23. BI - 基于酒店建立内容推荐系统
本文为 「茶桁的 AI 秘籍 - BI 篇 第 23 篇」

[TOC]
Hi,你好。我是茶桁。
上一节课咱们终于是将矩阵分解的完整内容全部都给大家讲完了。矩阵分解是推荐系统里面比较重要的一个环节。surprise 工具后面大家可以自己来去熟悉使用一下,这在 Python 里是一个比较常见的工具箱。以上的环节内容都属于协同过滤,就是一个动态的行为。
在开始讲解推荐系统以来,咱们接触的都是协同过滤的方式。在之前咱们看到的那个树图里可以看到,除了协同过滤之外,推荐系统还有一个部分,就是静态的如何来做推荐。
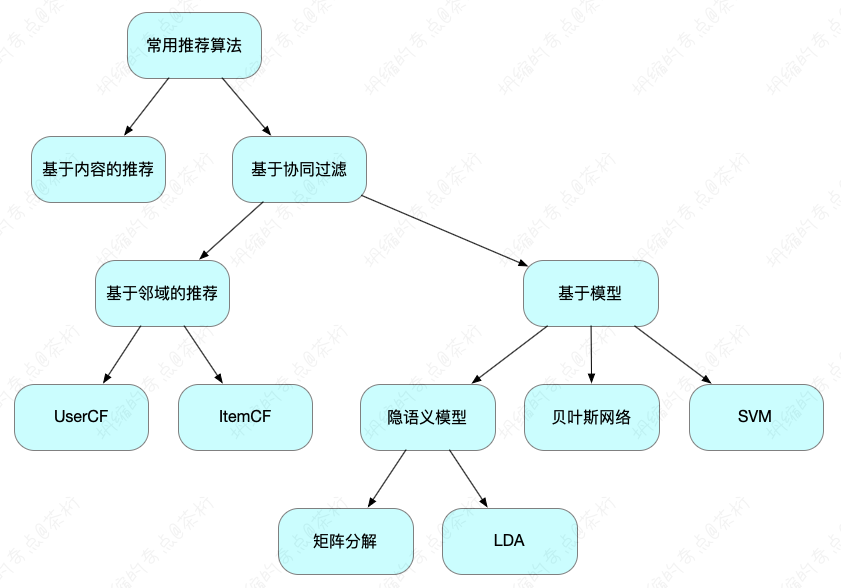
后面咱们就要来看看,静态的如何来做推荐。
其实内容的推荐也是比较常见的内容,传统企业其实有很多是跟推荐相关的。举个场景,在汽车的生产过程中有很多的变更环节,每一个变更我们把它称为 AEKO,AEKO 就是一个变更的需求,值从 B-F 开始到 SOP+3M 其间提出,由于成本优化、技术方案优化、质量改进、法规要求、安全原因或者造形更改等原因引起的技术更改(不限于零件技术状态的更改)。AEKO 用于评估零件更改方位、单价变化和修模费用。
他们记录了很多 AEKO,那一个场景就是,我能不能来了一辆新的车型给我推荐相关的 AEKO 呢?推荐 AEKO 就是这辆车有哪些是需要做的。还有一个词叫 PKO,这是在车里面成本优化的。那这个车有哪些可以做成本优化的点,这就是一个推荐内容,推荐内容可以说是一个很主流的需求。
基于内容的推荐
一般的商品和内容都一定会有个静态属性,所以内容推荐就是一个可以采用的策略。
大家觉得前面讲的协同过滤的推荐和基于内容的推荐哪一种依赖性会更低?就是哪一种更容易实现,可以作为一个通用型的推荐引擎呢?是协同过滤的方式还是基于内容推荐?对数据的依赖性最小的应该是哪一个?应该是内容推荐。内容推荐依赖性是很低的,不需要动态的行为,只有内容就 OK 了,在不同阶段都可以使用。
我们在推荐系统里面是有冷启动问题的,回忆一下几种冷启动,我们在之前课程上接触推荐系统,当时我给大家讲了一个冷启动的问题。分成三种,系统冷启动,用户冷启动和商品冷启动。
- 系统冷启动,内容是任何系统天生的属性,可以从众挖掘到特征,实现推荐系统的冷启动。一个复杂的推荐系统是从基于内容的推荐成长期起来的。
我们猜一下,淘宝到目前为止已经近 21 年的过程了,那它还存不存在商品冷启动和用户冷启动?任何的网站,即使你是个成熟网站都一定会有新的用户产生,也一定会有新的商品、新的内容产生,那么它就一定会存在冷启动问题。
所以冷启动不是只有最开始的时候才存在,它是贯穿我们整个推荐系统的始终。只要贯穿推荐系统始终你就要考虑到这样的一种特殊的状态该怎样来做推荐。
比如说一个用户刚注册了淘宝,你如何给他做推荐?他没有行为,你无法利用他的行为过滤。那就要用到一个内容的推荐系统了,这就是一个更加常见的方法。
- 商品冷启动,不论什么阶段,总会有新的物品加入,这时只要有内容信息,就可以帮它进行推荐。
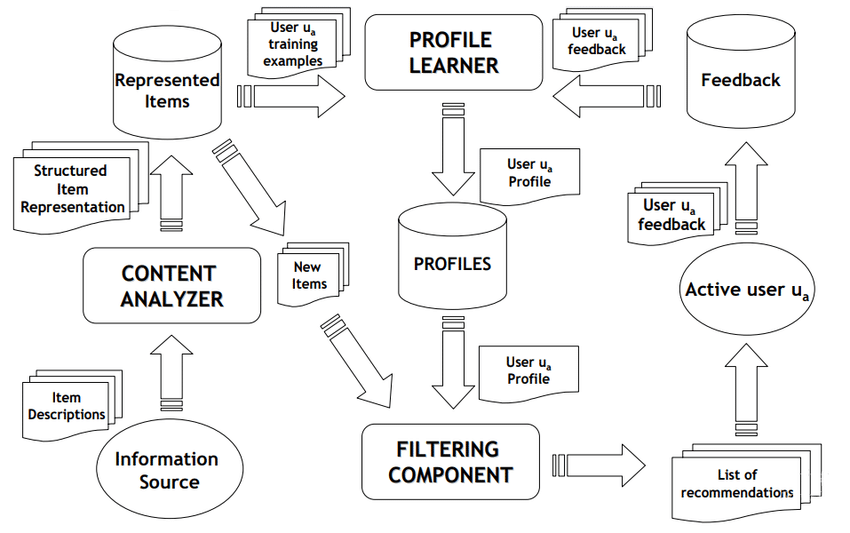
内容推荐系统主要做的事情,第一个就是物体的表征,因为你要学内容的特征。这里的内容特征实际上是对某一个 item 来抽取它的 feature。还有一个就是对人来去做特征的学习。
