以倾向于用男性来去做补全。
所以在类别特征里面一般来说是用众数好。
这是前期的数据处理,类别特征在整个程序里面还要做一个处理叫做数值编码。因为类别特征它原来是字母类型,数值编码有一个工具叫做labelEncoder,这个叫做标签编码,标签编码可以自动帮你进行标签。但有些情况下,有些类别是有方向的,什么是类别方向呢?
有一个叫做贷款等级:grade,贷款等级有方向之分,大小从
a、b、c、d、e,a 可能是优质的,e 可能是劣质的。贷款等级还不能直接让他用
labelEncoder,需要自己去写一个映射关系。
日期类型的处理,日期在数据集里面经常会出现,一般怎么处理呢?举个场景,2023 年的 7 月 5 号这是个日期,直接把它喂到模型里面是不能用的,我们要抽取出来它一个多尺度特征,多尺度可以按照年月日分别抽取出来,2023 一个特征,7 月一个特征,5 号一个特征。
那我们思考一下,还有没有其他多尺度特征可以抽取?那今天是周六(以我写这篇文章的日期问准,而非发布),周六在整个的时间里面也算是一个特殊的时间,你可以把这个特征叫做 weekday。还有哪个特征?是不是还可以再取一个叫做 holiday,或者叫 workday。因为有些周六它是个工作日。
所以从业务场景出发,weekday 是周几,还可以出一个叫 workday 或 holiday 来判断到底是工作还是不工作,这些也都有关系。可能跟贷款违约没啥关系,但是跟什么交通流量,或者跟商业里面的销售都是有关系的。举个例子,比如说电影票房就是个最明显的区别,工作日不会很高,但是假日的话是工作日的可能几倍都不止。
除了这种类型处理的方式我们还有一种处理的方法,我们把它称为 diff, 就是 different。
我们的日期可以做一个锚点,以一个最小值为例,什么时候开始的这项业务,假设是 2023 年的 1 月 1 号这个业务开始的,那么现在是 2023 年的 11 月 28 号,相比 1 月 1 号来说就会存在一个时间的 diff,这样就会把它转化成一个数值类型,也是一个统计特征。
所以时间类型有两种处理方式,一种叫做时间多尺度,一种叫做时间 diff。
这个方法还是比较常见的,未来你们在工作和比赛过程中遇到时间类型放到模型之前,都要采用这样的处理的方法。不一定两种策略都用,但是至少,如果要放时间特征的话,要用其中的一种。要不你用多尺度,要不你用时间 diff,否则这个时间是不能直接放到模型里去的。
那这个数据集里面就有跟时间类型相关的数据,比如说有个issueDate,贷款发方月份,这个是时间的,所以一会儿我们要采用提到的方式来进行处理。
然后就是第四个步骤了,我们要进行特征构造。大家要明白,模型的使用不是难点,因为大家都会用 XGBoost 和 LightGBM,参数也都是那些,区别在于前期的特征构造。我们之前有句话叫做特征决定模型的上限,而模型只是把上限跑出来而已。那么在特征构造里面有哪些技巧呢?特征构造里面有一些统计学的一些技巧。
对于那些类别变量的一些特征来说我们可以做一些统计的特征,代表这个类型的一些属性。
举个例子,比如说贷款等级我们有
a、b、c、d、e,是按照分组的方式。这个分组你可以数一下分组的个数,还可以把贷款等级和违约概率isDefault分别做一个对应。a
是 0,b 是 1...
