12. BI - 可视化在项目蒸汽量预测的过程及应用
本文为 「茶桁的 AI 秘籍 - BI 篇 第 12 篇」

[TOC]
Hi, 你好。我是茶桁。
我们今天继续来看数据可视化做数据探索,今天我们还是来看相关项目。来看看可视化 EDA 在项目中的应用。
工业蒸汽量预测
接下来这个项目,是在阿里天池上的一个工业蒸汽量的预测项目。
首先我们来看一下一些前提知识点。我们知道,火力发点的原理是:燃料加热水 -> 生成蒸汽 -> 推动汽轮机旋转 -> 带动发电机旋转 -> 产生电能。

在这个过程中,影响发电效率的核心是锅炉的燃烧效率。影响锅炉燃烧效率的主要因素包括:
- 锅炉的可调参数,如燃烧给量,一二次风,引风,返料风,给水水量。
- 锅炉的工况,比如锅炉床温、床压,炉膛温度、压力,过热器的温度等。
很明显,我们要通过调节的锅炉的参数以及锅炉工况的参数来去预测它的蒸气量会是多少。
这个项目的训练集为zhengqi_train.txt,测试集为zhengqi_test.txt,数据都是脱敏后的传感器采集数据(采集频率为分钟级)。训练集大概
38 个字段。
先大概来看一下这个数据,现在要做的事情是根据锅炉的情况来预测它的蒸汽量,蒸汽量这个特征是在最后,也就是要去预测target这个值。
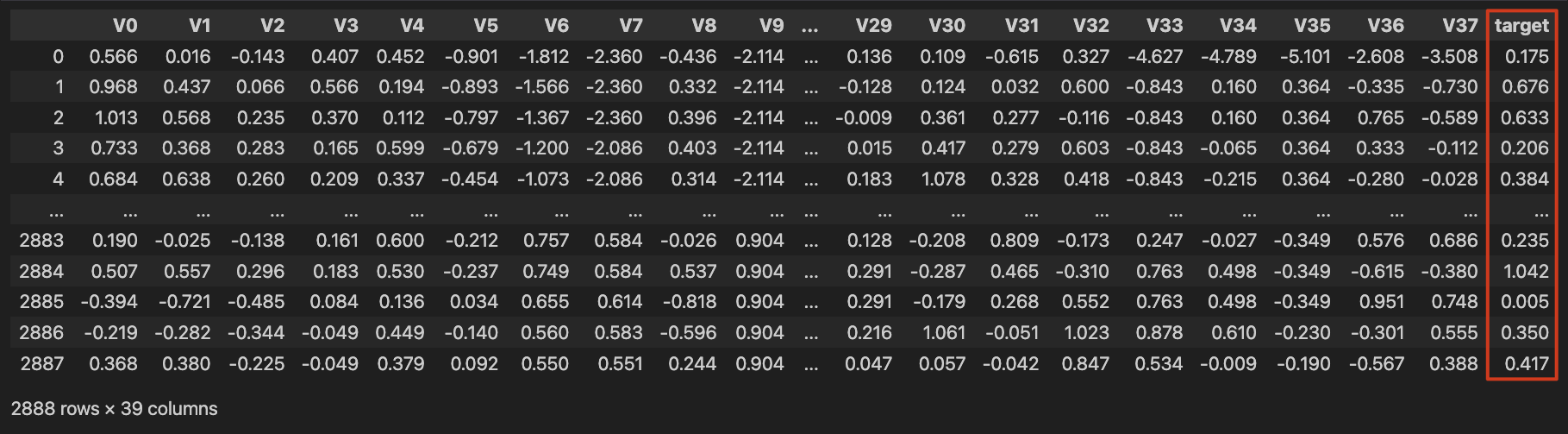
今天主要不是要做建模,而是去看一看数据的分析以及可视化。看看能帮我们得到怎样的一个结论。对于我们预测来说也是有一定的帮助的,至少前期的数据探索是很有帮助。
当我们看到这样一个数据之后,思路会是怎样的?怎么去做这个可视化的分析?