人是属于怎样特征,你可以把它理解成是画像的层面。商品有商品的画像,用户有用户的画像。每一个画像都会基于某一个 feature,而这样的 feature 可以把两者之间做一个关联,最终得到一个推荐的 list。
这个部分你可以把它理解成 feature,也可以把它理解成是 tag。我们之前也有讲到怎么样基于 tag 来做推荐。
其实内容推荐系统可以把它理解成为就是简单的去打 tag,打画像的标签。商品打 tag,人打 tag,然后基于 tag 来做推荐,就是内容推荐系统的一种方式。
酒店数据说明
怎么样去打 tag?怎么样去分析这些文本的特征呢?我们下面就看一个例子。
这个例子的数据是一份西雅图的酒店数据:
dataset/Seattle_Hotels.csv

它一共有 152 家酒店,数据也不是很复杂。有三个特征,name、address 和 description。name 是酒店的名称,address 是酒店的地址,还有一个就是酒店的一些描述。
很多人应该都上过什么携程,elong 之类的网站吧?国内也有一些酒店的一些网站,它上面也会有一些地址,描述等等这样的一些信息,用户就算没有使用这个信息也存在,用户没有点击行为这个信息也存在。所以内容它是一个本质上就会有的一些特征。
我们现在的目标就是把这些内容特征做一个抽取,给它打上不同的 tag。然后再基于这样的一些标签 tag 来去做相关的推荐。比如用户点击了某一个酒店,看了这个酒店,那你在它的右侧应该会有一些酒店相关的一些推荐。
TF-IDF
这里需要问问大家有没有了解文本的特征提取,一般用什么样的方法来去做。文本特征提取的方法一般用什么?这些海量的信息文本要提取它的特征有一些比较常见的方式,在之前的课上给大家介绍过基于 tag 的那个方法,里面当时用的文本特征提取,提取它的一些特征的维度。最经典的几种方法,TF-IDF。
提到提取文本特征,大家肯定会想到 nltk,之前我们在做词云的那一章节里也有用到 nltk。其实 nltk 算是一种工具,是一种词频工具,所以词频也算是一种方法。词频是统计它出现的频次,频次越高就代表它是一种特征,这是一个词频的方法。
TF-IDF 其实是使用比较多的,还有 Word2Vec。Word2Vec 是属于深度学习的部分,它可以通过单词的前后顺序去做一个预测,学习出来一个单词的向量特征。我建议大家先从 TF-IDF 开始入手。
TF-IDF 是由两个部分组成,一个部分叫 TF,英文是 Term
Frequency,就是词频。如果一个单词它在句子里面出现的次数多,它的权重就会更大。比如cheap,便宜。在他的描述过程中出现了
10 次cheap,这个特征算不算明显?应该算明显。
TF 算是一个维度,还有一个维度叫做 IDF,英文是 inverse document
frequency,中文把它翻译成「逆向文档频率」。他说的是这么一个事儿:如果一个文档在所有的文章中都出现过,就是一个单词在所有文章中都出现过,哪些单词呢?比如说the,a,an,这种单词对于特征区分是没有任何价值和帮助的。对于那些the,
a,反而 TF
值高,它出现频次高。理论上它重要,但实际上它每篇文章都有,它又不重要。那是不是要对它做降权?我们就要用一个逆向文档率给它去降权。