这种对应到底是好还是不好我并不清楚,但是能把 a 的 default
的平均值计算出来,应该按照分组的方式求一下isDefault这个统计变量的平均值就好了,b、c、d、e
也都能算。算完以后就可以把它叫做grade_isDefault_mean。你加这个字段,假设
a 是 0.01,就是它的平均值。b 假设是 0.02,c 是
0.03,这样我们就可以给它统计一个特征出来,
就是说我们可以对每一个特征去跟我们的isDefault来做关联,做完关联以后就可以方便你去理解这个特征的一个含义。需要说明一点,这个特征一定是属于类别变量,
因为类别变量是一个离散的个数,它在贷款里面假设类别 a、b、c、d、e 只有 5
种,那只有 5 种每一种它的isDefault平均值才有价值。
如果它不是类别变量是一个数值变量,把每个数值都计算出来isDefault,请问它会发生什么样的一个结果呢?我们把这个结果叫做标签泄漏。为什么叫标签泄漏?因为在你的计算过程中我已经知道实际的答案了,知道实际答案的话就预测不出来这个结果。因为实际的情况下我们是不知道答案的,或者说实际情况下它的isDefault_mean没有一个稳定的衡量结果。
那么对于类别变量它才能相对稳定。对于数值变量他加isDefault能稳定吗?不能稳定。这个技巧是只限于类别变量,它才能得到一个相对稳定的一个状态特征。
然后就到了我们的第五个步骤,特征构造完了我们就上模型。模型这里用的是 LightGBM。那它的参数也很多,我们在之前的课程中给大家讲过,建议大家用祖传参数,因为祖传参数不需要把时间花到调参上面。那么这里我们也用的是祖传参数:
1 | |
我们的数据比较多,100 多万。迭代的次数也比较多,用的是 2,000 轮。未来你都可以把这个轮数再进一步进行提升。
后面我们还可以做一个子模型的融合,这里叫五折交叉验证。子模型融合是什么含义呢?就是你列了 5 个模型,让这 5 个模型一起来去产生作用,这是一个五折交叉验证的一个策略。
案例实战
那现在就一起来写一写这个代码,一起来看一看这个流程。那这个预测是来自一个真实的业务比赛的一个数据,我们可以去将数据集下载下来,自己做一个测试。就去我上面提供的那个地址去下载就可以了,我这里就不进行提供了。
咱们这次的数据主要是 train 和 testA 两个数据集,先来把数据加载进来,然后简单的看一下,看这个数据长什么样:
1 | |
我们今天简单写一写,给大家写个简单的 baseline,不会写那么完善。思路也是给大家梳理清楚。
第一个模块我们看一看唯一值的个数:比如我们要看一下其中isDefault这个特征的唯一值个数:
1 | |
我们知道,这个特征那肯定是只有 2 个值,不是 0 就是
1,它是最后的一个结果。现在,我们要查看所有特征的唯一值,需要先统计它都有哪些特征,对它的