首先,我们需要将数据加载出来,每一个特征都可以做一个异常值的处理。还记得咱们之前将图形可视化的时候,可以用箱线图来找出异常值的情况。
首先,我们还是 Download 数据,在你的命令行内先进入一个目录,然后进行下载:
1 | |
下载之后进行加载,直接使用 read_csv 就可以
1 | |
因为读取之后的数据格式不对,会发现有很多的\t
所以我们需要在读取数据的后面加上一个sep='\t'。这样,就不是以逗号被分割了,默认是以逗号。现在的数据因为是\t,所以就写成
separator 等于\t。
这个数据基本都是数值类型,我们想要看它的特征可以用 describe 来做判断。这样就把这 38 个特征的统计量一目了然了,画箱线图就拿它来画的。
1 | |
接下来当然是要导入 matplotlib 和 seaborn,用于后面的图形展示。第一张图我们要看一下 V0 和 target 之间的一些关系,那先用箱线图呈现。
1 | |
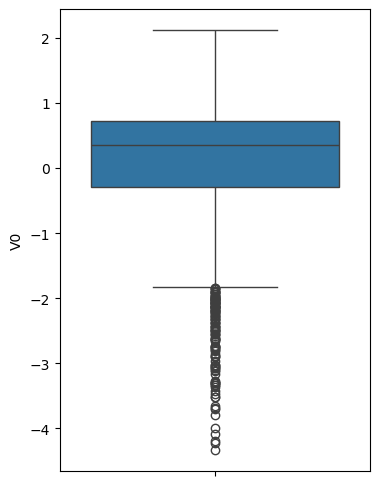
除了 V0 还有其它的列,列数有多少呢?我们可以看一下 columns,用一个 len 方法来查看它到底有多少个。
1 | |
一共是有 39 列。我们直接用 columns 做个遍历。每一个要设置 index,一共 39 个特征,你的画布可以设置为多少?比如说我们设成 \(5 * 8\),这是 40 个特征。我们就尝试这样设置下:
