11. BI - 如何在 Python 中进行分词并展示词云
本文为 「茶桁的 AI 秘籍 - BI 篇 第 11 篇」

[TOC]
Hi, 你好。我是茶桁。
之前两节课,咱们学习了基础的数据可视化工具以及决策树的可视化。今天这节课,咱们要看到的是另外一个场景,叫做词云展示。
词云应该所有人都不会陌生,一般什么时候用呢?
2007 年的时候北京的 Google 总部,一进入谷歌大楼就有一个非常震撼的场景,在谷歌的大屏幕里面就放了一个词云的展示。其实现在都知道是词云展示,技术并不是很难。它有个地球,每个地点里面都有个点。无论是在北京,或者在印度、美国的某个城市,每个点里面会呈现一个词云。这个词云告诉你在当前城市的关键词,它的新闻都呈现怎样的一个走势,用一种滚动的形态。你会发现它非常的智能。
Python 词云展示
词云就是对关键词的一种提取,它是文本分析的一种工具。如果我们要做文本分析的话基本上比较常做的就是两种,要么就是英文,要么就是中文。
在做词云展示之前要对文本进行处理,文本特征要去做提取的时候你要以一个单词的粒度。那单词怎么来?在一连串过程中我们要把最原始的那个单词给它提取出来,我们称之为叫做分词。
分词需要用一些分词工具,中文的分词工具最常见的是jieba,英文的话用NLTK。
那为了下面课程大家能跟着一起操作,我说一下这两个工具的安装。jieba比较简单,直接用conda install jieba就可以了,nltk
也是一样的,直接用conda install nltk,只是
nltk
除了安装包之外,需要安装一些必要的数据集,以便特定功能正常工作。在未确定数据集之前,可以先安装常用的子集:
1 | |
词云工具的用了word cloud,配置 word cloud
的时候的话需要输入几个参数:
1 | |
单词的最大的容量,在画布里面呈现多少个单词,画布的长度和宽度。然后再把原始数据喂给画布去生成。生成之后可以把它输出一个 jpg 文件,就可以把这张图呈现出来了。
这个也不难,我带着大家来写一写。
首先我们需要加载包:
1 | |
接着来定义两个方法,一个方法是用于生成词云,还会调用另外一个方法,用于去掉停用词。
为什么要有停用词呢?因为其实在我们做分词的时候,很多的单词大量出现,但是却没有实际意义,比如the, a, of等等。
先来写停用词删除的方法:
1 | |
之后我们再来写一个生成词云的方法:
1 | |
两个方法定义完成之后,我们需要一个数据。要生成词云,肯定不能凭空生成,必须是需要数据才可以的。咱们用一个电影数据,里面包含两个特征,title和genres。
1 | |
之后就是需要将两个特征读取出来,因为是形成词云,主要是要单词词组,两个可以合成一个数据,不需要做区分。
1 | |
最后当然就是将数据喂给我们写好的方法,形成词云:
1 | |

词云图展示出来以后,我们可以看到 Comedy, Drama 和 romance 都比较多。
MarketBasket 购物篮词云分析
简单的了解了词云怎么去完成之后,咱们再来一个案例。拿一个 MarketBasket 购物篮来做词云分析,这个是 kaggle 里的一个数据,下载地址为:https://www.kaggle.com/datasets/dragonheir/basket-optimisation/
这是一个超市的购物小票数据集,我们想要对词云来做个展示,做个探索。做探索就可以判断出来这个超市哪一个商品使用的频率卖的会更好。然后你也可以对这个商品去取一下 TOP10 都有哪些。
加载数据之后,我们来打印一下它的数据看看
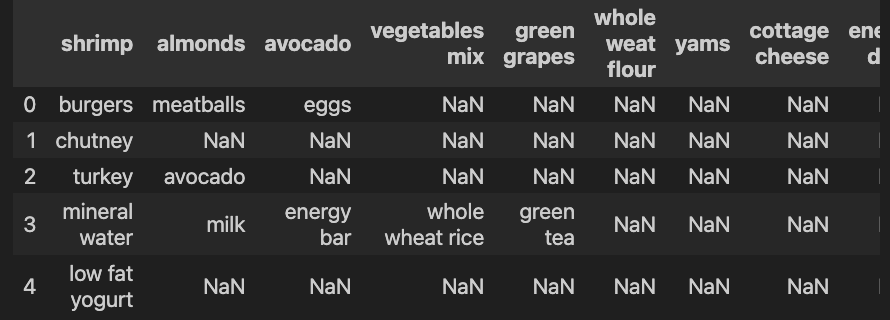
发现这个数据里面还是有很多的空值,不仅如此,那个 head 并不是咱们的特征名,那么我们在读取这样的数据的时候还要处理一下,来重新读取一下数据:
1 | |
在读取数据的时候,我们将 header 设置为了 None, 这样获取的数据,就不会将第一行认为是表头了。
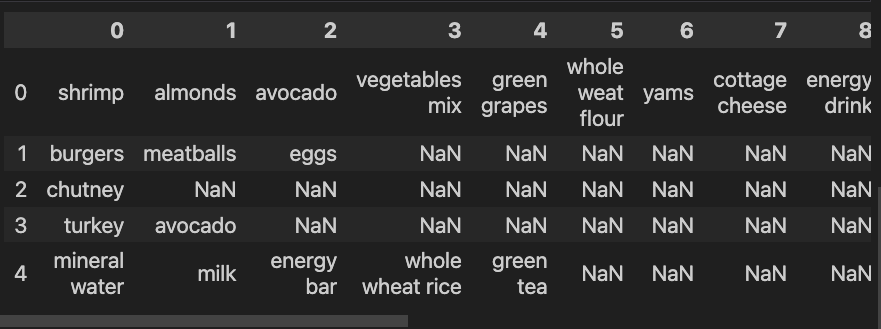
再来看看 values 是怎样的
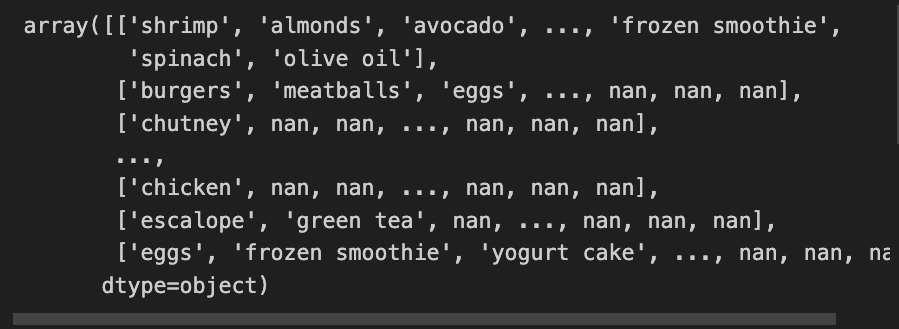
确实,很多的nan。那在做词云之前,我们需要将数据先处理一下,反正要将所有的字符都放在一个变量里,在放入之前,先来判断一下它是否为nan就好了:
1 | |
最后,让我们将之前定义过的生成词云的方法调用一下,将本次我们处理好的数据喂给它:
1 | |

这样,就生成这次数据的一个词云图片。是不是还蛮简单的?其实重点还是在处理数据那里,第一个 values 看到 dataframe 里面所有的数值,这个数值因为它有两个 list,所以写了两层分循环。有些值为空,就判断一下它是不是不为空,如果不为空把它拼接到一起。这样就把所有的文本读出来。读完以后再去用它来生成词云,就可以得到一个展示。
11. BI - 如何在 Python 中进行分词并展示词云