column 来做个遍历。某一个特征唯一值个数是多少用 format,然后看它的
column 唯一值个数咱们依然还是用nunique()。
1 | |
数据集我们知道,训练集一共是 80 万,ID 的唯一值是 80 万。那我们想,这个 ID 会放到模型中去完成训练吗?ID 每个数值都不一样,而且它物理上面是不具备含义的,不要放到模型中。所以需要 drop 掉。
同时上面也能看出来,还有关注哪些?关注那些唯一值少的,isDefault这个比较明显,因为预测分类就是违约、不违约。
我们从打印结果来看,policyCode个数唯一,我们其实还可以单独写一句话来去做判断,判断唯一值个数是否为
1。
1 | |
如果它的nunique等于 1 的话我们把它打印出来。
然后方便起见,加一个特殊的符号,也是为了在打印结果中一眼就可以分辨哪些是,让它做一个提示。
找到这个结果,它告诉我们policyCode唯一,那我们对这个数据,看一眼它的value_counts。
1 | |
80w 行数据都等于 1,那么我们还需要将它放到模型区吗?不要放,因为放进去和不放进去是没有任何区别的。我们就把这个给它去掉。
那我们的策略目前是去掉 ID 和policyCode,用 drop
方法。我们要去掉它,那训练集和测试集就都要去,不能只去一个,需要两个都执行:
1 | |
去掉以后, 原来的列数是 47 列,现在的列数是 45 列。
接下来,我们需要进行数据的清洗,首先我们需要对缺失值来进行补全。我们先看一看缺失值的个数。
1 | |
统计缺失值个数这里用的是isnull().sum()来做统计,isnull()是对每个字段是否为空来做个判断,如果它为空的话把空的个数求和。求出来之后,现在可以看出来我们是有一些为空的词段,有些个数还挺高的。
比如employmentLength等等,这些资料其实都为空,还是蛮多的。先不着急直接补全,我们还可以在数据探索方面再去探索一下。可以看看这个不同类别特征与
label
之间的一些关系,我们简单看几个比较关键的特征。带大家一起来看一看这个该怎么去写。比如说grade,看它是不是类别特征,查看数据的类型。
1 | |
这里用的是 info 来去做一个查看,我们可以看到grade词段是
object,一般来说就是字符串的类型,可以来对它的grade去求一下value_counts:
1 | |
可以看到是是 A、B、C、D、E,F、G,所以它应该是属于类别特征。那不同的类别和最终违约会有怎样的关系呢?我们以柱状图的形式展示每个类别的数量。呈现图的时候用的 seaborn 里的 sns 来做一个呈现:
1 | |
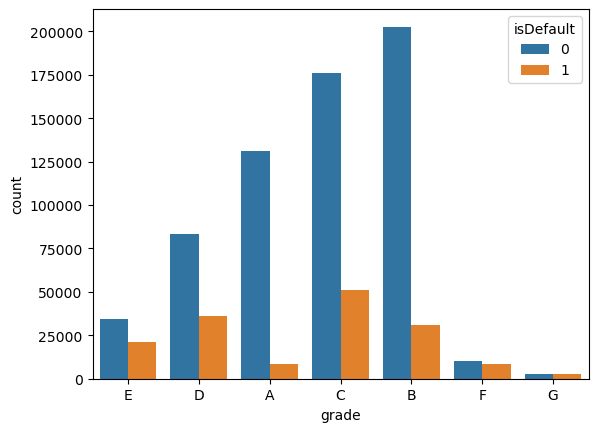
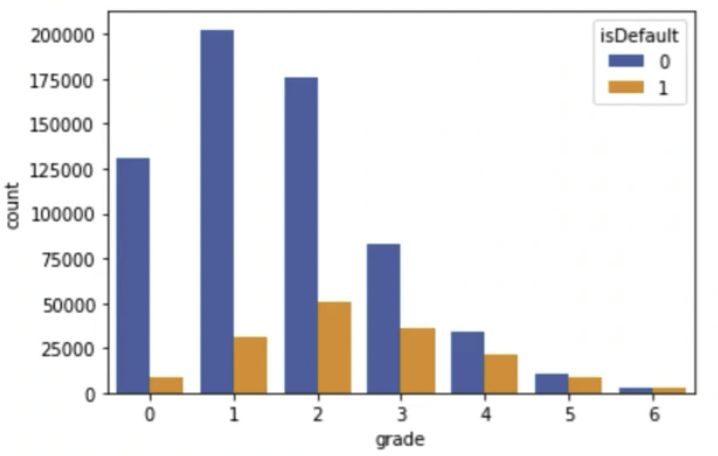