1 | |
我们首先用 cols 将 train.columns 拿到,然后对它进行遍历,其中 i
设置从 0 开始,作为它的下标。一开始,就需要进行+1,
然后按照之前我们想好的设置,subplot设置为5, 8,
i 就是当前那个图。接着,我们用boxplot将当前的 col
绘制出来。
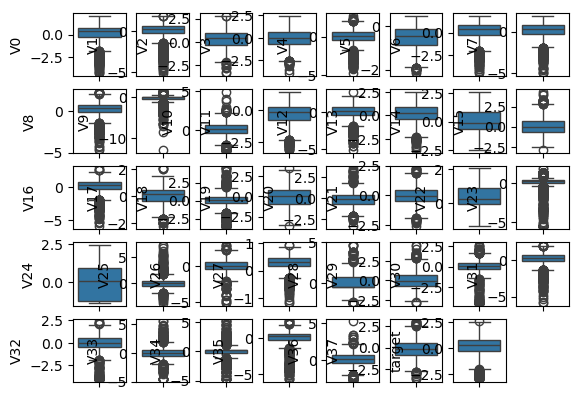
不过这样明显看不出所以然出来,我们需要将图像设置的大一点。这个太密集了。所以再设置一下figure:
1 | |
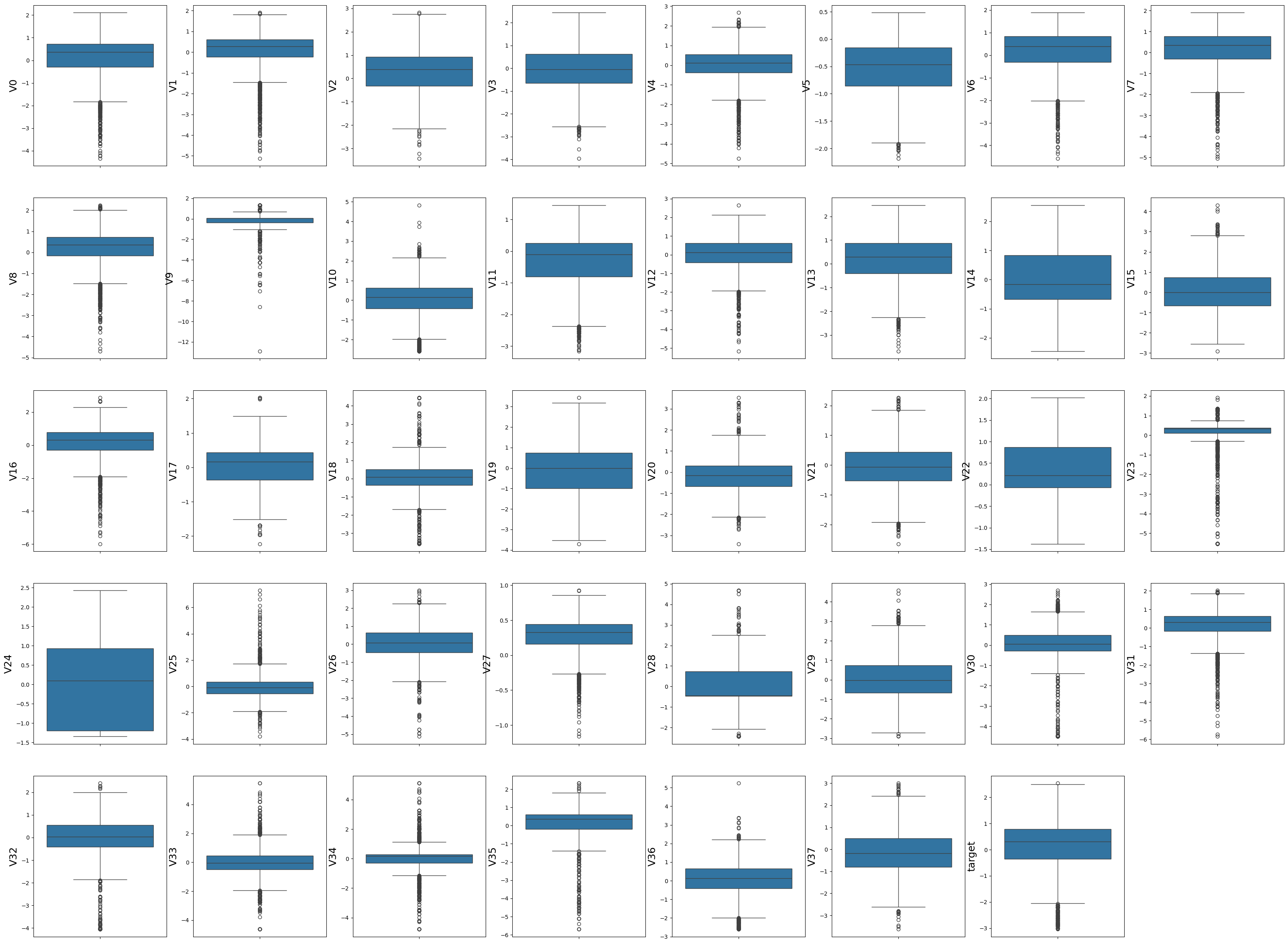
这样就清晰很多,V0 是有异常值的,似乎很多都有异常值。我们来找找看哪些没有,大部分都有。V14 没有,V22 没有。这就是查看异常值的检测。
接下来,咱们可以看看直方图和概率密度图。它是用特征在训练集里面和测试集里面同时做一个呈现。
跟刚才的逻辑一样,先把画布大小做一个设置,
然后循环的时候去掉最后一个目标特征target:
1 | |
最后是将train和test两个数据集都绘制了出来,赋予不同的颜色
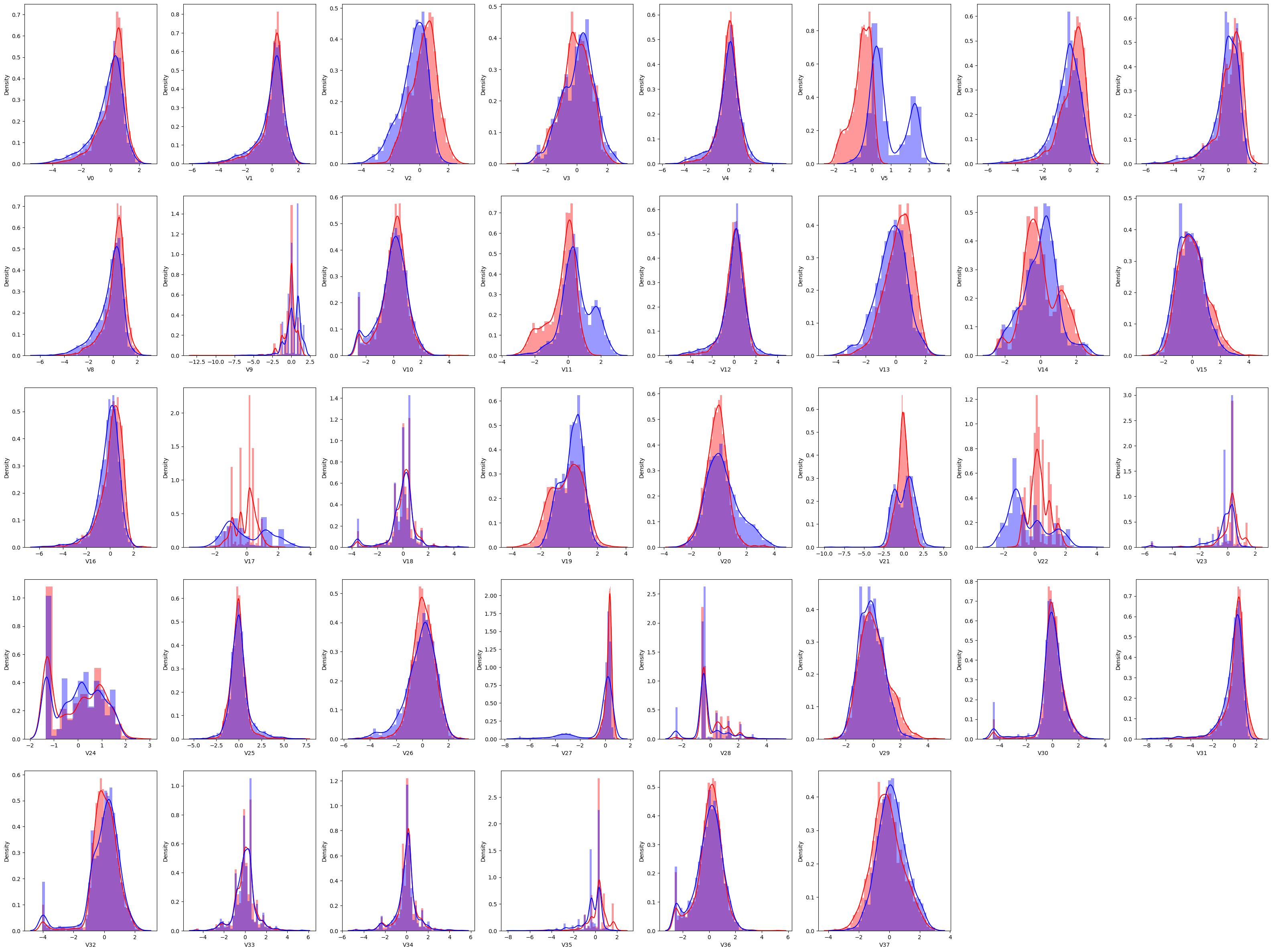
之前我们的课程中有说到 distplot 这个方法,默认是将直方图和 kde 结合在一起。其实我们使用 kde 会显得更清爽一点,只要将 distplot 换成 kdeplot 方法就行了。
