32. 深度学习进阶 - Transfer Learning

Hi,你好。我是茶桁。
之前的课程中,咱们学习了 CNN 的原理,学习了 pooling, fully connected 是做什么的。还了解了理论上简单的模型也是可以做事情的,只不过在特定的一些情况下要解决问题的时候简单方法效果不太好,所以用了像 LSTM,或者 RNN、CNN 之类的结构。
这些本质上都是在做特征的提取。一个经典的观念是,神经网络其实一共都可以分成两个部分,第一个部分是特征提取,第二个部分是分类器。像 fully connected layer,其实就是之后再加上一个 Softmax 或者 log Softmax,在做分类器的实现。
前面在进入全连接层之前,也在进入 Softmax 或者 log Softmax 之前,全部做的都是特征提取的事。
不管你是线性函数,就线性变化全连接的这种网络,还是 RNN,LSTM 或者 CNN 等等,在进入 Softmax 之前,这些都是在做特征提取。
Hinton 当时的说法我觉得说的很有道理,就说「特征提取的作用是让相似的东西不相似,让不相似的相似」。
意思就是,我们对于任何一个神经网络来说,到最终的这个全连接,加上 Softmax,之前的这些东西不管你是输入的是一个图片还是几个文字,还是说一串数据。所谓的让看起来相似的东西不相似是如果有两个图片,或者两组数据,他们在我们人看起来是比较类似的。但是假设他们的 label 不一样的话,我们整个特征提取的过程是把输入的这两个 x,人看起来是一样的,在最后输出的这个地方要尽可能的不一样。所以送到分类器里边,它们结果差距才能大。
如果这两个东西看起来很不一样,就假如说有两只猫,一只猫特别瘦,黑黑的。一只是橘猫,特别的胖,大小也不一样。但这个在图片来说这差距是很大的。我们整个做 feature extraction 的时候是要把这两张图在最后变成一样,就在最后的时候变得相似。输入的时候不相似,但是经过特征提取其实要把它变相似。这样送入到了 Softmax 它才会产生分类的作用。
接下来讲了卷积神经网络的计算过程以及整个模型的搭建是什么样的。然后还讲了 RES-NET 的原理,这个也需要去理解。
Transfer Learning
那么现在,咱们今天就跟大家来介绍一个比较重要的概念,深度学习共同的基础部分,就是transfer learning。
咱们现在的这个深度学习模型变得越来越复杂了。上节课给大家举过这些例子,不同的人提出来了不同的模型, 重点给大家介绍了一个 RES-NET 和 Inception model,也称为 GoogleNET。
模型现在其实已经变得越来越复杂,这么复杂的结果是什么呢?结果是我们现在已经很难从头到尾搭建一个模型了。现在的模型结构已经这么复杂了,很少有人能有时间,或者在工作的时候有时间、有精力能从零开始一层一层的去做搭建,这是第一方面。
第二个方面,大家还发现一个特点。在结构中越接近前边虽然任务不一样,比如解决动物分类或者解决人物分类,但是越靠近前边,它们的特征相似度越高。
换句话说,有一个 RES-NET 专门对人物分类,还有一个是是专门做动物,它们分的类别完全不一样。但是就前边这些 CNN 的结果往往都很相似,而且是越往前越相似。
这是因为这些过程都是在做特征提取,如果都是一个比较相似的图片任务的话,在这个过程中特征提取其实从刚开始的时候在解析图片上的重要程度,其实要提取的东西都是类似的。
比方说识别我左手的水和我右手的手机,还有我前面站着一个美女,刚开始都是要识别它的轮廓。然后都要识别它的局部的形状,还要识别颜色... 这样的一个直接的结果,其实我们每一层用的 filter 都是类似的,只要达到一个比较好的结果,前面的这些 filter 都是类似的。
filter 类似是因为 filter 控制的是我们要提取什么重要特征。那么我们就发现从前到后,其实越是前边越是比较简单的特征,线、块这些,到后边越来越综合。
有了这个之后大家就发现,既然现在模型这么复杂,从头到尾要搭建一个模型已经很难了,我们可以直接用这个模型的结构。