这是一个 grade 跟 isDefault 两者之间来做一个判断,数据是我们的训练数据。可以看一看这个结果,怎么看 ABCDEFG 这些类别跟 isDefault 之间的关系呢?因为 isDefault 有两种类型,所以每一个 ABCDE 都有这两种类型的柱状图。那么哪些特征是比较好,不容易违约。从这张图里面大概是能判断出来,0 是代表好人,1 代表坏人.所以我们看 A 是比较好的,A 的话就不太违约。其次是 B,然后再是 C,还有就是 D。然后到 E 后面违约的比例上基本差不多了,E 的比例已经比较高了,F 和 G 就会更高。所以 A 到 G 之间是有一个顺序关系的,越是字母靠前的 A、B、C 就越不太容易违约。
那应该还有其他一些特征都可以来去做个判断,比如我们再挑一个,homeOwnership,
借款人在登记时提供的房屋所有权状况,看它的value_counts是 0
到 5:
1 | |
那我们觉得理论上它应该是属于什么类别的特征?看一下物理含义,借款人在登记时提供的房屋所有权的状态,它没有小数点,0-5 虽然是数值,但是它应该是个类别特征。
那类别特征的话我们用的过程和刚才是一样的,来做个对比,拿这个词段作为 x 轴
1 | |
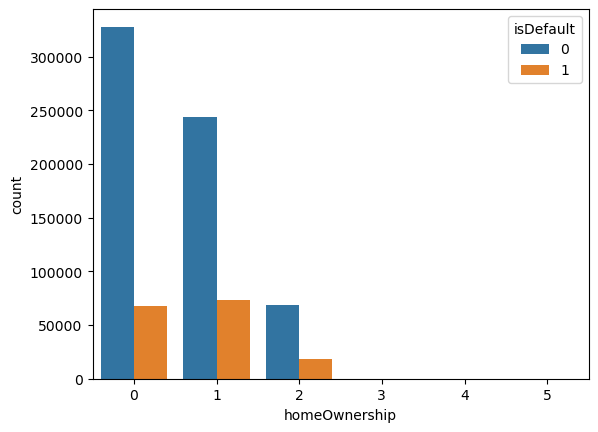
到后面其实这个值已经比较小了, 每个特征还是有一点明显的。0 是比较好的,然后 1 比较差,2 可能后面就逐渐的会下降。这些是属于跟房屋状态的一个特征相关的。
这些维度其实都可以做判断,我们也发现出来有些类别特征是可以找到 isDefault 的一个平均值的。
再看下面这个特征,这 0-13 看起来也像是类别特征
1 | |
这是借款人在贷款时的贷款用途类别,跟刚才过程是一样的,依然是来看一个对比:
1 | |
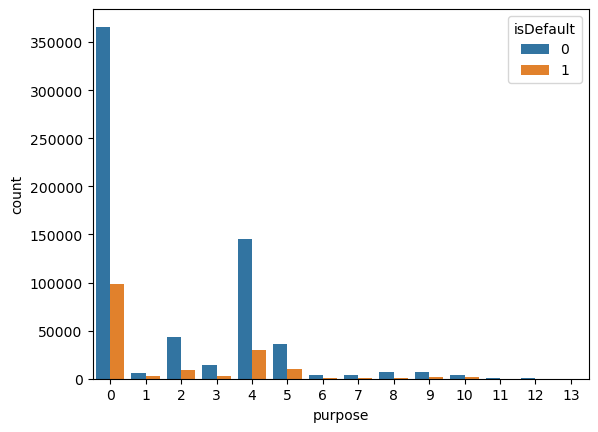
这个有点类似于像 A 到 G 的那个感觉。这个虽然是数值,但大家想想是不 是更倾向于看成一种类别的计算,我们想,类别最后也是要把它转化成一个数值类型的。因为这个统计个数没有小数点,所以我更倾向于把它看成是一种类别。就是已经转化成数值之后的一个类别。
基本上都看完之后我们看下一步,我们要设置一些状态,设置数值类型,然后来去做一些缺失值补全。
那下面我们就要找一找哪些是数值类型,哪些是类别特征。可以借助它的 dtype,那我们之前看过数据的 info, 一般来说 float 应该都是属于数值类型,这个是毫无疑问的。int 类型有些可能要属于类别之后的一个编码,就是它已经是类别加了 labelEncoder, 所以我们先用 float 来去做一个计算。
1 | |
这些肯定是数值特征,因为它是属于 float。
计算完num_features,我们再计算