如果你都出现了它就没有价值,所以最终的 TF-IDF 等于什么?等于 TF 乘上 IDF。一个单词它不是经常出现,在某些文章里面出现,它的 IDF 值就会大。那这样的单词它又会在我们的句子里面出现很多次,它的 TF 值就会大。所以 TF-IDF 值是个综合的一个指标,描述了一个单词在你的文档中的权重值。
TF-IDF 由两个部分组成,它更科学的去定义我们的文本特征在当下这样一篇文档中的一个权重值。这是 TF-IDF 的概念。
在内容推荐系统里面基本上都会必备去使用 TF-IDF,因为它是属于最常见的内容推荐系统的一个计算方法。既然是内容推荐系统我们就要分析它的特征,TF-IDF 就可以把文本特征给它提取出来。
一个词语在文章中的 TF-IDF 值怎么计算呢?在一份给定的文件里,词频(TF)是对词数(term count)的归一化,以防止它偏向长的文件。对于在某一特定文件里的词语 \(t_i\) 来说,它的重要性可表示为
\[ \begin{align*} tf_{i,j} = \frac{n_{i,j}}{\sum_k n_{k,j}} \end{align*} \]
\(n_{i,j}\)是该词在文件 \(d_j\) 中的出现次数,而分母则是在文件 \(d_j\) 中所有字词的出现次数之和。
逆向文件频率(IDF)可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到:
\[ \begin{align*} idf_i = log\frac{|D|}{|\{j:t_i \in d_j\}|} \end{align*} \]
分子|D|就是语料库中的文件综述,分子部分则包含语句 \(t_i\) 的文件数目,即\(n_{i,j}\)的文件数目,\(n_{i,j} \ne 0\), 如果该词语不在语料库中,就会导致被除数为 0,因此一般情况下,会使用\(1+|\{j:t_i \in d_j\}|\),上述式子就会变成:
\[ \begin{align*} idf_i = log\frac{|D|}{1 + |\{j:t_i \in d_j\}|} \end{align*} \]
最后就是计算 TF-IDF 值了
\[ \begin{align*} tfidf_{i,j} = tf_{i,j} \times idf_i \end{align*} \]
在工具箱里面我们也可以直接调包使用,帮我们分析 tf-idf 值。
我们提取某一个句子的特征,把每个酒店特征提完,会用一个向量来做表达。这是一个向量维度,比如
h1[x_1, x_2, ..., x_10],第二个句子也是十个维度h2[x_1, x_2, ..., x_10],另外的
10 个值。
\[ \begin{align*} & h1 & \begin{bmatrix} x_1 & x_2 & ... & x_{10} \end{bmatrix} \\ & h2 & \begin{bmatrix} x_1 & x_2 & ... & x_{10} \end{bmatrix} \end{align*} \]
那如何去计算 H1 和 H2 的相似度呢?
比如上面的是向量 A,下面的是向量 B。不知道大家是否还记得咱们机器学习里面讲过的,两个向量之间的相似度怎么去做判断?如何去判断酒店它的特征表达?第一个酒店和第二酒店之间它到底是像还是不像怎么判断?