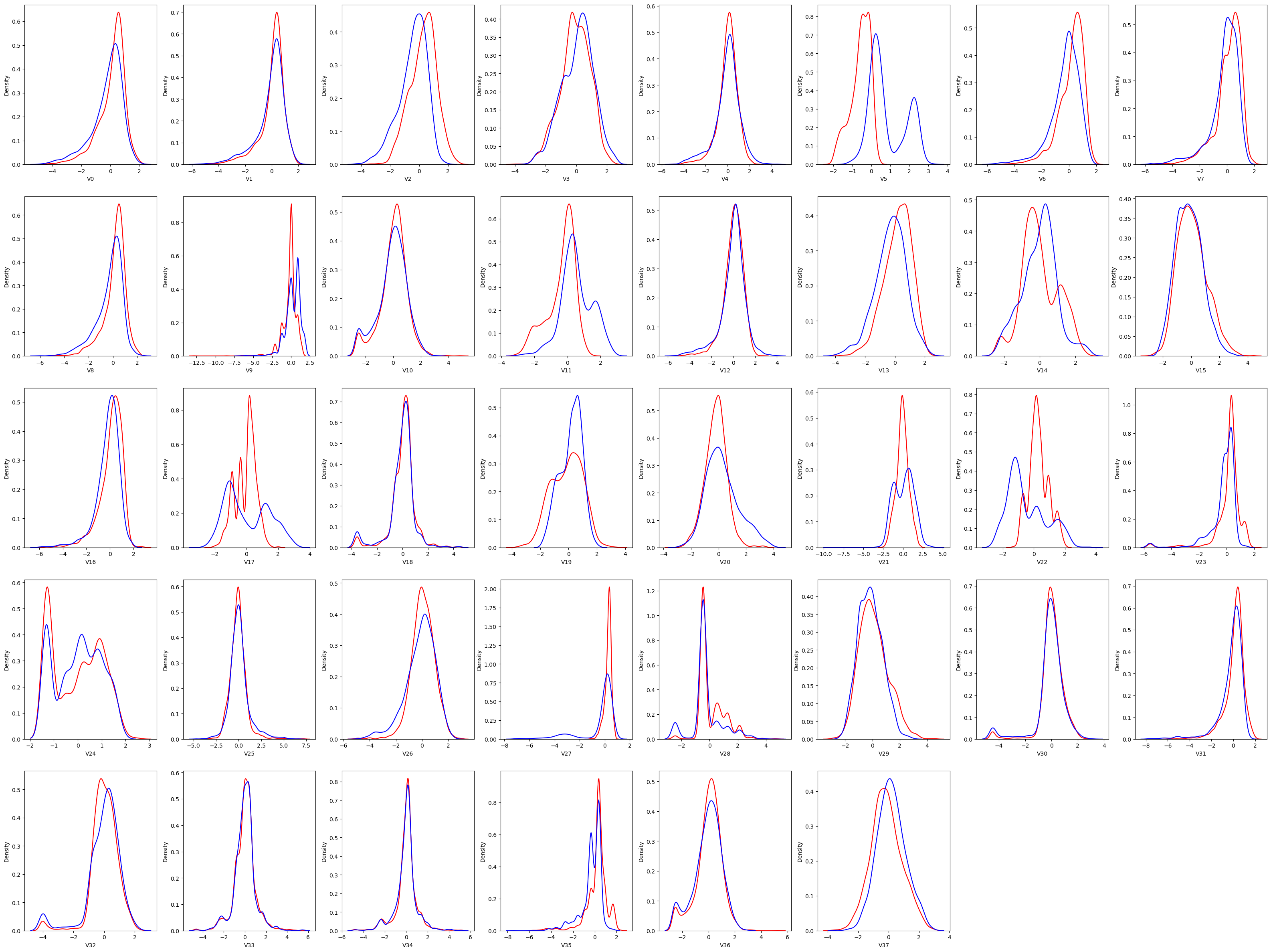
这样看起来虽然清爽了,但是总觉得还缺点什么,其实可以将阴影加上就明显很多。我们可以在方法名后面设置 shade 为 True
1 | |
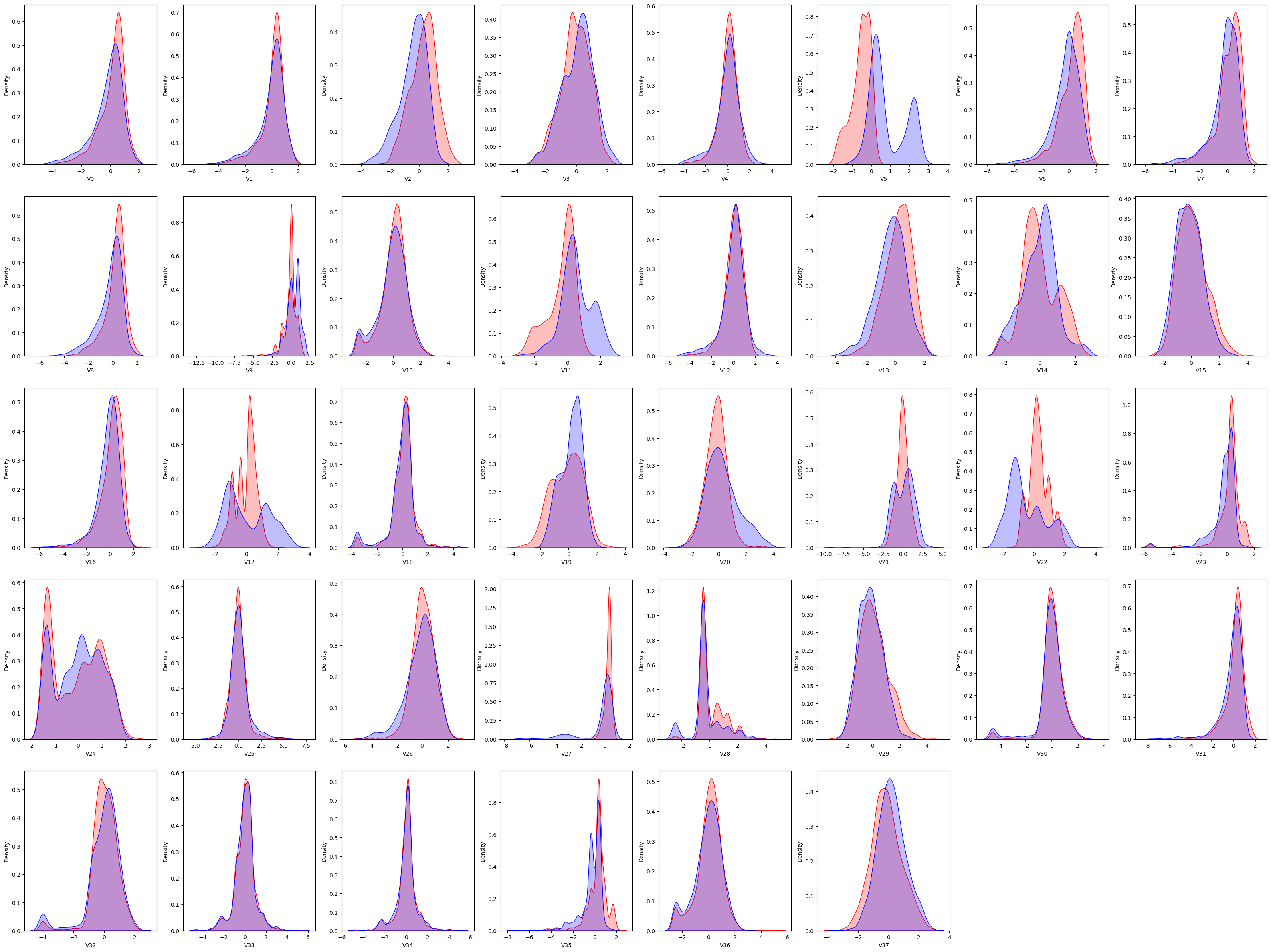
因为 kde 比较平滑,它没有这么多的像乐高一样的方块。这个就看起来比较直观一点。
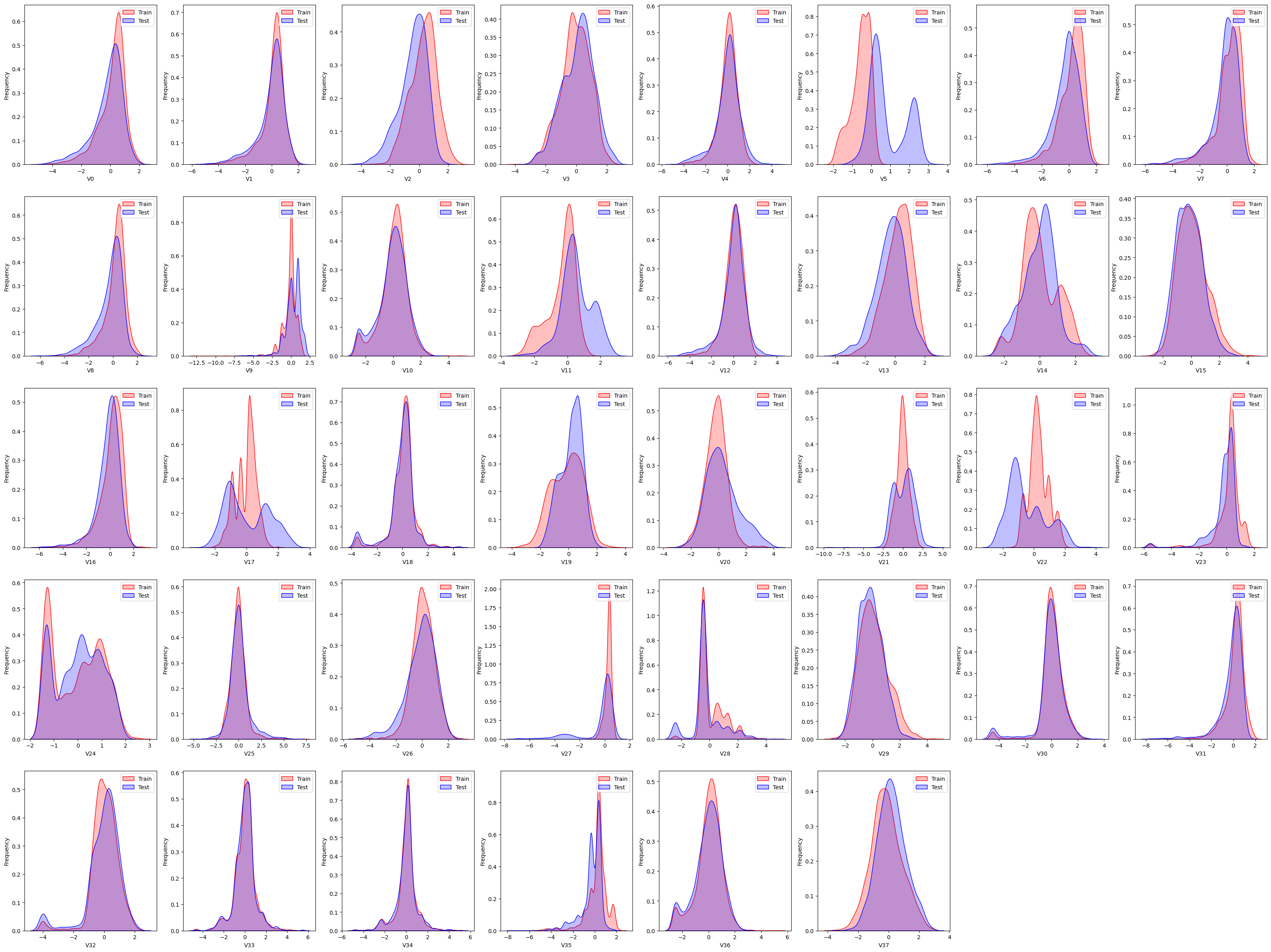
看 kde
能发现哪些问题呢?我们现在要找那种测试集和训练集不太一致的,可以把它去掉。比如说第一个,我们认为应该是一样的。可以把这张图里面的轴向上的
label
也给它呈现出来,因为一会儿要数个数,不如直接给它标记出来。顺便,我们之前设置了图例label但是没有正常显示,也一起来解决一下。
1 | |
set 一下 x 和 y 轴的
label,并且加上plt.legend()让图例正常显示。
现在我们可以一起来看看,有哪些是不太一样的?前几个虽然有一点差别但实际上还是可以判断的,如果这个蓝色和红色差了几个位置可以给它做一个调整,给他做一个特征变换,用新的特征代替原有的特征,这样预测起来可能会更准一点。