cat,找到类别。类别特征有一个简单的方法就是非 float 类型。包括了
int,包括了
object。那怎么去写?这个就和我们的数值类型的获取正好反过来:
1 | |
这回我们用的是exclude=float,include
是是,exclude 就是非。这样不是我们 float
类型的部分都等于我们的类别类型。这样类别特征就求出来了,这些都属于类别特征。
下一步就要做缺失值补全了。在模型预测之前,最好把缺失值给它补上,可以基于刚才统计好的类型和数值来去完成一个设置。
cat 是类别特征,然后我们来计算一下它当中有 null 值的都有多少:
1 | |
找到employmentLength是个缺失值,而且只有这一个。我们还是先来看看这个特征的value_counts:
1 | |
看到这个内容,我们来看看怎么补充最好?对于这样一个类别特征,其实最好的办法是通过随机森林去计算,然后将缺失值分别补充进去,不过我们今天重点不在那里,所以现在我们拿众数来做补充。众数怎么求都不需要管,因为通过打印出来的结果,我们明显看到10+ years就是最多的。那我们就直接补进去就好了:
1 | |
再查一遍类别特征的 isnull,全部都为 0 了。那我们类别特征就算是补全了。
相应的,测试集里我们也需要操作一遍:
1 | |
接下来是数值类型,跟刚才的过程原理是一样的。
1 | |
可以看到 num
里的缺失值还是蛮多的,似乎工作量不小。那我们怎么办,先拿employmentTitle这个来看,我们先查看一下它这个特征:
1 | |
特征值内全是浮点数,我们还是来看看它的中位数等于多少。
1 | |
median 是等于 7,000 多,这个特征其实补 7000 多也可以,补 54 也可以,也就是众数。
那一个一个数值特征去处理有点太过麻烦了,我这里只是为了告诉大家思路而不是为了比赛,那我这里就简便的做一个批量处理。全部都用 median 来进行处理。
1 | |
这里我们将所有的 num 进行循环,用于处理每一个数值特征,当 null 的个数大于 0 的时候,也就是有 null 值的时候,我们就将其用 median 进行处理,inplace 打开。不要忘了除了 train 特征集之外,test 也做同样的处理。这样每个有缺失值的部分我们都可以给它做一个补全。
然后查看一下 train 和 test 的 null 值是否还有。这样,我们就完成了所有缺失值的一个补全。
之后我们要做的事情,就是要转化数值编码了。那要做处理的类别特征有哪些呢?我们之前查看 info 的时候,有很多的 object 类型,这就是我们现在要处理的内容。因为 object 类型,基本上都是字符串的形式。
1 | |
找到这些特征,grade是其中一个需要处理的类别特征。这些类别特征其实都需要给它转换成数值编码,我们将其打印出来一遍后续查看