第二我们发现不仅模型的结构可以,模型的权重都也可以。可以用这个模型的权重来训练,直接把这个模型的权重拿过来。
其实也就是说,我们可以直接下载一个模型,把别人训练好的权重一起拿过来,这些东西就是一堆数字。然后它是在 task a 上弄的,我把它用到了 task b 上。训练的时候让它不要进行反向传播,在进入全连接层的时候再进行反向传播。
大家把这种学习方式就叫做transfer Learning,
迁移学习。我们平时日常在工作的时候经常会这么做。
客观上来讲,不同的任务,任务越类似肯定迁移的时候越好迁移。所以说其实它和任务的相似度以及和数据量的相对大小很有关系。
假设我们两个任务,A 和 B。这两个任务,A 是分类狗,B 是分类狼,A 原本训练数据集是 100W,B 的训练集是 1W。那么这两个任务比较而言,任务相似度非常大,原任务相对新任务数据量比较大,这个时候基本上迁移学习就非常好迁移,我们都可以不去更改进入全连接层之前的所有内容就可以进行迁移,只需要更改全连接层。也就是特征提取的部分完全平移。
那么如果 A 任务还是分类狗,B 任务是分类汽车。A 原本训练数据集是 100W,B 的训练集是 5000W。那这两个任务比较而言,任务相似度非常小,原任务相对新任务数据量是小的,这个时候迁移学习就变得很困难,可能也只有图像线条,颜色这些个特征提取的部分可以迁移,基本是特征提取的最前边的部分。
所以,Transfer Learning 的容易程度,在一个二维平面直角坐标系内的两个相关项,也就是 x 和 y 轴就是任务相似度和原任务相对新任务数据量的大小。
如果重新训练,怎么样来 transfer 呢?说了这么多,还是直接来看一个实例, 来看看我们具体该如何做「冻结」。
用的这个数据集, cifar10,这也是一个很经典的数据,它是十个典型的很常见的物品的分类。
咱们先引入必要的库,然后 down 数据集:
1 | |
这个文件一共 170 多兆,大部分人物提取的特征差不多,所以权重可以不用更新,用其他相似任务的参数,相当于新模型初始化的时候,理解为更接近在最优点附近。
它里面的每一个数据的类型是一个 PRL 的 image, 要在 PyTorch 里对这个图片进行使用,我们需要进行一个预处理。我们需要在前面定义一个方法:
1 | |
首先, 我们要先 Resize,然后用一个 CenterCrop, 让图片以中心扩散进行切割。如果有些图片不是正方形,那么第二个操作就是把中间的部分裁一个正方形出来。最后再把它变成一个 Tensor。
然后我们需要修改一下数据获取数据时的transform。
1 | |
现在看一下, cifar_10 的数据就变成 tensor 了,shape 是[3,224,224]
1 | |
得到 Tensor 数据之后,要训练的时候得一次一次的取不同的数值出来,我们要做 SGD,随机梯度下降。那么在做这个的时候有一种方法,写个 for 循环然后每次随机取一些 index,再把这些 index 的值给它取出来,这是一种方法。
还有一种方法,我们可以直接用DataLoader,声明了之后每次要生成一个迭代器,每次会输出一些内容。
1 | |
如果要把所有的数据传输进去,它有 5 万个照片太大了,内存吃不消。所以要把它做成 SGD,要每次随机取一个东西。
然后我们来定义一个 RES-NET:
1 | |
有了这样的 RES-NET 之后,它输出的是 1000 维的,而我们这里其实是需要一个 10 维的,那我们就需要把它的最后一层给它重新做一下。
1 | |
如果我们没有这一句,我们可以来看看它会输出什么。
1 | |
输出的是一个很长的东西,其实是有 1,000 维的,这里输出了 1,000 个。
现在如果把它的最后一层全连接层改了,变成 10 分类,因为这个 cifar10 是一个是分类问题。
1 | |
改完之后输出的数据就是 10 维的了,大家可以自己去跑一下代码,我这里就不贴了。
接着我们再来生成一个 loss 函数和一个优化器。