V5 差别比较大,所以 V5 有可能不太行,好,咱们先记住一个。往后看,V9 差别也是比较大。咱们就需要去这张图上去找。5、9、11、17、21、22、28,这几个图中可以看到,这些特征在训练集和测试集中的分布差别就比较大的。这一步其实没有一个完全的标准,看你自己感觉上哪个差别比较大,可以给它去掉。
去掉的目的是降维,不是说要得到更精确的方法。如果更精确的话,你不去可能效果会更好。
现在可以给它写个方法来去掉这几个特征,先来个列表将特征名放进去:
1 | |
就是这些 column,我们写一个 list 放进来,这样稍后数据处理会更加少一点,不是所有的数据都会有。
1 | |
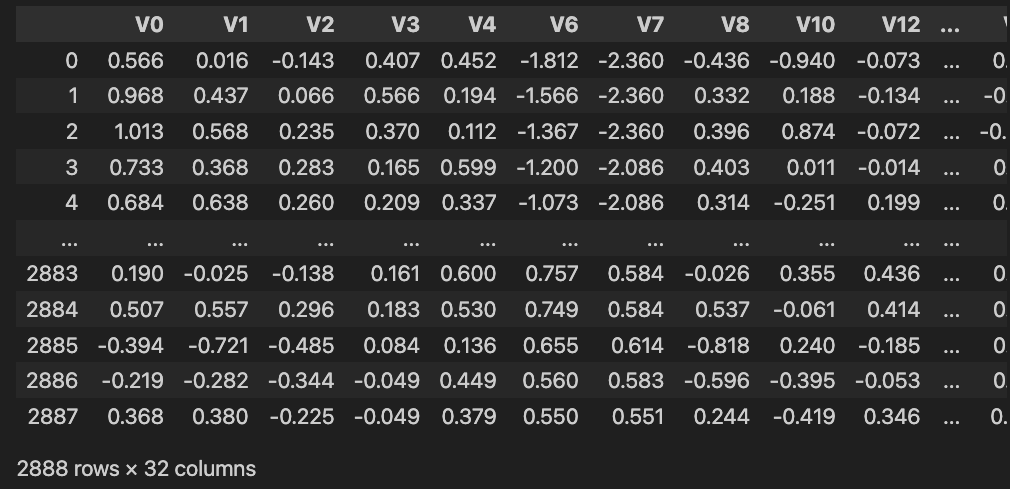
这样我们处理之后,就剩下 32 个特征。test 也是一样要进行处理。
通过训练集和测试集的分布我们找到了一些分布不太一样的给它去掉,剩下的这些特征哪些跟 target 之间的相关性是比较高的?
接下来看相关性的话,就要用到regplot,
方法还是类似的。设置一张大图,然后将特征进行循环,把数据扔进去以后进行绘制:
这里为了让相关性更明显一点,我们将线设置成不同的颜色:
1 | |
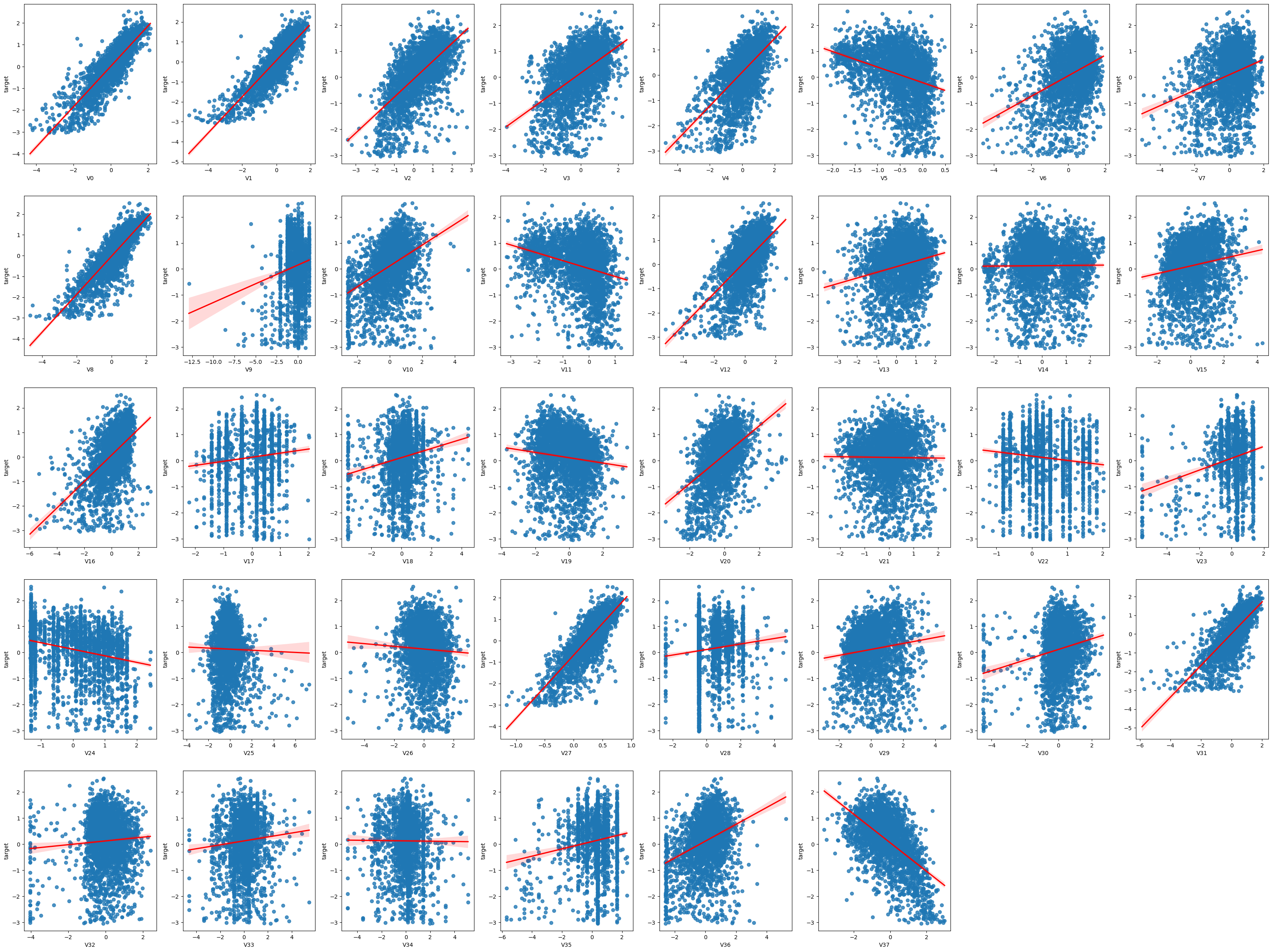
这样可以知道它的相关性,有些相关性是比较好的,有些相关性是不太好的,这张图上就可以一目了然。
也可以专门做相关性的系数,这次我们使用之前去掉特征之后的train2来做一个相关性系数的呈现,绘制它的热力图帮你判断。
1 | |