我们可以用余弦相似度,通过测量两个向量的夹角的余弦值来度量它们之间的相似性。判断两个向量大致方向是否相同,方向相同时,余弦相似度为 1,这是正相关;两个向量夹角为 90 度时,余弦相似度的值为 0,这是不相关;方向完全相反时,余弦相似度的值为 -1,这个就是负相关。这是咱们在机器学习的部分讲向量的时候讲过的部分对吧?不记得小伙伴可以回去翻看一下咱们前面的章节。两个向量之间的夹角的余弦值为[-1, 1]。
所以通过 COS 值我们就可以求出来它的阈值是从-1 到 1 之间。1 是完全相关,-1 是完全负相关,0 是完全不相关。
现在的问题就变成我们如何去计算它的 similarity,这个 COS 值。
给定属性向量 A 和 B,A 和 B 之间的夹角 \(\theta\) 余弦值可以通过点积和向量长度计算得出。两个向量实际上是可以这样去做表达:
\[ \begin{align*} a \cdot b = |a|\cdot|b| cos\theta \end{align*} \]
那么 similarity 就等于是\(cos(\theta)\),就可以等于上面的两个向量相乘,除上模的一个相乘。
\[ \begin{align*} similarity & = cos(\theta) = \frac{A\cdot B}{|A|\cdot|B|} \\ & = \frac{\sum_{i=1}^n A_i \times B_i}{\sqrt{\sum_{i=1}^n(A_i)^2} \times \sqrt{\sum_{i=1}^n(B_i)^2}} \end{align*} \]
这是计算逻辑,那这样一个计算逻辑具体怎么去算呢?来,我用一个例子来给大家看一看,怎么去判断两个句子像不像。
句子 A:这个程序代码太乱,那个代码规范
句子 B:这个程序代码不规范,那个更规范
我们想要去计算它的相似度先要去提取它的特征向量。做文本特征提取首先需要做什么样的操作呢?首先是要去做分词,粒度是以单词为粒度,原来一个句子到底有多少个单词,首先是要去做分词。
中文一般做分词的工具我们用 jieba,英文的咱们也说过,是用 nltk。那咱们现在就先做第一步:分词。
1 | |
分词以后把所有出现过的单词都依次排开:
1 | |
把它排开以后,这个就是你的向量的长度了。再之后,用一个简单的方法计算词频。我们不去统计那个 IDF,用一个简单的词频方式,看一看句子会怎么表达。
1 | |
这样就会把句子 A 和句子 B 所有的单词用词频向量去做了一个表达。我们的数值是以词频的方式去取的,那么句子 A 和句子 B 就会变成下面这样的值:
1 | |
想要计算句子之间的向量,求的是它的一个夹角。通过夹角的值来判断它到底是相关还是不相关。那么这两个句子到底是否相关呢?我们要去求一下 \(cos(\theta)\)。
那根据公式去求,整个式子代入向量值,计算一下:
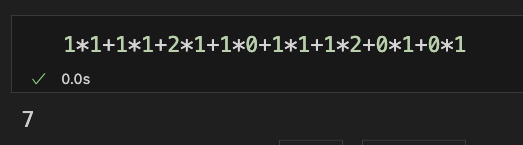
\[ \begin{align*} & cos(\theta) = \\ & \frac{1\times 1+1\times 1+2\times 1+1\times 0+1\times 1+1\times 2+0\times 1+0\times 1}{\sqrt{1^2+1^2+2^2+1^2+1^2+1^2+0^2+0^2}\times\sqrt{1^2+1^2+1^2+0^2+1^2+2^2+1^2+1^2}} \end{align*} \]
那分子的部分是对位相乘再相加,所有对位相乘再去相加,算下来应该是 7。
下面分母是它的模,模是什么?模是它的长度,长度就是平方和再开根号。来计算一下下面的部分, 第一个根号里应该是 9,第二个里面是 10,那应该就是 \(\sqrt 9\) 再乘上 \(\sqrt {10}\),我们直接在 Python 里跑一下:
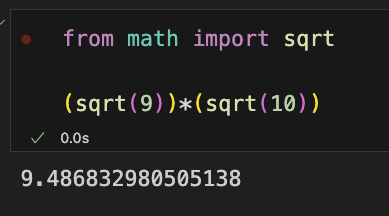
最后分子除以分母,计算的结果应该就是等于 0.738.