1 | |
然后我们先来处理grade,看看它是什么样的一个特征,以及特征个数都分别有多少:
1 | |
刚刚我们应该能知道它是有一定的顺序的,就是我们之前看到过那张柱状图,可以发现 A 的等级是最好的,所以需要给它指定出来一个顺序,那这里的指定关系可以自己手写一下,去做一个类别编码。按照指定顺序进行类别编码,通过 map 的方式来去做一个指定。
1 | |
那测试集一样,我们也需要做这样一个处理,编码规则一定是要一致。
做完以后我们再去对比一下它的value_counts:
1 | |
可以看到,目前就把它转化成了 0-6 之间,就是我们的 A 到 G 的一个转化。
我们回顾之前的 object
特征列表,第二个是subGrade,那现在就来处理这个特征,还是一样,先查看一下:
1 | |
这个似乎有点麻烦。前面这个 ABCD...应该是属于大的类别,然后后面的 12345 属于小的类别。那现在怎么弄呢,我们创建一个临时变量,然后用这个临时变量做一个排序,再来观察下它的规律:
1 | |
可以发现,这个 A 到 G,每一个大类别里都有 5 个小类别,还是比较规律的。那这样的话就比较好做了,我个人的做法,是干脆从 A1 到 G5 全部编成不同的数值,从 0 开始向后进行排列。
可以自己来去手工写,最笨的办法的话是一个手工的办法来去完成,简单写一个逻辑。
好,先来做一些前期工作,我们先写个 A 到 G 的列表,然后定义一个 index 和一个 map,用于作为中间值好做处理:
1 | |
接着,我们就可以来做个循环了,将我们定义好的映射值放入sub_map:
1 | |
接下来呢,直接将subGrade这个特征做一个
map,然后我们来查看一下:
1 | |
为了查看方便,给它做一个排序。这样,我们可以看到从 0 到 34,一个 35 个特征值就转化好了。
这个逻辑是我们现在 0-34 这 35 个类别,有这个类别我们再统一给它做一个 map。当然,之后测试集也是要做一样的处理:
1 | |
接着,我们再来查看一下目前的 object 特征还有哪些:
1 | |
之前我们知道issueDate是属于日期类型,一共现在还有 3
个类别变量。那现在我们还是一个一个来,先从employmentLength开始,我们查看一下:
1 | |
这个顺序关系怎么去写呢,找一找看有没有一些比较巧的方法来去做一下。排下顺序看看:
1 | |
似乎也并没有特别好的方式,那我们还是用最笨的方法,直接用 map 来手工写一个好了:
1 | |
这样就把这个数值呢给它 map 好以后再去映射回去,test 的应该也是一样的逻辑。
1 | |
处理好这个特征之后,我们就只剩下['issueDate', 'earliesCreditLine']这两个特征需要进行处理了。之前我们知道,issueDate是一个日期特征,也讲到了,处理日期特征要么就是将其分拆,做多尺度,要么就是使用