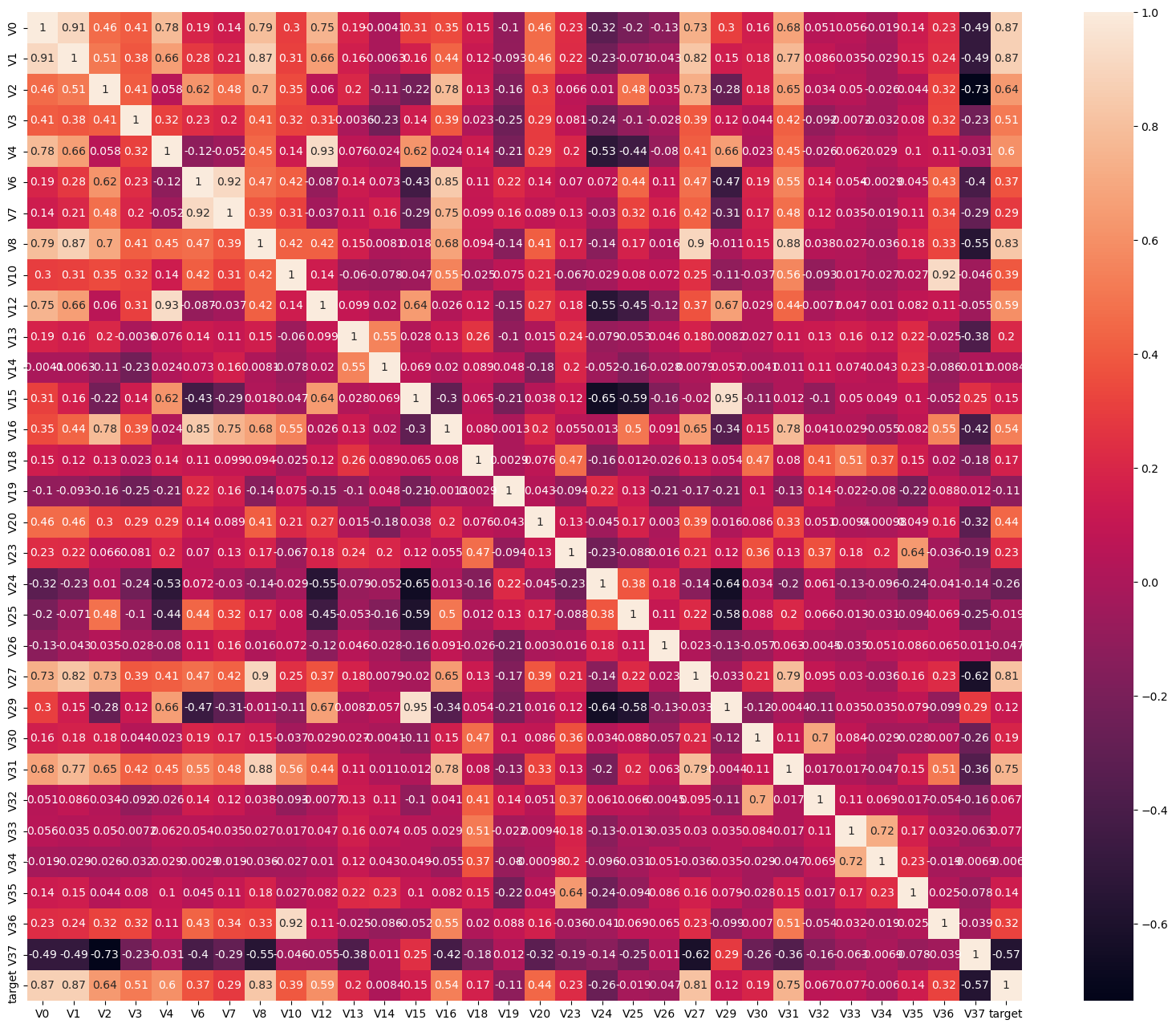
现在咱们用了热力图把相关性系数呈现出来,系数非常多,因为维度很多。即使咱们之前已经去掉一些特征,比如说 28 就去掉了,22 也去掉了,但是这个维度还是很多。那该怎么看呢?我们可以筛选出来重要的特征,g 大于 0.5 的,绝对值大于 0.5 的,我们要找跟 traget 的之间相关性大于 0.5 的。
我们首先设置一下 threshold, 然后将之前 train2 里的相关性系数都存下来
1 | |
然后需要筛选一下保存的这个系数里,target的系数,并且它需要是大于
threshold 的
1 | |
我们只需要它的 index,来喂给我们新建立的一个 filter
1 | |
这样,我们就拿到了相关性系数比较高的一些特征。咱们把这些特征再去做一个呈现的可视化。
1 | |
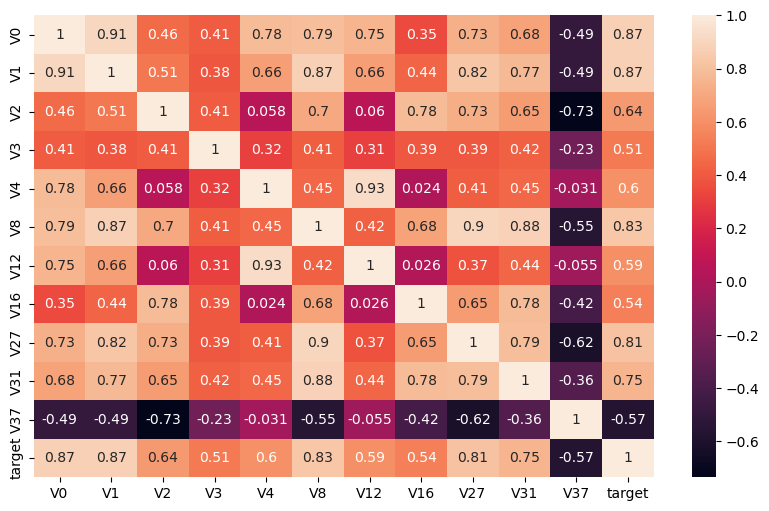
刚才是一张很大的图,看起来比较密密麻麻。那现在找出来那些最关键的特征,看这张图是不是比较清爽一点了?
这张图里都是和 target 相关性比较高的,要么是正相关比较大,要么是负相关比较大。这就是我们筛出来的特征。
这个做完之后,咱们前期的数据探索基本就差不多了。现在咱们可以快速的来做一版预测。