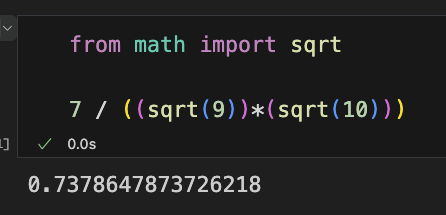
大家可以自己再去计算一下。
0.738 代表这两个句子之间的夹角,那请问这两个句子到底是相似还是不相似?0.738 跟谁比?主要是跟 1 去比,如果它接近 1 就代表它们之间的距离是很小的,应该是相似的。所以 0.738 证明 A 和 B 是相似的。
现在咱们回头来看一下原来这两个句子,将句子 B 改动一下,变成:
1 | |
那咱们的句子 B 计算词频就会变成:
1 | |
然后计算一下这两个句子之间的相似度,可以得到相似度为 0.647, 从结果上来看,也近似于相似,但是其实这两句话的意思完全不同了就。
所以在句子分词过程中我们并没有明显的区分出来真正的语义,刚刚那样的一个状态的对语义分析是没有作用的,它只是简单的统计了一下单词是否出现,出现不同的顺序有可能代表不同的语义。
怎么样把语义的维度考量进去呢?如果要把语义的维度考量进去就不能单纯的去数单词的数量了,因为数量只是看单词是否出现。
那该怎么办?我们就要数除了一个单词本身以外,还会有前后两个单词、前后三个单词,它的一个特征的表达。因为单词有了顺序,它就会有语义的一些概念,谁出现在谁的旁边。
现在就给大家介绍一个语法的规则叫 N 元语法(N-Gram),它帮助我们提取出文本中的 n 个维度的特征。N 元语法是基于一个假设,n 个词出现与前 n-1 个词相关,而于其他任何词不相关。
这里的 n 是可以取成 1,2,3,n=1 时为 unigram, n=2 为 bigram,n=3 为 trigram。语法里面文本可以是一个单词,两个单词或者是三个单词。两个单词就是有前后顺序关系。
我们用一个例子来去体验一下,比如说文本:A B C D E,这里的 ABCDE 都是某一个单词,我们想要把这些单词抽取出来该怎么抽?如果你要抽取它的二元语法,前后两个相出现就是一个二元,对应的 Bi-Gram 为 AB,BC,CD,DE,这是二元的一个例子。如果三元语法怎么写?对应的 Tri-Gram 就是 ABC, BCD, CDE。
那这么做的目的是什么?就谁出现在谁的前面,如果是 ABC 就不是 CBA,CBA 它就没有出现,它就不对。所以必须是严格的顺序,出现的顺序才能匹配上,所以我们就多加了一个顺序的维度。
如果你要加语义特征可能一阶是不够用的,就要用到 n 阶特征。当一阶特征不够用时,可以用 N-Gram 作为新的特征。比如在处理文本特征时,一个关键词是一个特征,但有些情况不够用,需要提取更多的特征,采用 N-Gram => 可以理解是相邻两个关键词的特征组合。
到这里就把 n 元语法的价值给大家说明白了。n 元语法就是可以有更多的文本特征的提取,从二元到三元。如果是 n=1,一元语法是只看出不出现,没有顺序,那就跟我们之前处理句子的方式是一样的。
基于酒店做推荐
回到我们酒店推荐系统,看一看我们该怎么去做。
数据探索
最开始,咱们先做一下数据探索,先不着急去做相似度匹配。
1 | |
这个数据集它有一点特点,它的 encoding 不太一样,用了一个拉丁文。
1 | |

这是前期的数据探索,看看数据长什么样,通过 head 去展示前五条的数据,然后把酒店个数给展示出来。
我们在使用 Python 做可视化探索的过程中,记得在前面一定要先做一个中文支持:
1 | |
要引入字体,否则你是无法显示出来的。
我想从一个单词维度(n=1)上去判断一下。在我们做文本特征提取过程中是有一些停用词的,什么叫停用词?stop words,就是那些口水词,没有意义的词。这些单词的话是虚词,以a、the、off为例,要把这些单词去掉。
