Hi, 你好。我是茶桁。
上一节课,我给大家留了个作业,内容是对验证码进行识别。
咱们的再把练习内容重复看一下:
练习内容:
训练一个模型,对验证码中的字符进行分类识别,并最终完成验证码识别的任务。
数据集: 数据集内包含 0-9 以及 A-Z 一共 36
个字符,训练集中每个字符有 50 张图片,验证集中每个字符有 10
张图片,验证码数据集是由随机去除的 4 个字符图片拼接而成。
需要的相关知识:
数据读取
使用 torch 搭建、训练、验证模型
模型预测于图片切分
好,让我们来看看具体的,我们该怎么完成这个练习。
问题分析
首先,我们需要一步步的确定我们的问题。第一个问题,肯定是要先建立字符对照表,第二个问题,要定义一个datasets和一个dataloader。
第三个问题,是需要定义网络结构。 第四个问题,就是定义模型训练函数。
最后,就是验证我们的训练结果。
先从第一个问题分析,我们可以通过遍历字典,将每一对键值反转,并存储于新的字典中。我们可以按如下方式去做:
1 new_dict = {v:k for k, v in old_dict.items()}
那么第二个问题就简单了,在 opencv-python
中,可以使用image = cv2.medianBlur(image, kernel_size)进行中值滤波。
第三个问题,在 torch 中,卷积于前连接层的定义方法可以是:
1 2 conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
具体的,还可以参看 PyTorch 的相关手册。
用这两个方法进行组合,就可以定义出一个卷积神经网络结构。
接下来第四个问题,要定义模型训练函数。那么 torch
框架的模型训练过程会包含清空梯度、前向传播、计算损失、计算梯度、更新权重等操作。
清空梯度:目的是消除 step 与 step 之间的干扰,即每次都只用一个 batch
的数据损失计算梯度并更新权重。一般可以放在最前或最后;
前向传播:使用一个 batch
的数据跑一边前向传播的过程,生成模型输出结果;
计算损失:使用定义好的损失函数、模型输出结果以及 label 计算单个
batch 的损失值;
计算梯度:根据损失值,计算模型所有权中在本次优化中所需的梯度值;
更新权重:使用计算好的梯度值,更新所有权重的值。
模拟一下单词流程代码,样例如下:
1 2 3 4 >>> optimizer.zero_grad() >>> output = model(data) >>> loss = loss_fn(output, target) >>> optimizer.step()
好,步骤分析完了,接着咱们来进行实现,这次我们所用到的代码库如下,将其都引入进来:
1 2 3 4 5 6 7 8 9 10 import cv2 import torch import torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimfrom torch.utils.data import Dataset, DataLoaderimport torchvision.transforms as transformsimport pickle import matplotlib.pyplot as pltfrom PIL import Image
然后我们来看一下数据集,上一课末尾我给过数据集了,有需要的自己去找一下。先将需要用到的数据路径都定义出来:
1 2 3 train_data_dir = 'data/train_data.bin' 'data/val_data.bin' 'data/verification_code_data.bin'
这个数据集保存在二进制文件中,我们需要定义一个函数,读取二进制文件中的图片:
1 2 3 4 def load_file (file_name ):with open (file_name, mode='rb' ) as f:return result
来让我们查看一下数据集:
1 2 3 4 5 6 7 8 9 10 11 train_data = load_file(train_data_dir)list ()for i in range (1 ,1800 ,50 ):1 ])for i in range (1 ,37 ):6 ,6 ,i)1 ])
放大其中单张图:
1 2 3 4 plt.imshow(train_data[500 ][1 ])
观察这张图片,我们可以看到字符图片中含有大量的噪声,而噪声会对模型预测结果产生不良影响,因此我们可以在数据预处理时,使用特定的滤波器,消除图片噪声。
简单观察可知,刚才定义字符字典中,键与值都没有重复项,因此可以将字典中的键与值进行反转,以便我们用值查找键(将模型预测结果转换成可读字符)。将字典中的键与值进行反转(例:dict={'A':10,'B':11}反转后得到new_dict={10:'A',11:'B'}
1 2 3 4 char_dict = {'0' :0 ,'1' :1 ,'2' :2 ,'3' :3 ,'4' :4 ,'5' :5 ,'6' :6 ,'7' :7 ,'8' :8 ,'9' :9 ,\'A' :10 ,'B' :11 ,'C' :12 ,'D' :13 ,'E' :14 ,'F' :15 ,'G' :16 ,'H' :17 ,'I' :18 ,'J' :19 ,'K' :20 ,'L' :21 ,'M' :22 ,\'N' :23 ,'O' :24 ,'P' :25 ,'Q' :26 ,'R' :27 ,'S' :28 ,'T' :29 ,'U' :30 ,'V' :31 ,'W' :32 ,'X' :33 ,'Y' :34 ,'Z' :35 }for k, v in char_dict.items()}
然后我们就要定义datasets和dataloader了,
我们需要使用torch.utils.data.Dataset作为父类,定义自己的
datasets,以便规范自己的数据集。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class MyDataset (Dataset ):def __init__ (self, file_name, transforms ):def __getitem__ (self, index ):5 ) return img, char_dict[label[0 ]] def __len__ (self ):return len (self.image_label_arr)
接着我们来定义transform和dataloader:
1 2 3 4 5 6 7 8 9 10 transform = transforms.Compose([transforms.ToPILImage(), 28 ,28 ]), 0.5 ],std=[0.5 ])]) 32 ,shuffle=True )32 ,shuffle=True )