咱们要预测的是它的蒸汽量,咱们一起思考下,可以用什么样的方法?是不是可以建一个回归模型?简单一点的模型用线性回归。所以我们从 sklearn 里面用 liner_model, 导入 LinearRegression, 回归模型。
然后,因为需要用到的是线性回归,肯定这样将数据喂给模型是不行的,需要先做一个归一化处理,所以还需要导入一个StandardScaler,当然,你用其他的
Scaler 也可以
1 | |
需要的包咱们有了,当然第一步是需要训练集中的target去掉,做一个新的特征列表:
1 | |
接下来,咱们就需要将数据做一个处理,做一个归一化处理,测试集和数据集都要做。做的时候注意,train 训练集我们需要 fit,测试集就不需要了:
1 | |
接着就是创建模型,引用模型对数据进行训练:
1 | |
再然后就是预测了
1 | |
咱们将这个预测结果保存一下,存成 DataFrame 格式,整个数据是不需要表头的,我们可以设置 header 为 None
1 | |
看看这个baseline.txt
发现里面是有一些负数的,我们需要回过头去看一下咱们的源数据 train, 观察一下它里面是不是也有负数,原来那个数据的 target 如果没有负数那你预测出来负数可能也不太对。
1 | |
好,也是有负数的。那说明咱们预测的没有问题。这样,就把这个例子给大家写完了。这个模型只是做简化版,并没有说一定要去做一个精确版的。