去掉以后都是一些相对有价值的单词,再去统计它的 n=1 的单词做排序就很清晰了,如果你不去掉排在前面的就会都是那些停用词。
1 | |
在实现的过程中是用了一个函数get_top_n_words,喂给它一个corpus,corpus代表的含义就是语料,就是所有的
152 个酒店的描述,然后设置一下 n 就可以了。
我们对语料库要提取特征。这里的特征直接调入了CountVectorizer里面集成的一个参数ngram_range,rangen
到 n,其实就是只看 n 元语法:1-1,2-2,3-3。
它还有一个参数是stop_words,就是停用词。停用词里面如果是英文就直接写english,它会自动帮你先去掉停用词。然后提取我们的某一个语法,再针对这个语法把语料喂给它去数一下
CountVectorizer 流出来的一个词频。
得到这个 Vector 以后,transform 对 corpus
做一个使用,得到的bag_of_words,就是它那个词典的一个统计的情况。我们拿这个词典统计情况去计算一下单词的频次,做个排序,最终把这个排序的前
k 个值给它求出来。以上的这个函数就是取 n 元语法中的 top-k 单词。
下面直接调用。我们可以看一看,我们取前 20 个,获取的是 description 的信息。

1 | |
然后把它的common_words里面 description 和 count
做个统计,我们去按照 count
的方式去做一个排序,然后通过barh,也就是条形图去显示一下。
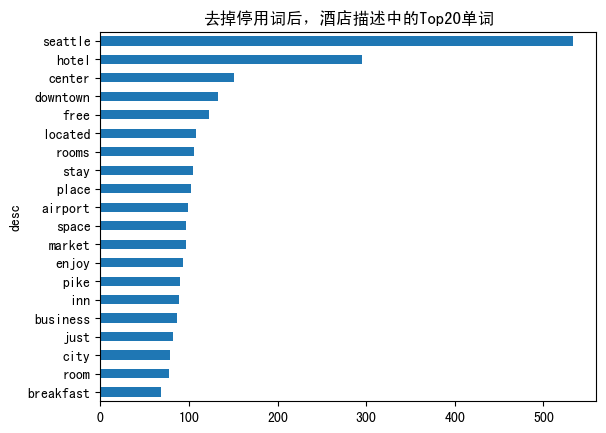
可以看到这样的酒店特征, 里面出现的单词有seattle,
hotel, center等等...
看起来应该还是蛮有道理的,它都能表明这个酒店跟哪些文本之间的一些关系。
除了 n=1 以外,还可以试试 n=2,也就是 Dia-Gram。刚才给大家介绍两元语法是先后两个单词,AB、BC,那我们来看看:
1 | |
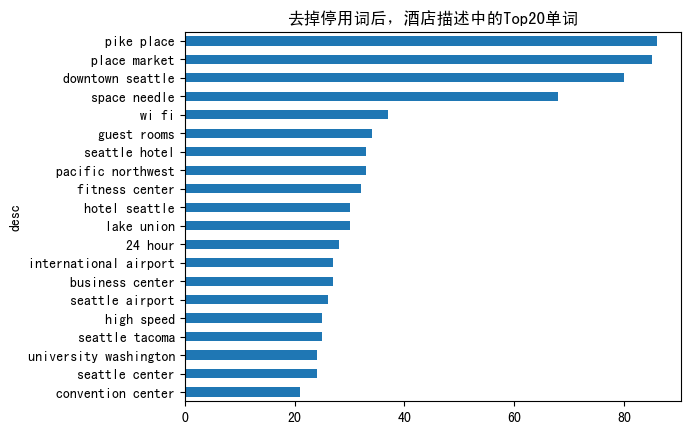
比如说 pack place, place market, downtown Seattle 等等,这些单词从高到低去做一个排序。这些看起来应该还算是比较规整,有一定的物理含义的。
以及我们可以做一下三元语法, Tri-Gram:
1 | |
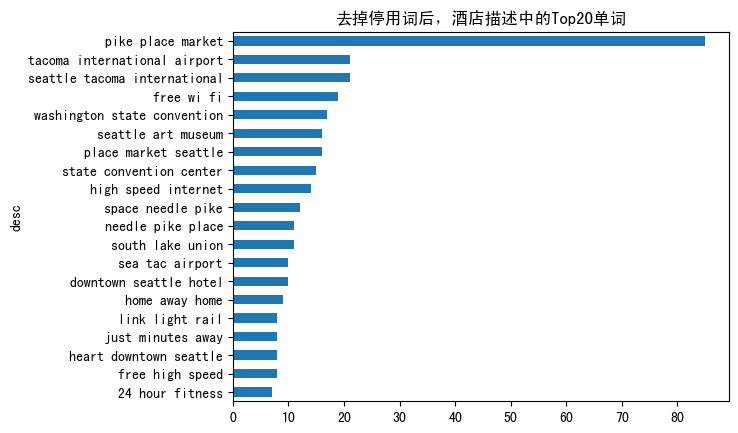
通常一般我们就取 1,2,3 或者 4 元就可以了,再多的一些元的意义也没这么大了。
以上是对原始文本做了一个展示,数据探索的部分我们也就做完了。从可视化里可以看出数据的一些内容。
建模并计算
接着我们做什么呢?要知道类似这种数据其实都是从互联网上扒下来的,虽然这个数据集是完整的,但是原始数据集也是从网上爬虫抓取下来的,所以里面的数据可能有有一些特殊字符,所以需要做一个清洗。
我们先加载停用词,拿到之后打印出来看看都包含一些什么单词:
1 | |
这里使用的是 nltk 里的 stopwords 来去做过滤,这些都是它认为没有什么意义的一些单词。在英语里通过 NLTK 里的 stopwords 是可以直接给它一个默认初始值的,可以在这个初始值上面再去做一些添加。
然后用正则表达式来对文本进行清洗。
1 | |
为了方便我们把大小写做统一。英语有大小写之分,所以你可以都用小写去做替代。然后去做一个提取,这是将之前我们做的预处理匹配上,就做了一层过滤。
我们要做分析是 description
这个字段,用我们写好的函数clean_text来得到一个清洗后的结果。
1 | |
然后设置名称为index:
1 | |