1 | |
criterion 是测量尺度、考核标准的意思。parameters 是要把所有参数进行拟合, 进行重新训练。
1 | |
现在是这么个结果, 我们先来保存一下,我创建了一个 32.log, 用于暂时保存咱们的结果。那因为我训练的时候加了一个 tqdm,所以也把时间打印了出来,不过为了避免代码上的误解,所以代码我还是给的没有加 tqdm 的样子。
现在要迁移怎么迁移呢?很简单,第一步我们需要改一下我们的 RES-NET。
1 | |
我们加一个参数pretrained,然后将值设为True,现在要保留它的数据,保留之前训练的权重。
第二步要冻结它的这些参数,把 RES-NET 里边所有的 parameters,每一个都有一个 requires grad,给它定义成 false。
1 | |
设置成 false 之后进行反向传播的时候这个值就不更新了。不更新的话那就相当于冻结了。
之前写的resnet.fc就相当于重写了 fc 分类层。
1 | |
假设现在的任务和原来任务不相似,或者说现在原来数据量和现在数据量相比偏小,那么对于这个 RES-NET,不能把它所有的 requires grad 设置成 false,要把它前面部分的给它设置成 false,后边设置成 true。
重写了这个 FC classifire 之后,新声明的参数默认它是需要进行梯度下降的,所以不需要在这写成 false。就在这里,这个 FC 的 grad 默认是 true。
那到这一步, transfer 就结束了,我们可以重新训练来看看。
你会发现,时间上明显快多了。这个就是因为咱们这次训练的参数少了很多。
1 | |
之前我们每一轮训练几乎都要花个 50s 左右,现在基本在 16 左右,速度上提升了 3 倍。从总时间上我们也可以看出来,训练速度提升了好几倍,从原来的一小时 12 分钟,直接降到了 26 分钟。并且,loss 也有所提升。
那么我们该怎么去看这个模型的层数,确定哪些是在前面部分,哪些实在后面呢?对于一个模型而言,最简单的办法就是直接 print 出来,比如说咱们的 resnet18:
1 | |
这次我将结果打全,我们可以清晰的看到这个模型里从上到下,从前到后的每一层,最后一层是一个 fc。
那除此之后,其实我们可以借用第三方库来进行计算,有一个库叫做torchsummary,
1 | |
这个去监测模型的层数和信息就更好一些,可以很直观的看到每一层以及整个模型的相关信息。不管是你自己的模型还是第三方预先训练好的其实都可以。我们在后面设置了一下输入的大小,设置了之后,summary
在后面参数一共多少就一个一个都给你显示出来了。我们刚才输入的(3, 224,
224),然后从第一层开始的Output Shape是多少,一层一层的向下就直接有了。
这两个方式都还是很有用的。
那么之后做训练的时候大家要对几个数字稍微多一点敏感性,我们来看,首先我们定义一个 loss 函数:
1 | |
然后我们输入下面几个值做测试:
1 | |
transfer learning 基于的是模型从前往后。前面层学的东西比较基础,到后边学的抽象层次越来越高,看到的是更复杂的一些。
那咱们现在就再来演示一下它到底学的学到都是什么东西。那么为了看一下这个到底学的是什么,我再次贡献一下自己。

这个是早些时候我一个同学帮我画的头像,就拿它来看吧。
首先,我们前面看到打印结果了,resnet18 的第一层是 conv1,我们来看看第一层:
1 | |
然后我们就可以看到一堆的 tensor
数据,这个unsqueeze是将数据改变了一下结构,从myself变成了[[myself]],改成这样是因为
torch 每次接收的是一个 batch 的东西,直接输入一个图片是不行的。
我们看一下它的这个输出,第一个卷积的输出是什么:
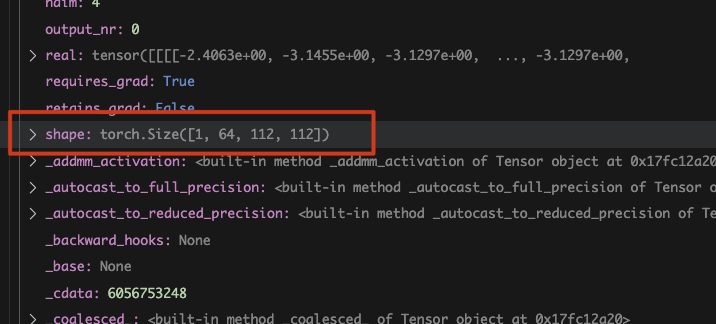
我们可以看到,它的 shape
是[1, 64, 112, 112],那这里边的分别是什么?