这个例子就把一个蒸汽量的预测问题给大家写完了,这章重点看的是前面的可视化的过程,而不是训练。训练之前给大家讲了太多了。可视化过程可以让你对特征会比较熟悉和了解,有没有异常值、分布是不是一致,你看到它就会有后续的一些想法,idea 就会产生。哪个特征是比较关键的,这些特征之间的相关性系数是如何,重要特征,最重要的那几个是哪些等等就可以拿出来了。
如果你想要做更精确的预测的话可以用复杂模型,比如说你可以用 XGBoost,用 LightGBM,树模型都是一些非线性模型。它的模型就会比较复杂。
咱们上面这个数据也没有对异常值做处理,如果你想要 drop 异常值的话也是可以做一些处理的。但是异常值其实不是所有的情况下都一定需要 drop,它只是给你判断出来有异常值。我们需要观察测试集里面有没有异常值,如果你的测试集里面有异常值的话那么就需要在训练集里有异常值。有点像它的分布情况是一样的。所以异常值只是给你提醒,说这样的数据跟其他的分布之间差别比较大而已。很多时候还是要看测试集里面有没有,要去做一个判断才可以。
咱们花了三节课的时间来做数据可视化探索,方便你对数据的异常值检测,数据的一些特征的情况做一些了解。这样你对数据的字段就更加的清楚。
咱们讲了几个图形,这其中饼图其实可以用直方图来呈现,领导有可能会看,但一般来说我们自己也要去做分析,打比赛的时候,做项目的时候用的更多的是散点图,折线图和直方图。
好,预告一下内容,下一节课,咱们会进行一些产品型的一些内容。那咱们下节课再见。
12. BI - 可视化在项目蒸汽量预测的过程及应用