后面要去做的就是提取特征了。咱们已经把数据清洗好了,现在直接用TfidfVectorizer指定
n 元语法。
1 | |
这里现在用的是 1、2、3 元, 那我们来看一下 TF-IDF
提取文本特征的参数,ngram_range=(1, 3)表示的就是一元,二元和三元,我们分析的是它的单词。
min_df是最小的词频,比如说把那些频次不太多的,不太重要的单词给它去掉,这样也可以控制一下模型的大小,否则矩阵维度会非常大。
那整段代码的目的就是创建一个 tf-idf 的特征提取器,它的特征提取是 n
元语法的 1、2、3,又做了两次过滤,过滤掉出现频次小于 1% 的,以及
stop_words=english 的过滤。
然后对这个 tf 就去做了一个 fit 和 transform。
1 | |
得出来是一个向量。n 元语法 123 加到一起,可以拥有维度会很多。得到一个 tf-idf 的矩阵,我们把 name 打印出来。
1 | |
tf-idf 的 names 都是你抽取出来的一些特征,这些特征维度还挺多的,3,000 多维。实际上一个 description 的描述也就 100 来个单词,而整个 3,000 多维是所有的酒店出现过的一些单词的情况。
前面这些写完我们可以去看tfidf_matrix
1 | |
这个tfidf_matrix代表什么含义?我们可以直接去看看它的
shape,这是 152 个酒店的所有的词频,它的 shape
应该是多少呢?是152*3154:
1 | |
这些维度特征的提取完以后,这些向量该怎么计算相似度?要用余弦,我们现在用一个linear_kernel来去计算这两者之间的一个点积。
1 | |
计算完点积以后,我们把计算之后的cosine_similarities打印出来。那打出来之前,我们来想想,cosine_similarities这个矩阵大小是多少?咱们一共是
152 个酒店,原来的 tf-idf 有 3,152
维,那我们最终得到的这个矩阵的大小应该是多少?
每个酒店和另外一个酒店之间的相似度,它的值就会放到矩阵里面。所以每一次计算的都是一个计算的相似度的结果值,猜一猜大小应该是多少?
应该是152*152,把每一个向量最后得完的夹角放进去,这是一个计算结果值,所以它应该是152*152。
我们打印出来看看:
1 | |
看一下cosine_similarities的特点,对角线为 1。
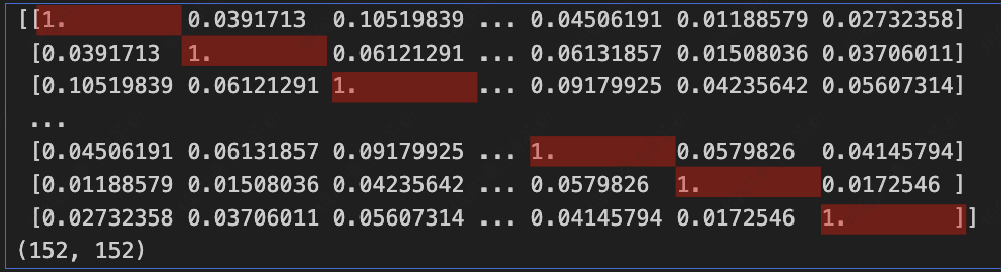
为什么?自己和自己没有方向的差别,它是同向的,所以为 1。这个值一般都不是特别大,因为它有些单词可能出现,有些单词不出现,所以大部分是不太一致的,这也很正常。
矩阵计算完了,再之后我们就要写一个推荐的函数了。
1 | |
我们传进来是刚才计算好的相似度矩阵以及想要查询的酒店,逻辑是先从大表里面把这个查询的酒店的下标找到,然后再从刚刚计算好的cosine_similarities矩阵里面把跟其他之间的相似物给找到,放到了一个
series 里面。
再之后去做了一个排序,
用sort_values来做排序,推荐要做降序,所以我们ascending是等于False。
之后要去取 TOP10,前 10 个最大的。不过我们写的时候 iloc 并没有从 0
开始,而是[1:11], 这是为什么?你要去推荐前 10 个,现在是从
1 到 11,去掉第一个。原因也比较简单,我们看一下那个相似度矩阵,对角线为
1,对角线是自己。