diff 的方式。这里,我们为了方便,选择 diff 的方式来处理。
首先我们是要将其转化为 Pandas 中的日期格式:
1 | |
那最小的日期是 2007 年 6 月 1 号,那我们就设置一个起始时间,就将其设置为这个时间点:
1 | |
其实时间设置好之后,就可以将特征值设定为 diff 的形式了。这里,我们写一个简单的匿名函数来完成:
1 | |
train 和 test 都做了一个处理,然后我们来看看,特征打印出来现在是什么样。
1 | |
这样就好了。我们接下来就还剩下最后一个特征需要进行处理,就是earliesCreditLine,先来看看它是什么样的:
1 | |
竟然也是一个时间类型的特征,正好,之前处理issueDate的逻辑放在这里还是可以用:
1 | |
那现在呢,我们就将所有的数据都清洗好了,前期是需要花一点时间去做一个数据清洗的工作。大家可以仔细看一下我的整个写法的一个过程,重点还是要看思路,如果不是很熟悉没有关系,一点点来。第一次我可以带你来去写,后面你逐渐熟悉以后就知道它整个的过程原理了。
接着,我们就可以使用corr()来查看相关性了,因为所有特征都变成了数值类型。顺便,我们为了更直观一些,用一个热力图将其打印出来:
1 | |
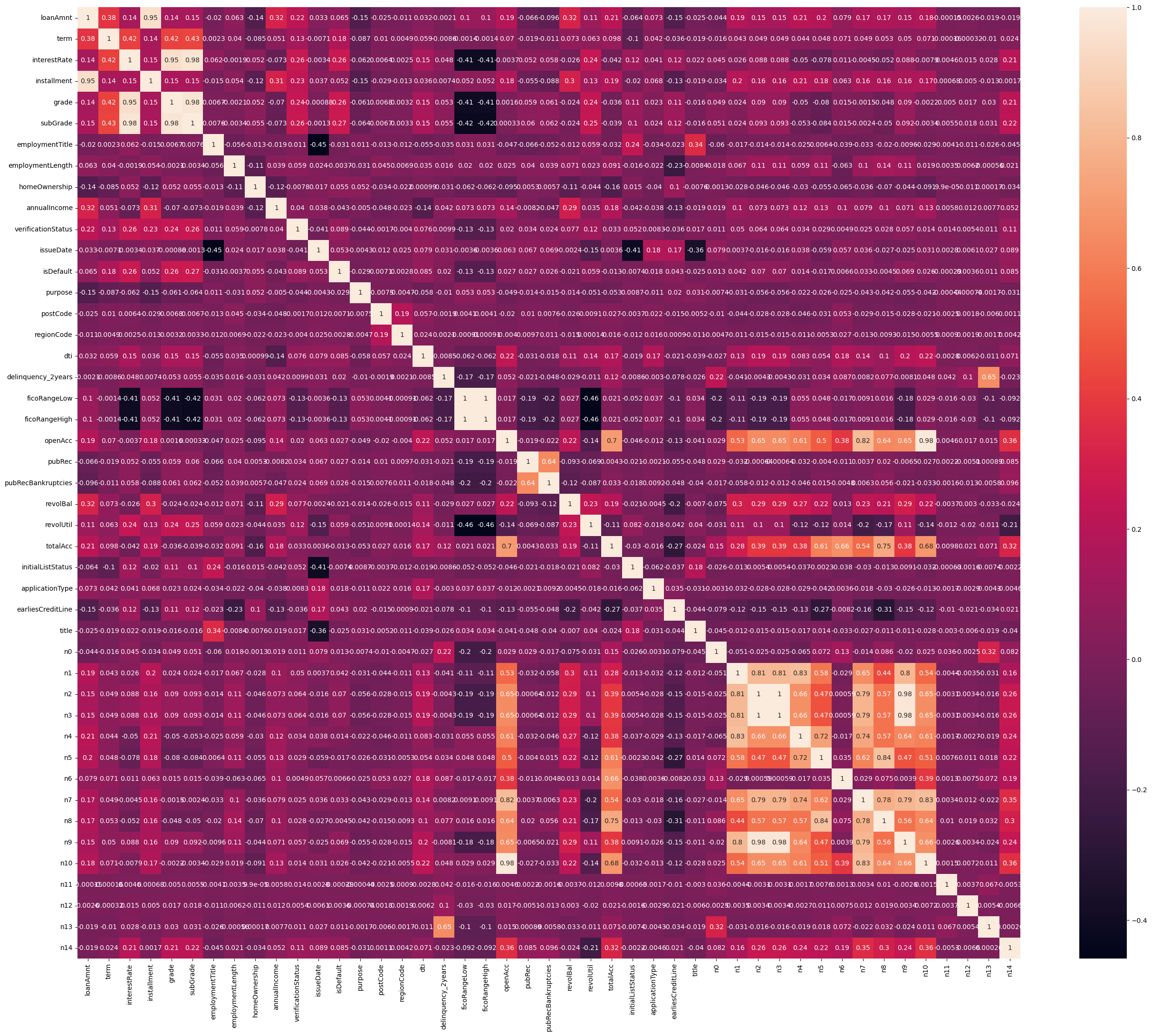
annot=True,是将数值也写上去。那这张图我们的 figsize
就要设置的大一些才可以,因为图太小数字写上去可能有重影。
类别确实很很多,关注哪些值?一般怎么看呢?关注颜色高亮的值,0.95,0.9 这些值就比较有含义。可以自己对照一下,它们是一个高度相关性。还有就是绝对值负的这种数也很重要,它会给你高亮出来。
什么是相关和负相关我这里就不一一给大家看了,你回去可以自己来看一看,这个图都帮你高亮出来了。这是它的特征相关性。
在所有数据处理的工作做完之后呢,就轮到我们的模型上长了。这里我们用的是 LightGBM。
开头,我给到大家的一个祖传参数,这里可以拿过来创建模型:
1 | |
那数据集我们是要进行分割的
1 | |
我们把这个数据集给它做个切分,看一看这个数据的效果,然后再把整个的全量数据拿去做个训练。因为原始数据,我们是要应该把isDefault给它
drop 掉。
然后现在去 fit 一下
1 | |
fit 以后去
predict,然后我们将赋值后的y_pred打印出来,看它运行的结果。我在前面加了一个%%time,所以最后将整个的运行时间打印了出来,我们可以看到,一共用时是
3min 50s,那这样一个 80W 的数据,我们用了 2000 轮来进行
fit,最后的时间还是比较快的,可以看到 LightGBM