在数据准备好之后,我们需要定义一个简单的卷积神经网络,神经网络的输入是[batchsize,chanel(1),w(28),h(28)],输出是
36 个分类。
我们的神经网络将使用 2 个卷积层搭配 2
个全连接层,这四层的参数设置如下表所示(未标注的直接使用默认参数即可):
conv1: in_chanel=1, out_chanel=10, kernel_size=5conv2: in_chanel=10, out_chanel=20, kernel_size=3fc1: in_feature=2000, out_feature=500fc2: in_feature=500, out_feature=36
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class ConvNet (nn.Module):def __init__ (self ):super ().__init__()1 , 10 , 5 ) 10 , 20 , 3 ) 20 * 10 * 10 , 500 )500 , 36 )def forward (self, x ):0 ) 2 , 2 ) 1 ) 1 )return out
接着,我们来定义模型训练函数,需要实现下面四项操作:
清空梯度
前向传播
计算梯度
更新权重
1 2 3 4 5 6 7 8 9 10 11 12 def train (model, train_loader, optimizer, epoch ):for batch_idx, (data, target) in enumerate (train_loader):if (batch_idx + 1 ) % 10 == 0 :print ('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}' .format (len (data), len (train_loader.dataset),100. * batch_idx / len (train_loader), loss.item()))
再来定义模型测试函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def test (model, test_loader ):eval ()0 0 with torch.no_grad():for data, target in test_loader:'sum' )max (1 , keepdim = True )[1 ]sum ().item()len (test_loader.dataset)print ("\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%) \n" .format (len (test_loader.dataset),100. * correct / len (test_loader.dataset)))
接着是定义模型及优化器,我们将刚刚搭建好的模型结构定义为
model,并选择使用 Adam 优化器。
1 2 model = ConvNet()
终于可以来进行模型训练与测试了。我们可以先设置 epochs 数为
3,进行模型训练,看看模型精度是多少,是否满足验证码识别的要求。如果模型精度不够,你还可以尝试调整
epochs 数,重新进行训练。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 EPOCHS = 3 for epoch in range (1 , EPOCHS + 1 ):1 [288 /1800 (16 %)] Loss: 3.454732 1 [608 /1800 (33 %)] Loss: 2.911864 1 [928 /1800 (51 %)] Loss: 1.960211 1 [1248 /1800 (68 %)] Loss: 0.972134 1 [1568 /1800 (86 %)] Loss: 0.420529 set : Average loss: 0.3054 , Accuracy: 335 /360 (93 %) 2 [288 /1800 (16 %)] Loss: 0.094786 2 [608 /1800 (33 %)] Loss: 0.120601 2 [928 /1800 (51 %)] Loss: 0.073640 2 [1248 /1800 (68 %)] Loss: 0.058856 2 [1568 /1800 (86 %)] Loss: 0.007260 set : Average loss: 0.0139 , Accuracy: 359 /360 (100 %) 3 [288 /1800 (16 %)] Loss: 0.002425 3 [608 /1800 (33 %)] Loss: 0.004629 3 [928 /1800 (51 %)] Loss: 0.005880 3 [1248 /1800 (68 %)] Loss: 0.008300 3 [1568 /1800 (86 %)] Loss: 0.004973 set : Average loss: 0.0039 , Accuracy: 360 /360 (100 %)
训练结果看起来相当不错。那么下面我们自然就是要开始进行验证码识别了,我们需要先导入验证码数据集:
1 verification_code_data = load_file(verification_code_dir)
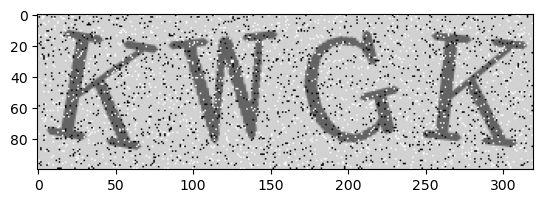
下面我们随便选一张图(图 3),看看这个验证码长什么样。
1 2 3 image = verification_code_data[3 ]
再来看看中值滤波能对验证码图片产生什么效果。
1 2 3 5 )
好,最后来让我们看看识别的实际情况如何:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 list ()list ()for img in verification_code_data:80 ]80 :160 ]160 :240 ]240 :320 ]for one_img in img_list:0 )'Verification_code: ' +'' .join(nums))20 , 20 ))0.2 , hspace=0.5 )for i in range (1 , 11 ):5 ,2 ,i)1 ], fontsize=25 , color='red' )1 ])
相当令人满意的结果。
本次练习我主要是讲解思路,大家看完课程之后要多加练习,自己反复敲打代码,去琢磨其中的一些逻辑关系,要结合我们之前课程中讲过的知识。
还有就是,关于一些第三方库,大家要习惯于自行查看手册。这才是正确的学习打开方式。
好,那这个练习就讲到这里,大家下来记得多练习。