所以一般点积完以后在页面上是有这个商品,不用再去推荐它了,就把前面这个自己给它去掉了。1 就是自己,所以在推荐里面要把第一个去掉。也有些场景是把那些看过的都去掉,其实也很简单,就是每次浏览之后,从列表里删除这个商品就好了。不过在进行相似度计算的时候这个商品不能删,只能从展示列表里删掉,不然模型样本就少了一个。这是它的本质,如果 1 到 11 里面有些是看过的也要去,这样我们就取前 10 个没有看过的酒店做推荐,放到推荐的 list 里面去。
执行推荐
那整个逻辑咱们就讲完了,这是一个基于内容推荐系统的整个流程。最终还是要去测试一下这些酒店。比如说,一个用户流览了一个酒店的页面,它的关键描述词是Hilton Seattle Airport & Conference Center,
我们执行一下:
1 | |
基于这个酒店的描述,它跟哪些酒店相似度高,我们就会给他做一个推荐。
第二个用户看到的酒店描述是The Bacon Mansion Bed and Breakfast,那么他会推荐哪些?我们也来运行一下看看:
1 | |
这两次的推荐到底是否符合?之前也在 Google 上面自己做过一些测试,基本上跟 Google 的一些预测还是比较相关的,所以文本推荐,这种 tf-idf n 元语法分析还是很好的,可以帮你去解决相对推荐问题。
这是一个非常经典的一个例子,在使用过程中可以自己再梳理一下。使用过程做了哪些事?第一是特征提取,tf-idf;第二是相似度矩阵计算,通过linear_kernel把相似度矩阵计算完;第三步写推荐引擎,这个引擎就是找到你看过的商品,把它的
similarity
从大到小排序,去掉自己之后返回,把这个返回的酒店名称查询出来,喂到列表里面去。
以上就是整个的一个内容推荐系统的过程,其实并不难,比较好理解。越是简单,不是很难的一些例子其实应用的场景就会越多,你在未来的使用过程中有可能就会经常会用到。
总结
基于以上这个案例,我给大家做一个总结。相似度检索是一个比较常见的工具的需求。代码里面涉及到的工具咱们来总结一下。
因为它跟文本相关,你可能会用到词频统计CountVectorizer,CountVectorizer是将文本中的词语转换为词频矩阵,fit_transform是训练和预测连起来一起做,获取文本的一些关键词信息,查询词频的一些结果等等。get_feature_names_out可以获得所有文本的关键词,toarray()是查看词频矩阵的结果。
那 TF-IDF
在上面咱们也有详细的去做讲解。那这里咱们可以直接使用TfidfVectorizer去完成,将文档集合转化为
tf-idf 特征值的矩阵。它有几个参数设置:
analyzer: word 或者 char,即定义特征词(word)或 n-gram 字符ngram_range: 参数为二元组(min_n, max_n),即要提取的 n-gram 的下限和上限范围max_df: 最大词频,数值为小数[0.0, 1.0],或者是整数,默认为 1.0min_df: 最小词频,数值为小数[0.0, 1.0],或者是整数,默认为 1.0stop_words: 停用词,数据类型为列表
那再总结一下刚才的整个流程。第一个流程是先对酒店做了特征提取,提取以后我们用 n 元语法,其实它是基于 n 元语法的特征提取的 tf-idf。
- N-Gram, 提取 N 个连续字的集合,作为特征。
- TF-IDF,按照(min_df, max_df)提取关键词,并生成 tf-idf 矩阵。
然后计算相似度矩阵,利用的余弦相似度。最后进行 top-k 的一个输出。
整个过程可能看起来不是很难,但是写起来的话还是需要熟悉一下的。里面要使用的工具具体导入的包可以拉取我的源代码来看看。那用这个酒店的案例,咱们就把这个基于内容推荐讲完了, 看完之后大家要在课后多敲代码熟悉一下。
23. BI - 基于酒店建立内容推荐系统