确实在速度上还是非常有优势的。那最后的array就是我们的y_pred。
我们先拿它在提交结果之前看一下这个结果会怎么样,如果这个结果还可以,你可以直接用个全量的数据来去做个训练和预测,然后把这个结果输出来。
结果是打印出来了,我们想看看评分,这次的评分来看看两个结果,一个 Accuracy, 一个比赛要求的 AUC:
1 | |
这个结果并不是很好,那我们现在来用一个全量的数据跑一下看看:
1 | |
然后呢,我们从新读取一下 testA 的数据,我们只要它的
id,然后将结果放到里面去作为isDefault这个特征。最后输出一个
csv 文件,用于进行提交:
1 | |
然后到比赛的页面上,我们在提交结果这个页面内将刚才输出的文件提交上去:
在等待一段时间之后,会给一个提交结果:
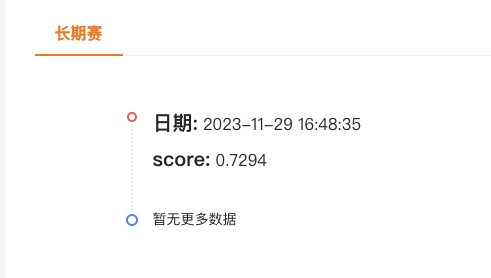
em... 这个分数就不要指望在比赛中有什么好的排名了,基本预测分数应该都是在 0.74 以上的,那这个分数预估在所有参赛人员名单里,也就是在 50%左右吧,反正排名名单里是基本找不到。
好,这样我们整个流程就完成了,当然,如果你看重比赛结果,想自己排名更好一点的话,可以尝试的方式就是更改自己使用的模型,可以事实 catBoost, XGBoost 等等,然后调整一下参数。更重要的,你可以自己用随机森林把之前我们要填补的缺失值都计算填写进去,而不是像我们目前这样随意的使用中位数来进行填充。
简单总结一下,我们的操作就是把类别变量和数值变量做一个区分,对数据做了一个清洗,然后让类别变量做数据编码的时候有一定的顺序,对时间类型求一个 diff,仅此而已。然后就用祖传参数来去完成训练。整个的结果是 0.72 分,基本上应该会在 3000 多名左右的位置 在整个 7,000 多个人队伍中呢也就是中游水平。
刚才我们整个的这个求解这套问题的思路,从数据加载、数据探索,再到数据的预处理、补全这样一套思路,最后到 LGBM 的计算这套过程。这个问题的思路跟我们之前课程中给大家讲 LGBM 基本上是一致的,LGBM 就是帮你来做这种分类任务的。具体做的过程中更多的时间都是在数据预处理的环节中。
好,我们来留个作业,就是大家自己去比赛的这个页面,完成我们今天的一个练习,然后自己提交一下,看看你的分数是多少。可以在我这篇文章下面进行留言,把你的分数告诉我。
在你做练习过程中可能会遇到各种问题,不论是咱们本文中讲解的一些概念原理还是在代码实战过程中调包使用等等,如果你遇到任何问题都可以和我来做一个交流。
那最后也非常感谢大家能学习我的这个教程,绝对有帮助的话,可以分享出去给其他更多的小伙伴看到。
今天的课程就到这里。那我们下节课再见,下节课还是关于 BI 的一些知识内容。
08. BI - 万字长文,银行如何做贷款违约的预测,特征处理及学习