第一个维度,这个 1 是 batch 的数量。64 是 filter 的 channel,所以它输出了 64 张图片。 后面的 112 和 112 是一组数据,从这个数据来看,这个图片经过卷积之后,经历了一个缩小的变化。从原来的 224 缩小到了 112, 经历了一个下采样。
接着咱们来看一下具体的数据内容,看看 output 第 0 个的内容是什么样的:
1 | |
因为结果还在内存里,所以我们永乐一个detach()。
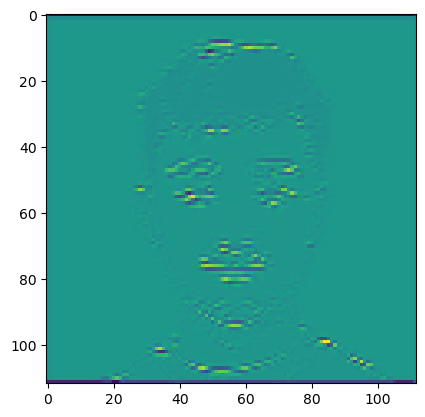
它把我的轮廓给提出来了。
我们再来看看别的是什么样,我们改成[0][2]:
这个貌似是将背景扣了。
我们不一张一张来看了,咱们来将探索过程写个循环,看一下它到底都做了什么。
1 | |

它这 64 个学到的几乎每个都不一样,那有些是有用的,有些是没用的。有些是从边缘层面上,比如说 filter20 就是从边缘上,而有一些,比如 filter21 就是从颜色上。
那么如果我们现在想把第二个、第三个、第四个这些都拿出来的话怎么办?当然理论上可以沿着它的结构给一层一层解出来,但是 PyTorch 里面给咱们的提供了一个比较简单的方法。
那刚才写的那个代码,其实是在进行前向传播,就我们刚才写代码就是在模拟它的前向传播,forward。PyTorch 就给我们提供了一个很方便东西,它可以给前向传播及反向传播的时候注册一个函数。就比如说:
1 | |
我们现在把 resnet 里边所有的 model 拿出来,然后如果这个 model 它是卷机,给这些所有的模型注册一个函数。这个函数是是他在进行前向传播的时候会自己调用的,就不需要咱们再手动的去写了。
那我们现在就来将之前写的内容抽象成一个函数visualize_model,在定义这个函数的时候需要注意一下
PyTorch 的相关 API,
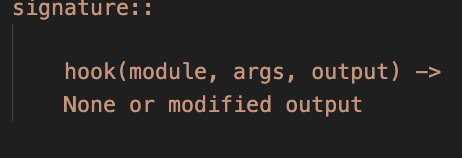
那我们在定义的时候,也就需要一样传递这些参数:
1 | |
这样前向传播的时候,它会自动调用。现在我们就可以让它来进行前向传播:
1 | |
no_grad的意思是不让它进行反向传播,只进行前向传播。
我们在观察它每一层的结果的时候,就会发现越到后面就越抽象,我们捡中间某一张贴出来来看。

就基本上,这个时候还能勉强辨认出是个任务头像,再往后的结果,我肉眼已经分辨不出来它是个啥了。就这是整个模型一层一层学到的东西,它里边是从刚开始的时候比较的底层、比较的基础,后边会提取的东西越来越多。
就咱们在这里所做的这种权重可视化,有一个比较有趣的应用:deep dream,它就是将刚才这些学到的靠后的权重,然后应用到一张图片上。就我们刚刚可视化那种层数再应用到一些新图片上,就会产生这样的效果。如果感兴趣的可以自己试一下。
好那咱们这个 RES-NET 和 RES-NET 可视化,以及 transfer learning 的内容,到这里就可以告一段落了。整个的深度学习的基础部分,也就到这里结束了。
最后,我们来留一个小作业。
作业
那么本节课的最后,给大家留一个小作业,稍微还是有点难度的,需要大家自己去查阅相关手册才行,不过知识点都是讲过的。作业内容为「对验证码进行识别」。
练习内容: 训练一个模型,对验证码中的字符进行分类识别,并最终完成验证码识别的任务。
数据集: 数据集内包含 0-9 以及 A-Z 一共 36 个字符,训练集中每个字符有 50 张图片,验证集中每个字符有 10 张图片,验证码数据集是由随机去除的 4 个字符图片拼接而成。
需要的相关知识:
- 数据读取
- 使用 torch 搭建、训练、验证模型
- 模型预测于图片切分
好,给大家提供下思路,我们将我们需要解决的问题分成四步:第一个,先建立字符对照表,第二个,要定义一个datasets和一个dataloader。
第三个,需要定义网络结构。 第四个,定义模型训练函数。
最后,就是验证训练结果。
数据集请关注「坍缩的奇点」后从原文下载。https://mp.weixin.qq.com/s/v_4OOMB_Gg-a1V3a399NEQ
32. 深度学习进阶 - Transfer Learning

